
Maison >Périphériques technologiques >IA >Nouveau travail de l'équipe de Chen Danqi : le contexte Llama-2 est étendu à 128 Ko, le débit 10 fois ne nécessite que 1/6 de la mémoire
Nouveau travail de l'équipe de Chen Danqi : le contexte Llama-2 est étendu à 128 Ko, le débit 10 fois ne nécessite que 1/6 de la mémoire

- PHPzavant
- 2024-03-01 12:20:04838parcourir
L'équipe Chen Danqi vient de publier une nouvelle méthode d'extension de fenêtre contextuelle LLM :
Elle peut étendre la fenêtre Llama-2 à 128 000 en utilisant seulement 8 000 documents symboliques pour la formation.
La chose la plus importante est que dans ce processus, le modèle ne nécessite que 1/6 de la mémoire d'origine, et le modèle atteint 10 fois le débit.
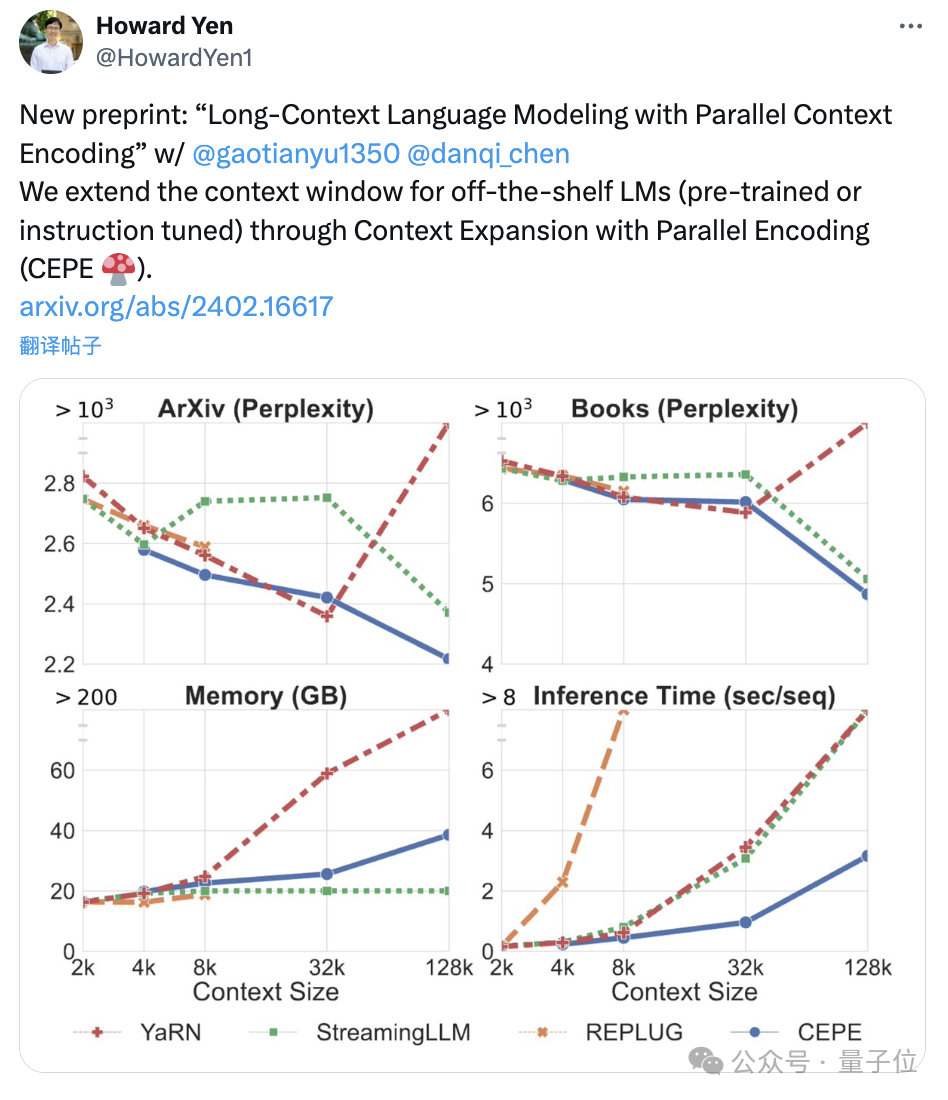
De plus, cela peut aussi considérablement réduire les coûts de formation :
L'utilisation de cette méthode pour transformer l'alpaga 7B 2 ne nécessite que un morceau de A100.
L'équipe a déclaré :
Nous espérons que cette méthode sera utile et facile à utiliser, et fournira des capacités de contexte long peu coûteuses et efficaces pour les futurs LLM.
Actuellement, le modèle et le code sont publiés sur HuggingFace et GitHub.
