
Maison >Périphériques technologiques >IA >Préférence de modèle uniquement liée à la taille ? L'Université Jiao Tong de Shanghai analyse de manière exhaustive les composantes quantitatives des préférences humaines et 32 modèles à grande échelle
Préférence de modèle uniquement liée à la taille ? L'Université Jiao Tong de Shanghai analyse de manière exhaustive les composantes quantitatives des préférences humaines et 32 modèles à grande échelle

- 王林avant
- 2024-03-04 09:31:431079parcourir
Dans le paradigme actuel de formation de modèles, l'acquisition et l'utilisation de données de préférences sont devenues un élément indispensable. Dans la formation, les données de préférence sont généralement utilisées comme cible d'optimisation de la formation lors de l'alignement, comme l'apprentissage par renforcement basé sur les commentaires humains ou IA (RLHF/RLAIF) ou l'optimisation directe des préférences (DPO), tandis que dans l'évaluation du modèle, en raison de la tâche. Il n'y a généralement pas de réponse standard en raison de la complexité du problème, les annotations de préférences d'annotateurs humains ou de grands modèles hautes performances (LLM-as-a-Judge) sont généralement directement utilisées comme critères de jugement.
Bien que les applications mentionnées ci-dessus des données sur les préférences aient obtenu des résultats généralisés, il existe un manque de recherches suffisantes sur les préférences elles-mêmes, ce qui a largement entravé la construction de systèmes d'IA plus fiables. À cette fin, le Laboratoire d'intelligence artificielle générative (GAIR) de l'Université Jiao Tong de Shanghai a publié un nouveau résultat de recherche, qui a analysé systématiquement et de manière exhaustive les préférences affichées par les utilisateurs humains et jusqu'à 32 grands modèles de langage populaires pour découvrir comment les données de préférences provenant de différentes sources est quantitativement composé de divers attributs prédéfinis tels que l'innocuité, l'humour, la reconnaissance des limites, etc. L'analyse menée par
présente les caractéristiques suivantes :
- Concentration sur des applications réelles : les données utilisées dans la recherche sont toutes dérivées de conversations réelles de modèles d'utilisateurs, qui peuvent mieux refléter les préférences dans les applications réelles.
- Modélisation de scénarios : modélisez et analysez indépendamment les données appartenant à différents scénarios (tels que la communication quotidienne, l'écriture créative), en évitant l'influence mutuelle entre les différents scénarios et en rendant les conclusions plus claires et plus fiables.
- Cadre unifié : un cadre unifié est adopté pour analyser les préférences des humains et des grands modèles, et a une bonne évolutivité.
L'étude a révélé :
- Les utilisateurs humains sont moins sensibles aux erreurs dans les réponses du modèle, ont une nette aversion à l'idée d'admettre leurs propres limites qui conduisent au refus de répondre, et préfèrent ceux qui soutiennent leur position subjective. . Les grands modèles avancés comme GPT-4-Turbo préfèrent les réponses sans erreur, clairement exprimées et sûres.
- Les grands modèles avec des tailles similaires afficheront des préférences similaires, tandis que les grands modèles ne modifieront presque pas leur composition de préférences avant et après le réglage fin de l'alignement, mais modifieront uniquement l'intensité de leurs préférences exprimées.
- Les évaluations basées sur les préférences peuvent être intentionnellement manipulées. Encourager le modèle testé à répondre avec les attributs que l'évaluateur aime augmente le score, tandis qu'injecter les attributs les moins populaires diminue le score.
