Dans le développement actuel des modèles de dialogue intelligent, de puissants modèles sous-jacents jouent un rôle crucial. La pré-formation de ces modèles avancés repose souvent sur des corpus diversifiés et de haute qualité, et la manière de construire un tel corpus est devenue un défi majeur dans l’industrie. Dans le domaine très médiatisé de l'IA pour les mathématiques, la relative rareté de corpus mathématiques de haute qualité limite le potentiel de l'intelligence artificielle générative dans les applications mathématiques. Pour relever ce défi, le Laboratoire d'Intelligence Artificielle Générative de l'Université Jiao Tong de Shanghai a lancé « MathPile ». Il s'agit d'un corpus de pré-formation diversifié et de haute qualité, spécifiquement destiné au domaine des mathématiques, contenant environ 9,5 milliards de jetons, conçu pour améliorer les capacités des grands modèles en matière de raisonnement mathématique. De plus, le laboratoire a également lancé la version commerciale de MathPile - "MathPile_Commercial" pour élargir encore son champ d'application et son potentiel commercial. 
Adresse de l'ensemble de données :
- Utilisation pour la recherche : https://huggingface.co/datasets/GAIR/MathPile
- Commercial version : https://huggingface.co/datasets/GAIR/MathPile_Commercial
MathPile a les fonctionnalités suivantes :
1. Avec les mathématiques centrées : Contrairement aux corpus passés axés sur des domaines généraux, comme Pile, RedPajama, ou le corpus multilingue ROOTS, etc., MathPile se concentre sur le domaine des mathématiques. S’il existe déjà quelques corpus mathématiques spécialisés, soit ils ne sont pas open source (comme le corpus utilisé par Google pour entraîner Minerva, MathMix d’OpenAI), soit ne sont pas assez riches et diversifiés (comme ProofPile et le récent OpenWebMath). 2. Diversité : MathPile propose un large éventail de sources de données, telles que des manuels de mathématiques open source, des notes de cours, des manuels synthétiques, des articles liés aux mathématiques sur arXiv, des entrées liées aux mathématiques sur Wikipédia et ProofWiki Lemma. des preuves et des définitions pour, des questions et réponses mathématiques de haute qualité sur StackExchange, un site communautaire de questions-réponses et des pages Web mathématiques de Common Crawl. Le contenu ci-dessus couvre du contenu adapté aux écoles primaires et secondaires, aux universités, aux étudiants diplômés et aux concours de mathématiques. MathPile couvre pour la première fois 0,19 milliard de jetons de manuels de mathématiques de haute qualité. 3. Haute qualité : L'équipe de recherche suit le concept « moins c'est plus » pendant le processus de collecte et croit fermement que la qualité des données est meilleure que la quantité, même au stade de pré-formation. À partir d’une source de données d’environ 520 milliards de jetons (environ 2,2 To), ils sont passés par un ensemble rigoureux et complexe d’étapes de prétraitement, de pré-filtrage, d’identification de langue, de nettoyage, de filtrage et de déduplication pour garantir la haute qualité du corpus. Il convient de mentionner que le MathMix utilisé par OpenAI ne contient que 1,5 milliard de jetons. 