Ajoutez simplement deux composants
Cette méthode s'appelle CEPE, le nom complet est "Context Expansion with Parallel Encoding(Context Expansion with Parallel Encoding)".
En tant que framework léger, il peut être utilisé pour étendre la fenêtre contextuelle de n'importe quel modèlepré-entraîné et avec instructions affinées.
Pour tout modèle de langage pré-entraîné réservé au décodeur, le CEPE l'étend en ajoutant deux petits composants :L'un est un petit encodeur pour l'encodage par blocs d'un contexte long
L'un est le module Force d'attention croisée , inséré ; dans chaque couche du décodeur, est utilisé pour se concentrer sur la représentation du codeur.
L'architecture complète est la suivante :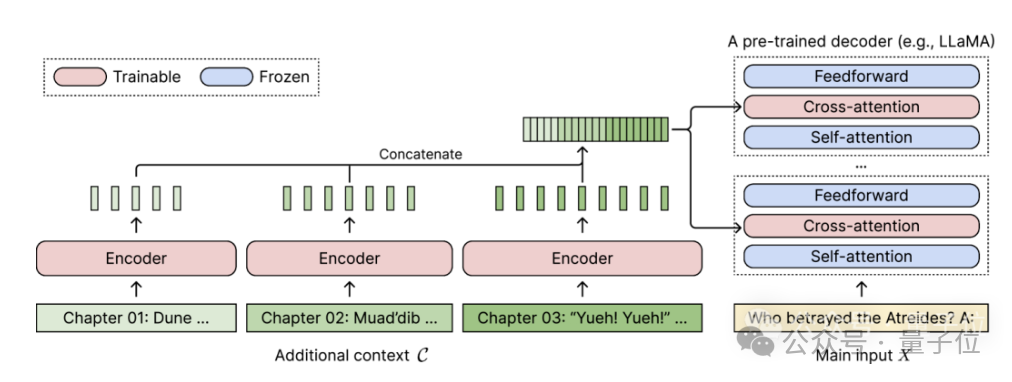
(1) La longueur est généralisable
car elle n'est pas contrainte par l'encodage positionnel. Au contraire, son contexte est segmenté et codé, et chaque segment. is A son propre encodage de localisation.(2) Haute efficacitéL'utilisation de petits encodeurs et d'un codage parallèle pour traiter le contexte peut réduire les coûts de calcul.
(3) Réduire les coûts de formation
avec un encodeur de 400 Mo et une couche d'attention croisée (un total de 1,4 milliard de paramètres) , il peut être complété par un GPU A100 de 80 Go.
La perplexité continue de diminuerL'équipe a appliqué le CEPE à Llama-2 et s'est entraînée sur une version filtrée de 20 milliards de jetons de RedPajama(seulement 1% du budget de pré-formation de Llama-2).
Premièrement, par rapport à deux modèles entièrement réglés, LLAMA2-32K et YARN-64K, le CEPE atteint uneperplexité inférieure ou comparable sur tous les ensembles de données tout en ayant des taux d'utilisation de la mémoire inférieurs et un débit plus élevé.
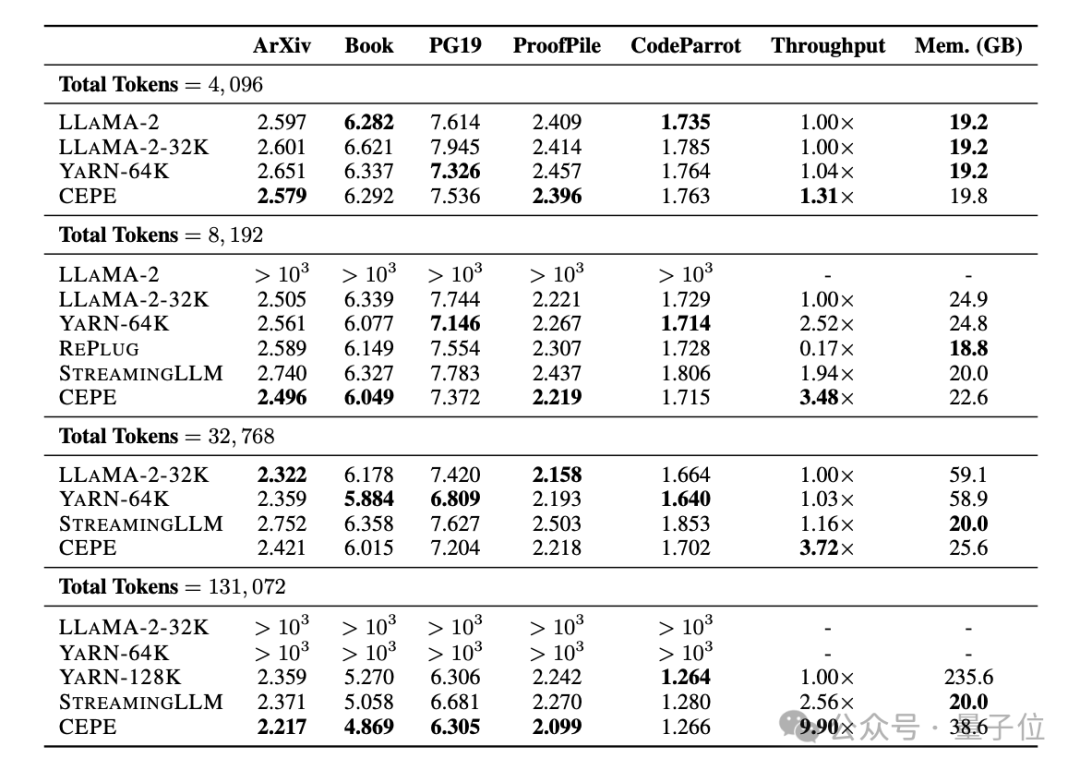
(dépassant largement sa durée d'entraînement de 8k) , la perplexité du CEPE continue de diminuer tout en maintenant un état de mémoire faible.