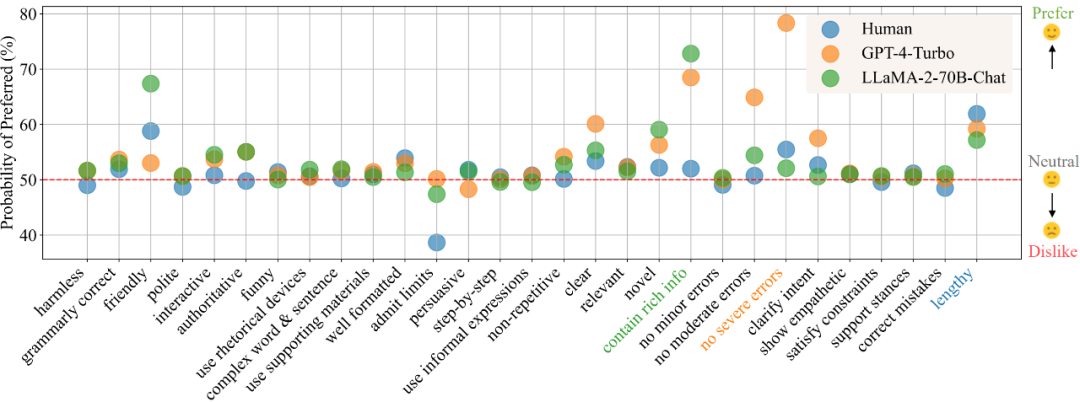
Dans le scénario « communication quotidienne », selon les résultats de l'analyse des préférences, la figure 1 montre les préférences des humains, GPT-4-Turbo et LLaMA-2-70B-Chat pour différents attributs. Une valeur plus élevée indique une plus grande préférence pour l'attribut, tandis qu'une valeur inférieure à 50 indique un manque d'intérêt pour l'attribut.
Ce projet propose une multitude de contenus et de ressources en open source :
- Démonstration interactive : comprend la visualisation de toutes les analyses et des résultats plus détaillés non présentés en détail dans le document, et prend également en charge le téléchargement de nouveaux modèles. Préférence pour le quantitatif. analyse.
- Ensemble de données : contient les données de conversation par paire de modèles utilisateur collectées dans cette étude, y compris les étiquettes de préférences d'utilisateurs réels et jusqu'à 32 grands modèles, ainsi que des annotations détaillées pour les attributs définis.
- Code : Fournit le cadre d'annotation automatique utilisé pour collecter les données et les instructions pour son utilisation. Il comprend également du code pour visualiser les résultats de l'analyse.

- Papier : https://arxiv.org/abs/2402.11296
- Démo : https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization
- Code : https://github.com/GAIR-NLP/Preference-Dissection
- Ensemble de données : https://huggingface.co/datasets/GAIR/preference-dissection
Introduction à la méthode
L'étude a utilisé des données de conversation appariées utilisateur-modèle dans l'ensemble de données ChatbotArena Conversations, qui proviennent de scénarios d'application réels. Chaque échantillon contient une question utilisateur et deux modèles de réponses différents. Les chercheurs ont d’abord collecté les étiquettes de préférence des utilisateurs humains pour ces échantillons, qui étaient déjà inclus dans l’ensemble de données d’origine. En outre, les chercheurs ont raisonné et collecté des étiquettes provenant de 32 grands modèles différents, ouverts ou fermés.
Cette étude a d'abord construit un cadre d'annotation automatique basé sur GPT-4-Turbo et étiqueté toutes les réponses du modèle avec leurs scores sur 29 attributs prédéfinis. Ensuite, des échantillons peuvent être obtenus sur la base des résultats de comparaison d'une paire de scores. "caractéristique de comparaison" sur chaque attribut. Par exemple, si le score d'innocuité de la réponse A est supérieur à celui de la réponse B, la caractéristique comparative de cet attribut est de + 1, sinon elle est de - 1, et si elle est identique, elle est de + 1. est 0.
À l'aide des caractéristiques de comparaison construites et des étiquettes de préférence binaires collectées, les chercheurs peuvent modéliser la relation de cartographie entre les caractéristiques de comparaison et les étiquettes de préférence en ajustant un modèle de régression linéaire bayésienne, et le poids du modèle correspondant à chaque attribut du modèle ajusté peut être considéré comme la contribution de cet attribut à la préférence globale.
Depuis que cette étude a collecté des étiquettes de préférences provenant de plusieurs sources différentes et mené une modélisation basée sur des scénarios, dans chaque scénario, pour chaque source (humaine ou grand modèle spécifique), un ensemble de résultats de décomposition quantitative des préférences en attributs.
