
Maison >Périphériques technologiques >IA >Le débit est multiplié par 5. L'interface LLM pour concevoir conjointement le système back-end et le langage front-end est ici.
Le débit est multiplié par 5. L'interface LLM pour concevoir conjointement le système back-end et le langage front-end est ici.

- PHPzavant
- 2024-03-01 22:55:131222parcourir
Les grands modèles linguistiques (LLM) sont largement utilisés dans des tâches complexes qui nécessitent plusieurs appels de génération en chaîne, des techniques d'indication avancées, un flux de contrôle et une interaction avec l'environnement externe. Malgré cela, les systèmes efficaces actuels pour programmer et exécuter ces applications présentent des lacunes importantes.
Des chercheurs ont récemment proposé un nouveau langage de génération structuré appelé SGLang, qui vise à améliorer l'interactivité avec LLM. En intégrant la conception du système d'exécution back-end et le langage front-end, SGLang rend LLM plus performant et plus facile à contrôler. Cette recherche a également été relayée par Chen Tianqi, chercheur bien connu dans le domaine de l'apprentissage automatique et professeur assistant à la CMU.
De manière générale, les contributions de SGLang incluent principalement :
Sur le backend, l'équipe de recherche a proposé RadixAttention, une technologie de réutilisation du cache KV (cache KV) à travers plusieurs appels de génération LLM, automatique et efficace.
En développement front-end, l'équipe a développé un langage flexible spécifique à un domaine qui peut être intégré dans Python pour contrôler le processus de génération. Ce langage peut être exécuté en mode interpréteur ou en mode compilateur.
Les composants back-end et front-end fonctionnent ensemble pour améliorer l'exécution et l'efficacité de la programmation de programmes LLM complexes.
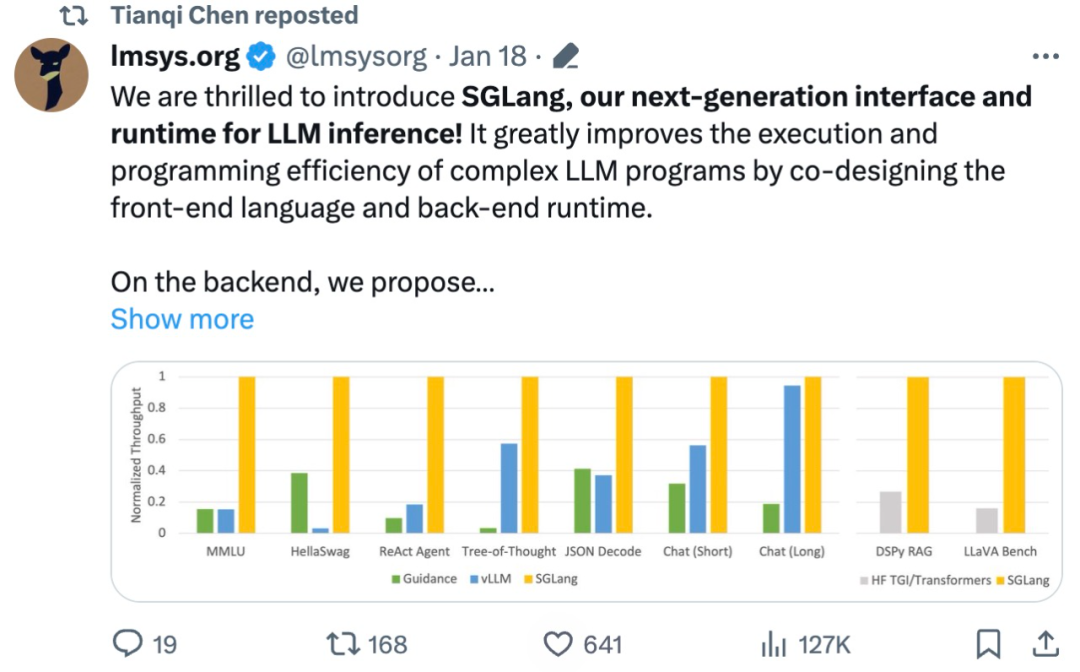
Cette étude utilise SGLang pour implémenter des charges de travail LLM courantes, notamment des tâches d'agent, d'inférence, d'extraction, de dialogue et d'apprentissage en quelques étapes, et adopte les modèles Llama-7B et Mixtral-8x7B sur le GPU NVIDIA A10G. Comme le montrent les figures 1 et 2 ci-dessous, le débit de SGLang est multiplié par 5 par rapport aux systèmes existants (c'est-à-dire Guidance et vLLM).