En revanche, Llama-2-32K et YARN-64K non seulement ne parviennent pas à se généraliser au-delà de leur durée d'entraînement, mais s'accompagnent également d'une augmentation significative du coût de la mémoire.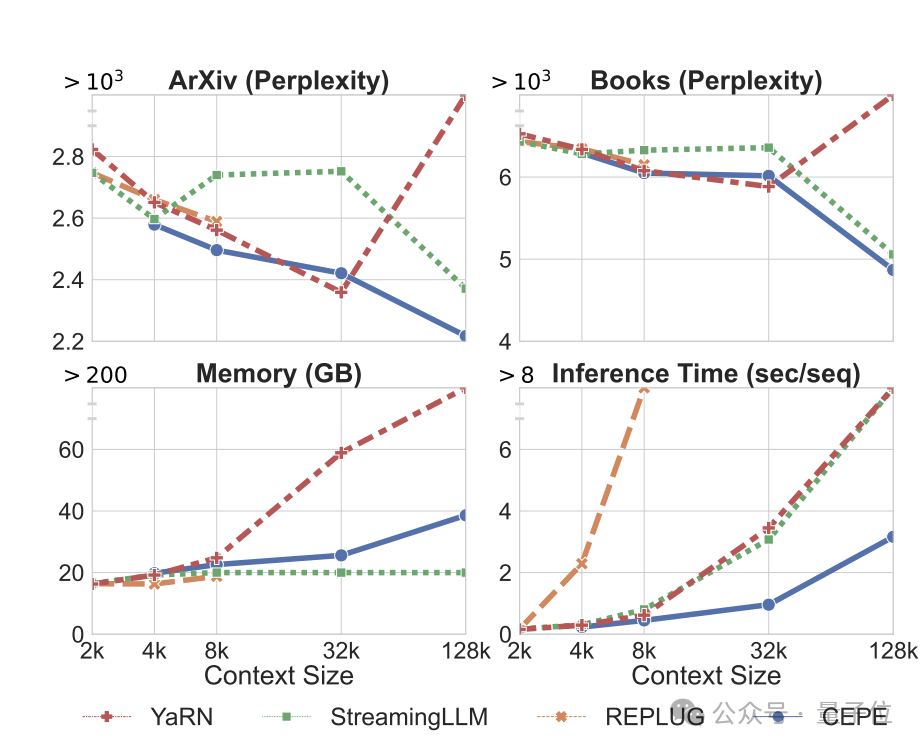
capacités de récupération sont améliorées.