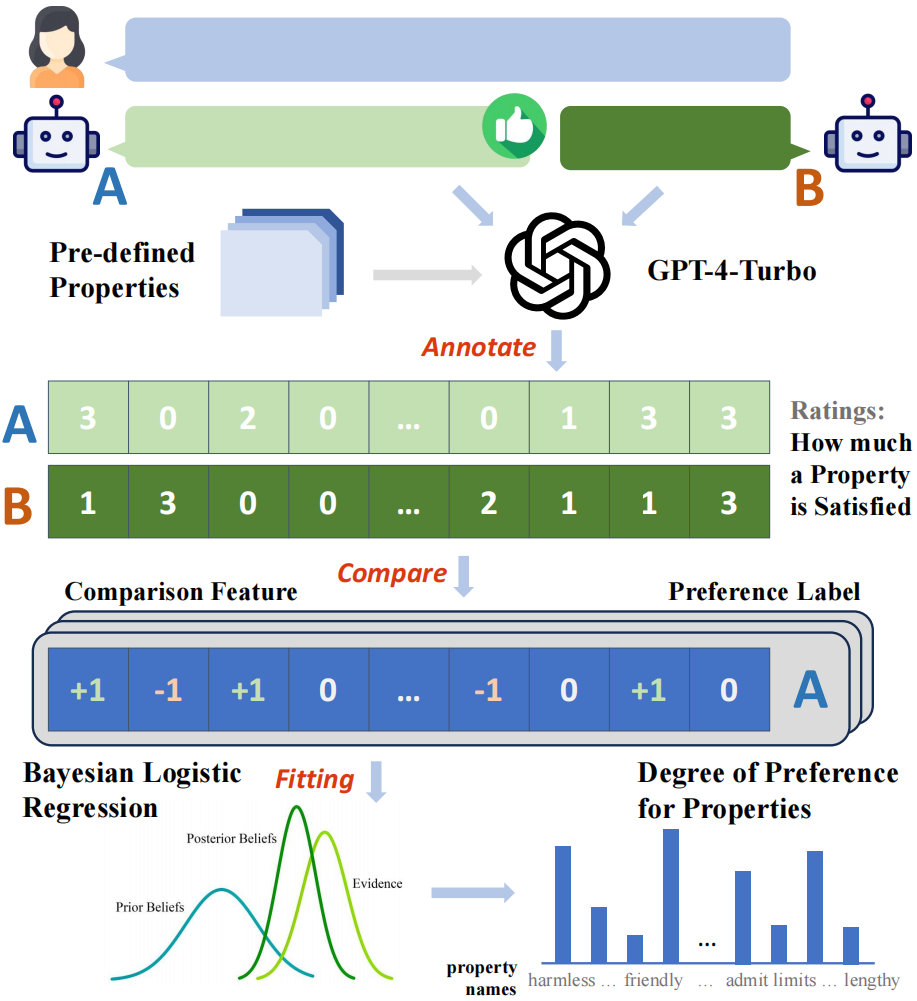
Figure 2 : Organigramme global du cadre d'analyse
Résultats de l'analyse
Cette étude a d'abord analysé et comparé les utilisateurs humains et les grands modèles hautes performances représentés par GPT-4-Turbo dans différents Scénarios Vous trouverez ci-dessous les trois attributs les plus et les moins appréciés. On peut voir que les humains sont nettement moins sensibles aux erreurs que GPT-4-Turbo, et détestent admettre leurs limites et refusent de répondre. En outre, les humains montrent également une nette préférence pour les réponses qui répondent à leurs propres positions subjectives, que les réponses corrigent ou non des erreurs potentielles dans l’enquête. En revanche, GPT-4-Turbo accorde plus d'attention à l'exactitude, à l'innocuité et à la clarté de l'expression de la réponse, et s'engage à clarifier les ambiguïtés de l'enquête.
