
Maison >Périphériques technologiques >IA >Vous voulez former un modèle de type Sora ? L'équipe OpenDiT de You Yang atteint une accélération de 80 %
Vous voulez former un modèle de type Sora ? L'équipe OpenDiT de You Yang atteint une accélération de 80 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-29 16:34:381165parcourir
L'incroyable performance de Sora au début de 2024 est devenue une nouvelle référence, inspirant tous ceux qui étudient les vidéos de Wensheng à se précipiter pour rattraper leur retard. Chaque chercheur est impatient de reproduire les résultats de Sora et travaille contre le temps.
Selon le rapport technique divulgué par OpenAI, un point d'innovation important de Sora est de convertir les données visuelles en une représentation unifiée de correctifs et de démontrer une excellente évolutivité grâce à la combinaison du transformateur et du modèle de diffusion. Avec la publication du rapport, l'article « Scalable Diffusion Models with Transformers » co-écrit par William Peebles, développeur principal de Sora, et Xie Saining, professeur adjoint d'informatique à l'Université de New York, a attiré beaucoup d'attention de la part des chercheurs. La communauté des chercheurs espère explorer des moyens réalisables de reproduire Sora grâce à l'architecture DiT proposée dans l'article.
Récemment, un projet appelé OpenDiT open source par l'équipe You Yang de l'Université nationale de Singapour a ouvert de nouvelles idées pour la formation et le déploiement de modèles DiT.
OpenDiT est un système conçu pour améliorer l'efficacité de la formation et de l'inférence des applications DiT. Il est non seulement facile à utiliser, mais également rapide et économe en mémoire. Le système couvre des fonctions telles que la génération de texte en vidéo et la génération de texte en image, visant à offrir aux utilisateurs une expérience efficace et pratique.
Adresse du projet : https://github.com/NUS-HPC-AI-Lab/OpenDiT
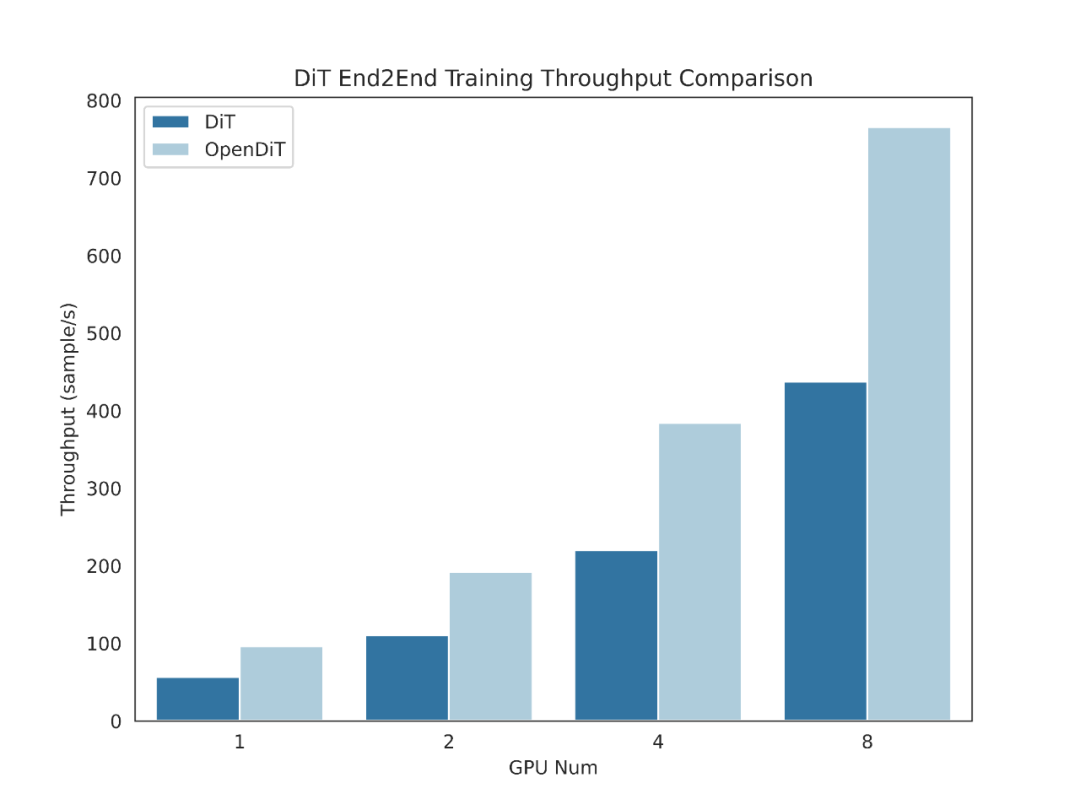
Introduction à la méthode OpenDiT
OpenDiT fournit une diffusion prise en charge par Colossal-AI A implémentation haute performance de Transformer (DiT). Pendant la formation, les informations vidéo et de condition sont entrées dans l'encodeur correspondant respectivement en tant qu'entrée du modèle DiT. Par la suite, la formation et la mise à jour des paramètres sont effectuées via la méthode de diffusion, et enfin les paramètres mis à jour sont synchronisés avec le modèle EMA (Exponential Moving Average). Dans la phase d'inférence, le modèle EMA est directement utilisé, en prenant les informations de condition en entrée pour générer les résultats correspondants.