Figure 1 : Débit des différents systèmes sur les tâches LLM (A10G, Llama-7B sur FP16, parallélisme tensoriel = 1)
Figure 2 : Différents systèmes Débit sur les tâches LLM ( Mixtral-8x7B sur A10G, FP16, parallélisme tensoriel = 8)
Backend : réutilisation automatique du cache KV à l'aide de RadixAttention
Pendant le développement du runtime SGLang, cette étude a découvert la clé de l'optimisation des programmes LLM complexes : la réutilisation du cache KV , ce qui n'est pas bien géré par les systèmes actuels. La réutilisation du cache KV signifie que différentes invites avec le même préfixe peuvent partager le cache KV intermédiaire, évitant ainsi la mémoire et les calculs redondants. Dans les programmes complexes impliquant plusieurs appels LLM, différents modes de réutilisation du cache KV peuvent exister. La figure 3 ci-dessous illustre quatre de ces modèles que l'on retrouve couramment dans les charges de travail LLM. Bien que certains systèmes soient capables de gérer la réutilisation du cache KV dans certains scénarios, une configuration manuelle et des ajustements ad hoc sont souvent nécessaires. De plus, en raison de la diversité des modèles de réutilisation possibles, les systèmes existants ne peuvent pas s'adapter automatiquement à tous les scénarios, même via une configuration manuelle.
Figure 3 : Exemple de partage de cache KV. La boîte bleue est la partie d'invite partageable, la boîte verte est la partie non partageable et la boîte jaune est la sortie du modèle non partageable. Les parties partageables incluent de petits exemples d'apprentissage, des questions d'auto-cohérence, l'historique des conversations sur plusieurs cycles de dialogue et l'historique des recherches dans l'arbre de pensée.
Pour exploiter systématiquement ces opportunités de réutilisation, cette étude propose une nouvelle méthode de réutilisation automatique du cache KV au moment de l'exécution - RadixAttention. Au lieu de supprimer le cache KV après avoir terminé la demande de construction, cette méthode conserve l'invite et le cache KV du résultat de la construction dans une arborescence de base. Cette structure de données permet des recherches, des insertions et des expulsions efficaces de préfixes. Cette étude met en œuvre une politique d'expulsion des moins récemment utilisés (LRU), complétée par une politique de planification prenant en compte le cache pour améliorer le taux de réussite du cache.
Les arbres Radix peuvent être utilisés comme une alternative peu encombrante aux essais (arbres à préfixes). Contrairement aux arbres typiques, les bords des arbres à base peuvent être marqués non seulement avec un seul élément, mais également avec des séquences d'éléments de différentes longueurs, ce qui améliore l'efficacité des arbres à base.
Cette recherche utilise un arbre de base pour gérer le mappage entre les séquences de jetons agissant comme des clés et les tenseurs de cache KV correspondants agissant comme des valeurs. Ces tenseurs de cache KV sont stockés sur le GPU dans une présentation paginée, où chaque page a la taille d'un jeton.
Étant donné que la capacité de mémoire du GPU est limitée et que les tenseurs de cache KV illimités ne peuvent pas être recyclés, une stratégie d'expulsion est nécessaire. Cette étude adopte la stratégie d’expulsion LRU pour expulser les nœuds feuilles de manière récursive. De plus, RadixAttention est compatible avec les technologies existantes telles que le traitement par lots continu et l'attention paginée. Pour les modèles multimodaux, RadixAttention peut être facilement étendu pour gérer les jetons d'image.
Le diagramme ci-dessous illustre comment un arbre de base est conservé lors du traitement de plusieurs requêtes entrantes. Le frontal envoie toujours l'invite complète au runtime, et le runtime effectue automatiquement la correspondance, la réutilisation et la mise en cache des préfixes. La structure arborescente est stockée sur le processeur et nécessite une faible maintenance.