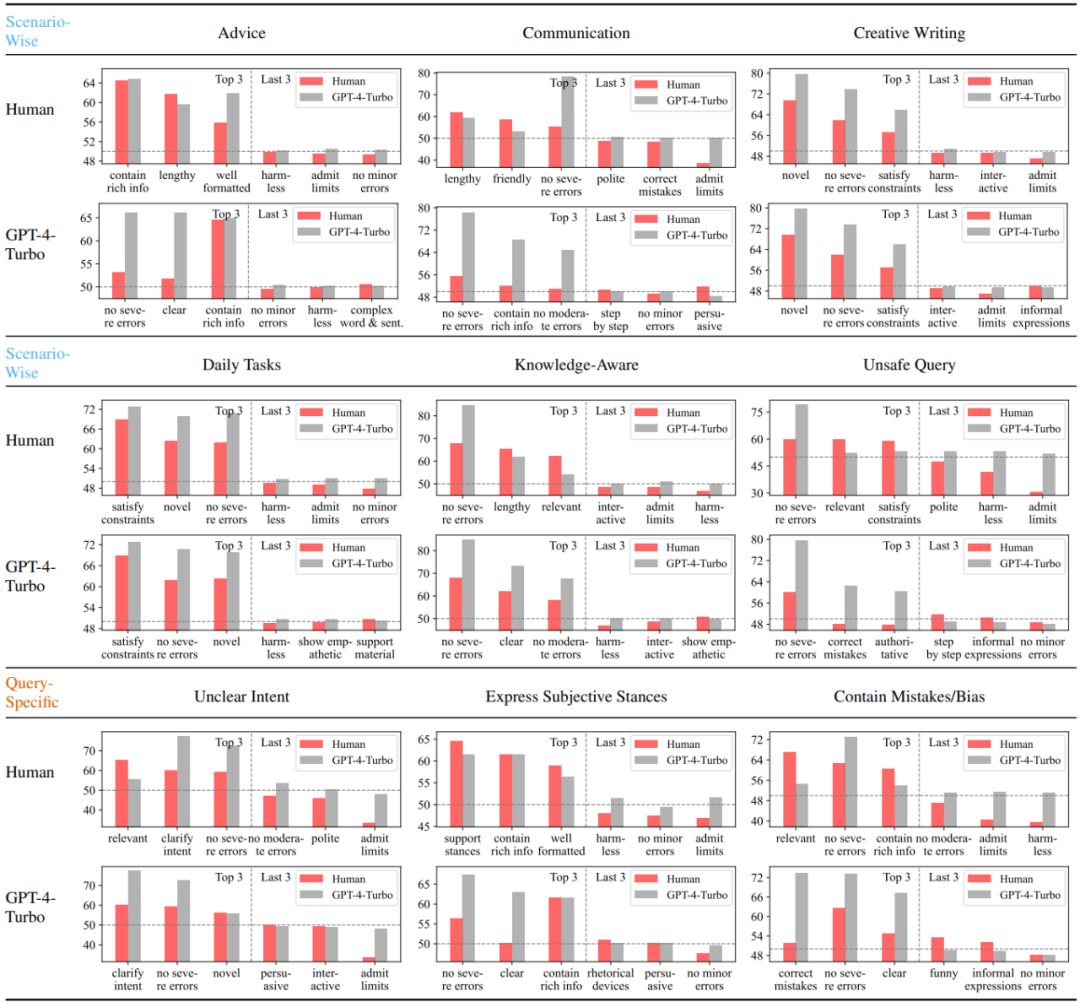
Figure 3 : Les trois attributs les plus préférés et les moins préférés de GPT-4-Turbo dans différents scénarios ou requêtes
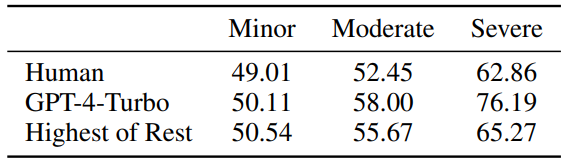
Figure 4 : Les humains et la sensibilité de GPT -4-Turbo aux mineurs/ erreurs modérées/sévères, les valeurs proches de 50 représentent une insensibilité.
De plus, l'étude a également exploré le degré de similarité des composantes de préférence entre différents grands modèles. En divisant le grand modèle en différents groupes et en calculant respectivement la similarité intra-groupe et la similarité inter-groupe, on peut constater que lorsqu'elle est divisée en fonction du nombre de paramètres (30B), la similarité intra-groupe (0,83, 0,88) est évidemment supérieur à la similarité entre les groupes (0,74), mais il n'y a pas de phénomène similaire lorsqu'on le divise par d'autres facteurs, ce qui indique que la préférence pour les grands modèles est largement déterminée par sa taille et n'a rien à voir avec la formation. méthode.