4. Documentation des données : Afin d'accroître la transparence, l'équipe de recherche a documenté MathPile et a fourni une fiche d'ensemble de données. Au cours du processus de traitement des données, l'équipe de recherche a également effectué une « annotation de qualité » sur des documents provenant du Web. Par exemple, le score de reconnaissance linguistique et le rapport symboles/mots dans le document permettent aux chercheurs de filtrer davantage les documents en fonction de leurs propres besoins. Ils ont également effectué une détection de contamination des ensembles de tests en aval sur le corpus afin d'éliminer les échantillons des ensembles de tests de référence tels que MATH et MMLU-STEM. Dans le même temps, l'équipe de recherche a également découvert qu'il existe également un grand nombre d'échantillons de test en aval dans OpenWebMath, ce qui montre qu'il convient de faire très attention lors de la production d'un corpus de pré-formation afin d'éviter une évaluation en aval invalide. 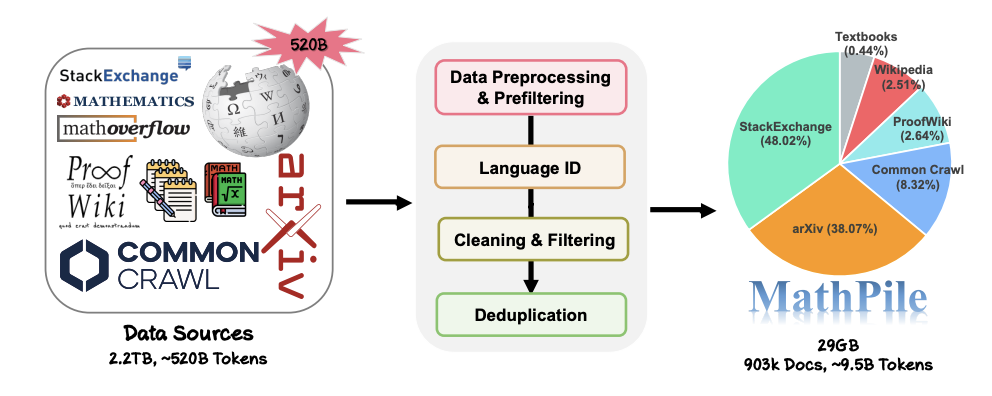
Processus de collecte et de traitement des données de MathPile.
Détails du traitement des données Aujourd'hui, alors que la concurrence dans le domaine des grands modèles s'intensifie, de nombreuses entreprises technologiques ne divulguent plus leurs données, ainsi que leurs sources et ratios de données, sans parler des détails détaillés du pré-traitement. Au contraire, MathPile résume un ensemble de méthodes de traitement de données adaptées au domaine mathématique sur la base d'explorations précédentes. Dans la partie nettoyage et filtrage des données, les étapes spécifiques adoptées par l'équipe de recherche sont :
- Détecter les lignes contenant « lorem ipsum » si « lorem ipsum » dans la ligne est remplacé par less. plus de 5 caractères, supprimez la ligne ;
- détecte les lignes qui contiennent "javescript" et contiennent également "enable", "disable" ou "browser", et que le nombre de caractères dans la ligne est inférieur à 200 caractères, puis filtrez lignes de ligne ;
- Filtrer les lignes de moins de 10 mots et contenant "Connexion", "Connexion", "En savoir plus..." ou "articles dans le panier"
- Filtrer ; mots majuscules Documents qui représentent plus de 40 % ;
- Filtrer les documents où les lignes se terminant par des points de suspension représentent plus de 30 % de l'ensemble du document
- Filtrer les documents où les mots autres que des lettres représentent plus ; supérieur à 80 % ;
- Filtrer les documents dont la longueur moyenne des caractères des mots anglais est en dehors de la plage (3, 10) ;
- Filtrer les documents qui ne contiennent pas au moins deux mots vides (tels que, be, à, de, et, avoir, etc. )
- Filtrer les documents où le rapport entre les ellipses et les mots dépasse 50%
- Filtrer les documents où les lignes commençant par des puces représentent plus de 90% ;
- Filtrer et supprimer les espaces et les documents contenant moins de 200 caractères après la ponctuation
Plus de détails sur le traitement peuvent être trouvés dans le document. De plus, l'équipe de recherche a également fourni de nombreux échantillons de données pendant le processus de nettoyage. L'image ci-dessous montre les documents presque en double dans Common Crawl détectés par l'algorithme MinHash LSH (affichés en surbrillance rose). 
Comme le montre la figure ci-dessous, l'équipe de recherche a découvert des problèmes dans l'ensemble de tests MATH (comme surligné en jaune) au cours du processus de détection des fuites de données. 