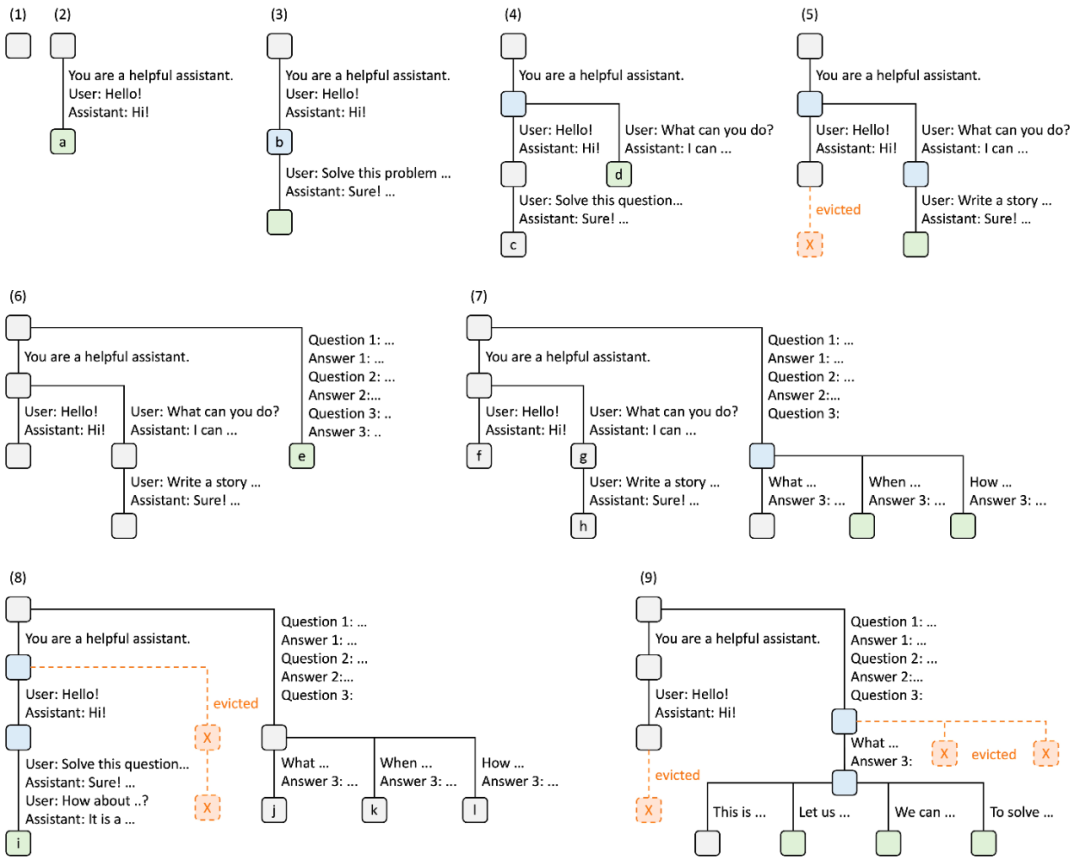
Figure 4. Exemple d'opération RadixAttention utilisant la politique d'expulsion LRU, expliquée en neuf étapes.
La figure 4 démontre l'évolution dynamique de l'arbre de base en réponse à diverses demandes. Ces requêtes incluent deux sessions de chat, un lot de requêtes d'apprentissage en quelques étapes et un échantillonnage auto-cohérent. Chaque bord d'arborescence est étiqueté avec une étiquette qui représente une sous-chaîne ou une séquence de jetons. Les nœuds sont codés par couleur pour refléter différents états : le vert indique les nœuds nouvellement ajoutés, le bleu indique les nœuds mis en cache auxquels on a accédé à ce moment-là et le rouge indique les nœuds qui ont été expulsés.
Front-end : la programmation LLM facilitée avec SGLang
Sur le front-end, la recherche propose SGLang, un langage spécifique à un domaine intégré dans Python qui permet l'expression de techniques d'invite avancées, de flux de contrôle et de multimodalité , décodage des contraintes et interactions externes. Les fonctions SGLang peuvent être exécutées via divers backends tels que OpenAI, Anthropic, Gemini et des modèles natifs.
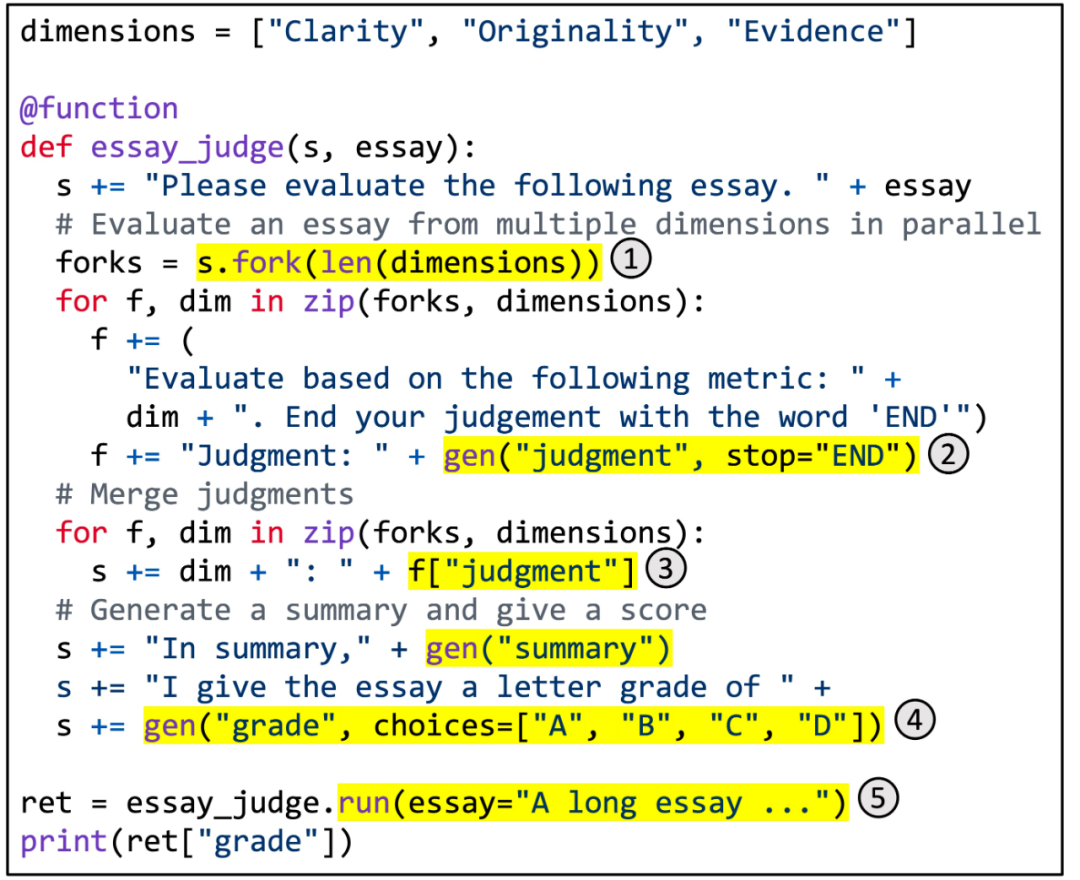
Figure 5. Utilisation de SGLang pour implémenter une notation d'articles multidimensionnelle.
La figure 5 montre un exemple spécifique. Il utilise la technologie d'invite de résolution de branche et de fusion pour obtenir une notation d'article multidimensionnelle. Cette fonction utilise LLM pour évaluer la qualité d'un article selon plusieurs dimensions, combiner les jugements, générer un résumé et attribuer une note finale. La zone en surbrillance illustre l'utilisation de l'API SGLang. (1) fork crée plusieurs copies parallèles de l'invite. (2) gen appelle la génération LLM et stocke les résultats dans des variables. Cet appel n'est pas bloquant, il permet donc à plusieurs appels de build de s'exécuter simultanément en arrière-plan. (3) [variable_name] récupère les résultats générés. (4) Choisir d'imposer des contraintes à la génération. (5) run exécute la fonction SGLang en utilisant ses paramètres.