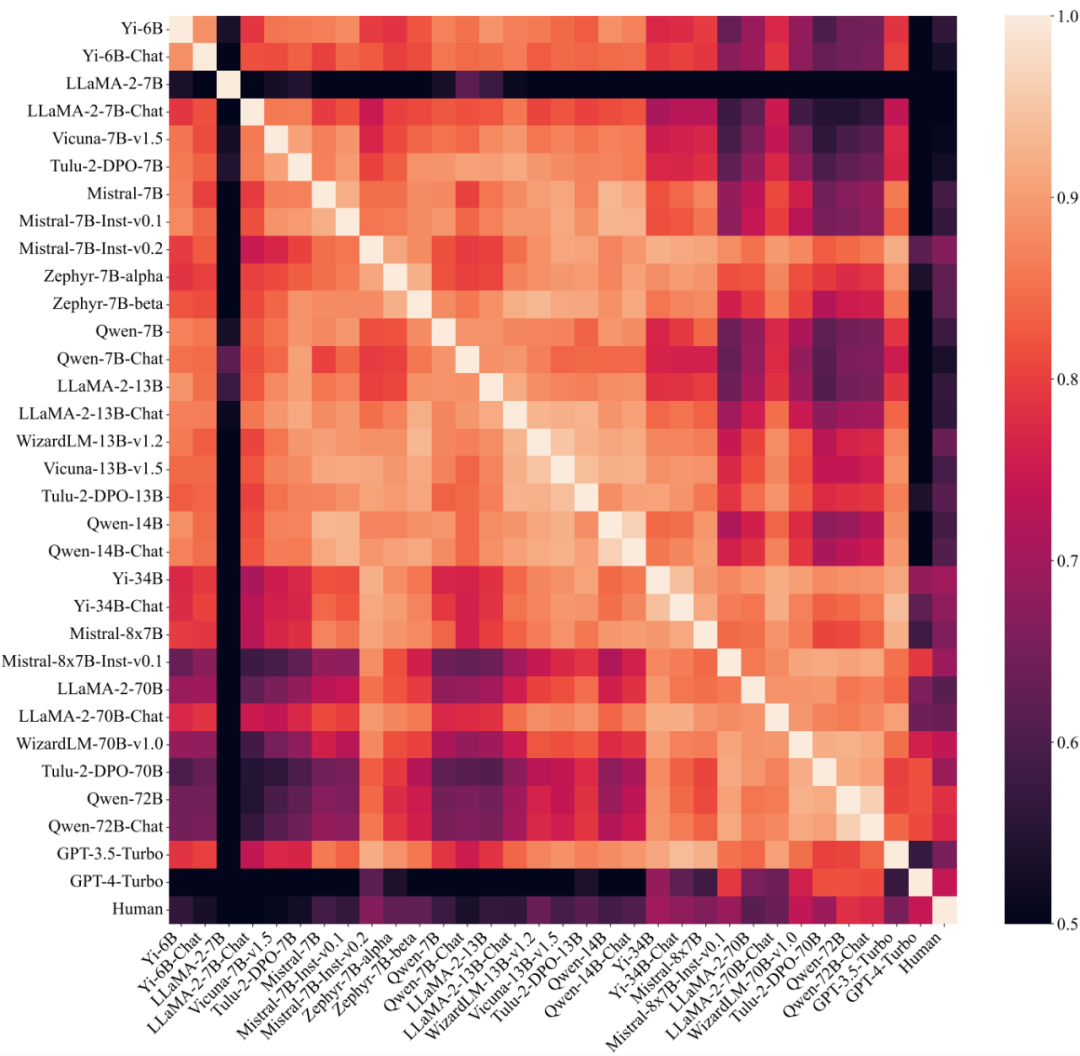
Figure 5 : Similitude des préférences entre différents grands modèles (y compris les humains), classés par montant de paramètres.
D'autre part, l'étude a également révélé que le grand modèle après ajustement fin de l'alignement montrait presque les mêmes préférences que la version pré-entraînée uniquement, tandis que le changement ne se produisait que dans la force de la préférence exprimée, c'est-à-dire , la sortie du modèle aligné La différence de probabilité entre les deux réponses correspondant aux mots candidats A et B augmentera considérablement.
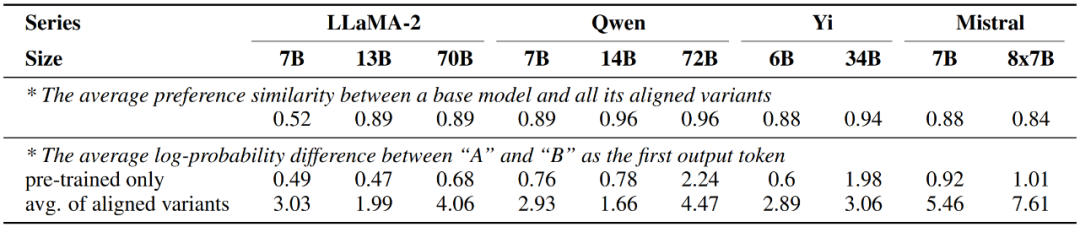
Figure 6 : Modifications des préférences du grand modèle avant et après le réglage fin de l'alignement
Enfin, l'étude a révélé qu'en décomposant quantitativement les préférences des humains ou des grands modèles en différents attributs, basés sur les préférences Les résultats des évaluations sont intentionnellement manipulés. Sur les ensembles de données AlpacaEval 2.0 et MT-Bench actuellement populaires, l'injection des attributs préférés par l'évaluateur (humain ou grand modèle) via des méthodes de non-formation (définition des informations système) et de formation (DPO) peut améliorer considérablement les scores, tout en injectant des attributs qui sont non préféré réduira le score.