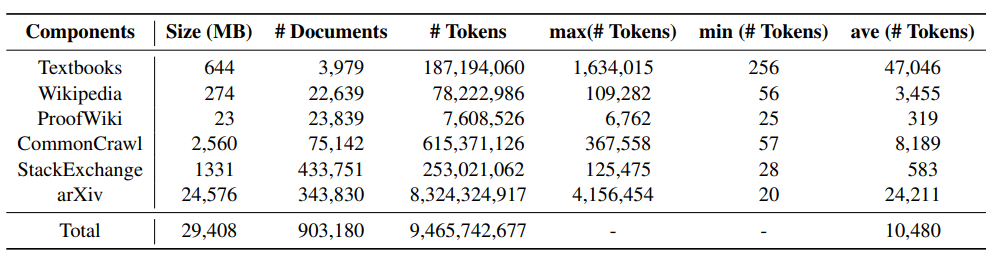
Statistiques et exemples d'ensembles de donnéesLe tableau suivant montre les informations statistiques de chaque composant de MathPile. Vous pouvez constater que les articles et manuels arXiv ont généralement des documents plus longs, tandis que les documents sur les wikis sont relativement courts. . L'image ci-dessous est un exemple de document d'un manuel du corpus MathPile. On peut voir que la structure du document est relativement claire et que la qualité est élevée. 
Résultats expérimentaux
L'équipe de recherche a également divulgué quelques résultats expérimentaux préliminaires. Ils ont effectué une pré-formation supplémentaire basée sur le modèle Mistral-7B, actuellement populaire. Ensuite, il a été évalué sur certains ensembles de données de référence de raisonnement mathématique courants grâce à une méthode d'invite en quelques tirs. Les données expérimentales préliminaires qui ont été obtenues jusqu'à présent sont les suivantes :
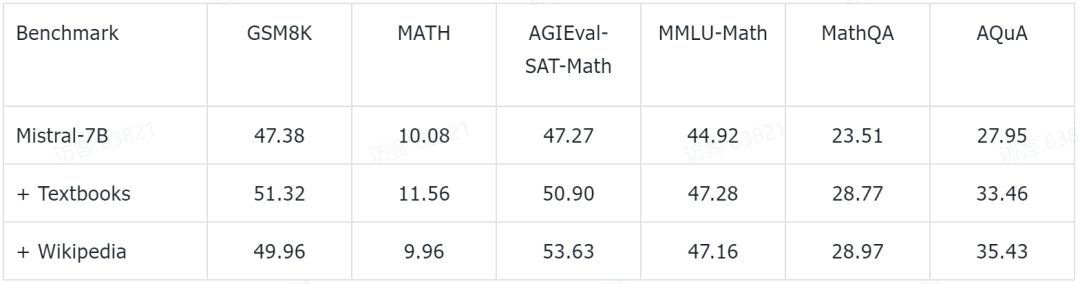
Ces tests de référence couvrent tous les niveaux de connaissances mathématiques, y compris les mathématiques de l'école primaire (telles que GSM8K, TAL-SCQ5K-EN et MMLU-Math), les mathématiques scolaires (telles que MATH, SAT -Math, MMLU-Math, AQuA et MathQA) et les mathématiques universitaires (par exemple MMLU-Math). Les résultats expérimentaux préliminaires annoncés par l'équipe de recherche montrent qu'en continuant à se pré-entraîner sur les manuels et les sous-ensembles de Wikipédia dans MathPile, le modèle de langage a permis d'améliorer considérablement les capacités de raisonnement mathématique à différents niveaux de difficulté.
L'équipe de recherche a également souligné que des expériences pertinentes sont toujours en cours.
Conclusion
MathPile a reçu une large attention depuis sa sortie et a été réimprimé par de nombreuses parties. Il figure actuellement sur la liste des tendances des ensembles de données Huggingface. L'équipe de recherche a déclaré qu'elle continuerait à optimiser et à mettre à niveau l'ensemble de données pour améliorer encore la qualité des données. 
MathPile figure sur la liste des tendances des ensembles de données Huggingface.  MathPile a été transmis par le célèbre blogueur IA AK, source : https://twitter.com/_akhaliq/status/1740571256234057798.
MathPile a été transmis par le célèbre blogueur IA AK, source : https://twitter.com/_akhaliq/status/1740571256234057798.
Actuellement, MathPile a été mis à jour vers la deuxième version, dans le but de contribuer à la recherche et au développement de la communauté open source. Parallèlement, sa version commerciale de l'ensemble de données a également été ouverte au public. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!