Étant donné un tel programme SGLang, nous pouvons soit l'exécuter via l'interpréteur, soit le tracer sous forme de graphique de flux de données et l'exécuter à l'aide d'un exécuteur graphique. Cette dernière situation ouvre un espace pour certaines optimisations potentielles du compilateur, telles que le mouvement du code, la sélection d'instructions et le réglage automatique. La syntaxe de
SGLang est fortement inspirée de Guidance et introduit de nouvelles primitives, gérant également le parallélisme procédural et le traitement par lots. Toutes ces nouvelles fonctionnalités contribuent aux excellentes performances de SGLang.
Benchmarks
L'équipe de recherche a testé son système sur des charges de travail LLM courantes et a rapporté le débit atteint.
Plus précisément, l'étude a testé Llama-7B sur 1 GPU NVIDIA A10G (24 Go), Mixtral-8x7B sur 8 GPU NVIDIA A10G avec parallélisme tensoriel en utilisant la précision FP16 et en utilisant vllm v0 .2.5, Guidance v0.1.8 et Hugging Face TGI v1. .3.0 comme systèmes de référence.
Comme le montrent les figures 1 et 2, SGLang surpasse le système de base dans tous les benchmarks, atteignant une augmentation de 5 fois du débit. Il fonctionne également bien en termes de latence, en particulier pour la latence du premier jeton, où les accès au cache de préfixe peuvent apporter des avantages significatifs. Ces améliorations sont attribuées à la réutilisation automatique du cache KV de RadixAttention, au parallélisme dans le programme activé par l'interpréteur et à la co-conception des systèmes front-end et back-end. De plus, les études d'ablation montrent qu'il n'y a pas de surcharge significative qui entraîne l'activation permanente de RadixAttention au moment de l'exécution, même en l'absence d'accès au cache.
Lien de référence : https://lmsys.org/blog/2024-01-17-sglang/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Étapes détaillées pour créer un nouveau projet C++ complet dans VS2015
- Que fait un ingénieur de maintenance des données ?
- Quel âge faut-il pour devenir ingénieur front-end WEB ?
- Que fait un ingénieur de développement Golang ?
- Quelles sont les extensions des fichiers de formulaire et des fichiers de projet ?