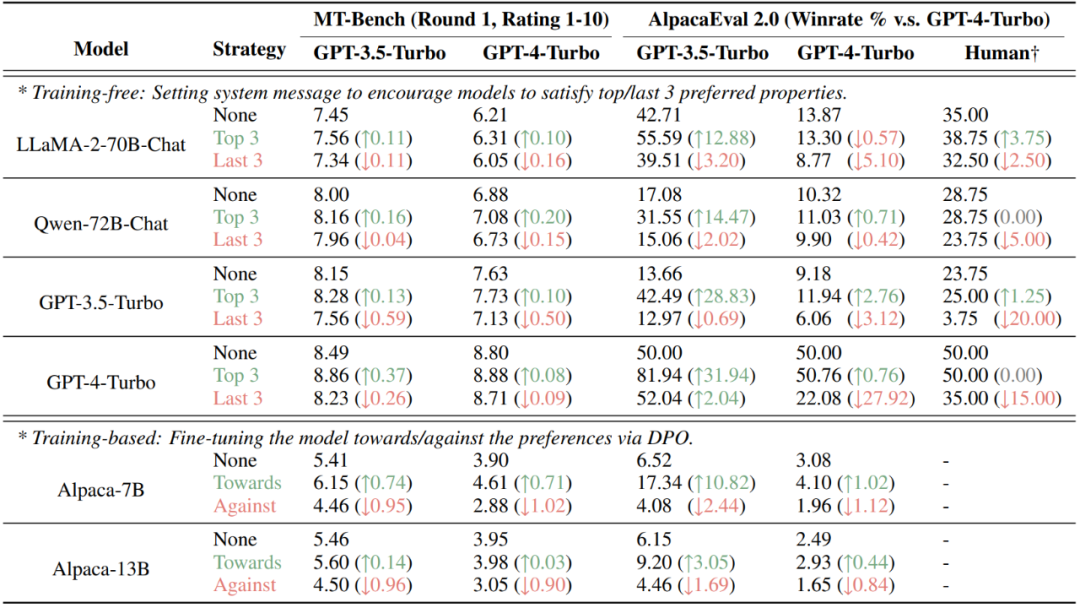
Figure 7 : Résultats de la manipulation intentionnelle de deux ensembles de données basés sur l'évaluation des préférences, MT-Bench et AlpacaEval 2.0
Résumé
Cette étude fournit une analyse détaillée de la décomposition quantitative du modèle humain et du grand modèle préférences. L’équipe de recherche a découvert que les humains ont tendance à répondre directement aux questions et sont moins sensibles aux erreurs ; tandis que les grands modèles hautes performances mettent davantage l’accent sur l’exactitude, la clarté et l’innocuité. La recherche montre également que la taille du modèle est un facteur clé affectant les composants préférés, tandis que son réglage fin a peu d'effet. De plus, cette étude démontre la vulnérabilité de plusieurs ensembles de données actuels à la manipulation lorsqu'on connaît les composantes des préférences de l'évaluateur, illustrant les lacunes de l'évaluation basée sur les préférences. L’équipe de recherche a également rendu publiques toutes les ressources de recherche pour soutenir de futures recherches.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Méthode de mise en œuvre de l'algorithme de permutation et de combinaison complète JS
- Comment organiser le contenu d'un tableau dans l'ordre croissant des colonnes
- Comment connaître et comprendre l'intelligence artificielle
- Quelles sont les caractéristiques d'application de la technologie de l'intelligence artificielle dans l'armée ?
- Les chercheurs de Google et d'OpenAI parlent de l'IA : les modèles linguistiques travaillent dur pour « conquérir » les mathématiques