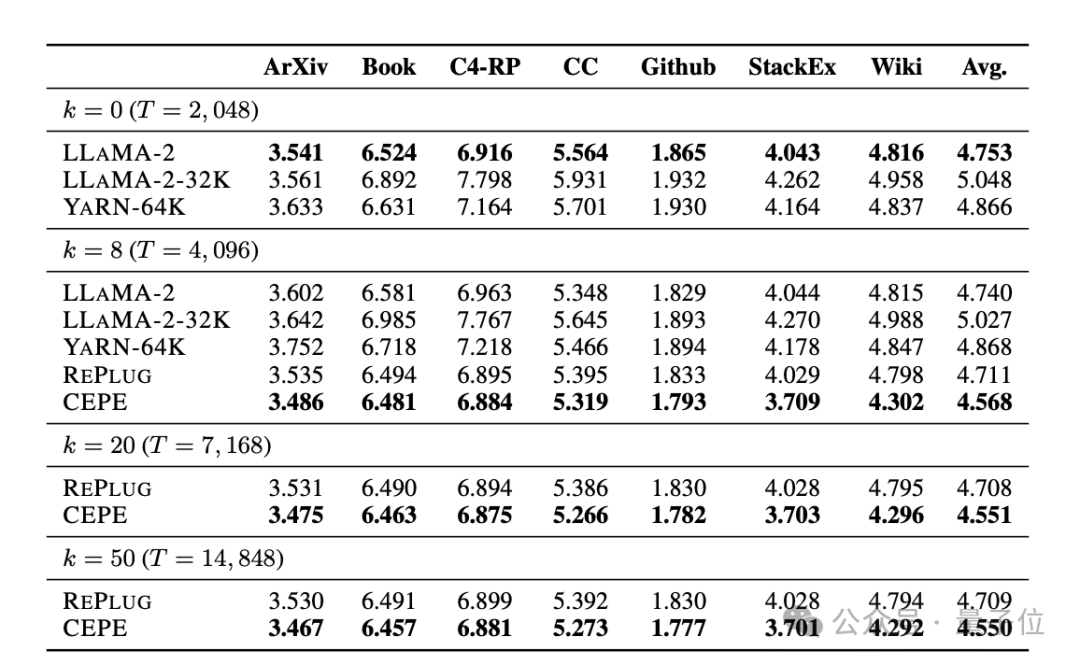
Comme le montre le tableau suivant : En utilisant le contexte récupéré, CEPE peut améliorer efficacement la perplexité du modèle et être plus performant que RePlug.Il est à noter que même si le paragraphe k=50 (la formation est de 60), le CEPE continuera d'améliorer la perplexité.
Cela montre que le CEPE transfère bien vers un paramètre de récupération amélioré, alors que le modèle de décodeur en contexte complet se dégrade dans cette capacité.
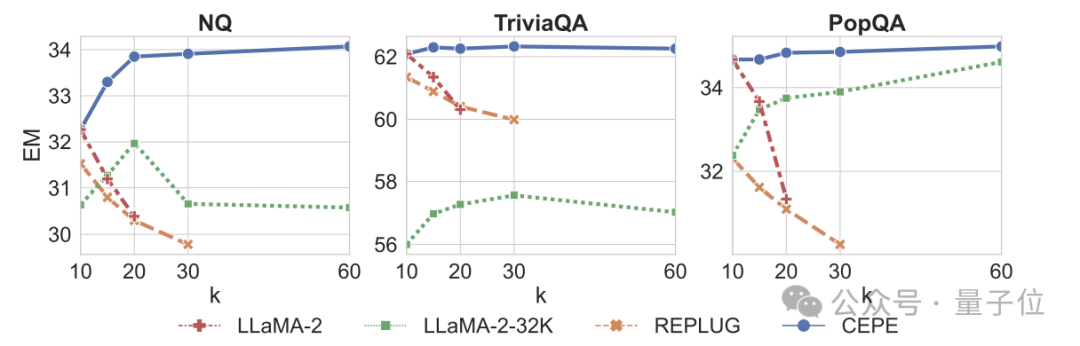
Troisièmement, capacités de questions et réponses du domaine ouvert largement dépassées.
Comme le montre la figure ci-dessous, le CEPE est nettement meilleur que les autres modèles dans tous les ensembles de données et paramètres du paragraphe k, et contrairement à d'autres modèles, les performances diminuent considérablement à mesure que la valeur k devient de plus en plus grande.
Cela montre également que le CEPE n'est pas sensible aux grandes quantités de paragraphes redondants ou non pertinents.
Donc, pour résumer, CEPE surpasse toutes les tâches ci-dessus avec une mémoire et un coût de calcul bien inférieurs à ceux de la plupart des autres solutions.
Enfin, sur la base de ces fondations, l'auteur a proposé CEPE-Distilled (CEPED) spécifiquement pour les modèles de réglage d'instructions.
Il utilise uniquement des données non étiquetées pour étendre la fenêtre contextuelle du modèle, distillant le comportement du modèle original optimisé par les instructions dans une nouvelle architecture grâce à la perte de divergence KL assistée, éliminant ainsi le besoin de gérer des données coûteuses de suivi des instructions contextuelles longues.
En fin de compte, CEPED peut étendre la fenêtre contextuelle de Llama-2 et améliorer les performances des textes longs du modèle tout en conservant la capacité de comprendre les instructions.
Présentation de l'équipe
Le CEPE compte au total 3 auteurs.
L'un d'eux est Yan Heguang(Howard Yen), étudiant à la maîtrise en informatique à l'Université de Princeton.
La deuxième personne est Gao Tianyu, doctorant dans la même école et diplômé de l'Université Tsinghua.
Ils sont tous étudiants de l'auteur correspondant Chen Danqi.

Texte original de l'article : https://arxiv.org/abs/2402.16617
Lien de référence : https://twitter.com/HowardYen1/status/1762474556101661158
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!