Source de l'image : https://www.zhihu.com/people/berkeley-you-yang
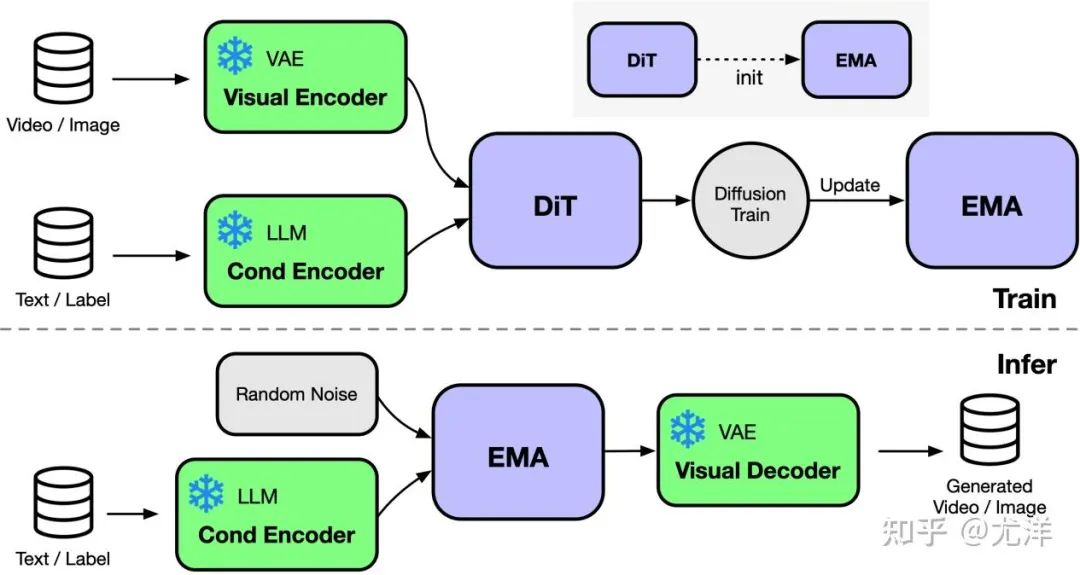
OpenDiT utilise la stratégie parallèle ZeRO pour distribuer les paramètres du modèle DiT à plusieurs machines avec mémoire préliminaire réduite. pression. Afin d'obtenir un meilleur équilibre entre performances et précision, OpenDiT adopte également une stratégie de formation à précision mixte. Plus précisément, les paramètres du modèle et les optimiseurs sont stockés à l'aide de float32 pour garantir des mises à jour précises. Au cours du processus de calcul du modèle, l'équipe de recherche a conçu une méthode de précision mixte float16 et float32 pour le modèle DiT afin d'accélérer le processus de calcul tout en maintenant la précision du modèle.
La méthode EMA utilisée dans le modèle DiT est une stratégie de lissage des mises à jour des paramètres du modèle, qui peut améliorer efficacement la stabilité et la capacité de généralisation du modèle. Cependant, une copie supplémentaire des paramètres sera générée, ce qui augmentera la charge sur la mémoire vidéo. Afin de réduire encore davantage cette part de mémoire vidéo, l’équipe de recherche a fragmenté le modèle EMA et l’a stocké sur différents GPU. Pendant le processus de formation, chaque GPU n'a besoin que de calculer et de stocker sa propre partie des paramètres du modèle EMA, et d'attendre que ZeRO termine la mise à jour après chaque étape pour des mises à jour synchrones.
FastSeq
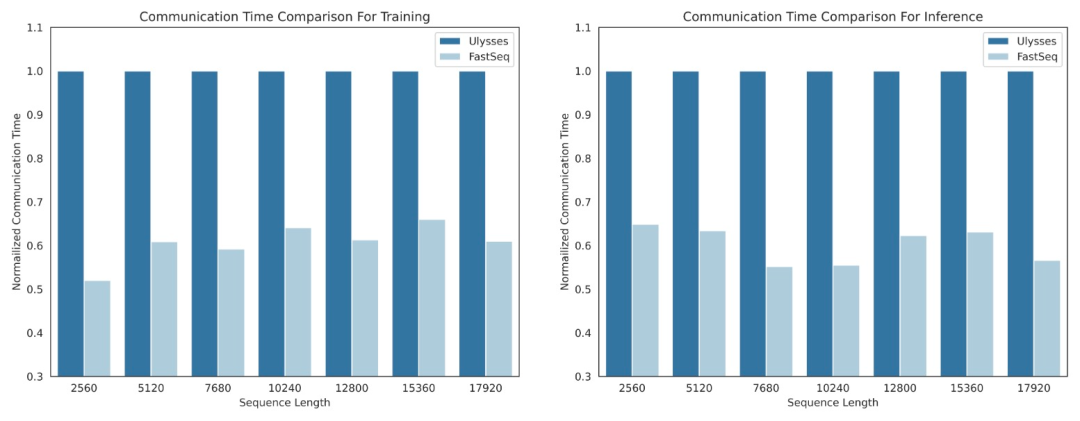
Dans le domaine des modèles génératifs visuels tels que DiT, le parallélisme de séquence est essentiel pour un entraînement efficace de séquences longues et une inférence à faible latence.
Cependant, les méthodes existantes telles que DeepSpeed-Ulysses, le parallélisme de séquence Megatron-LM, etc. sont confrontées à des limites lorsqu'elles sont appliquées à de telles tâches - soit en introduisant trop de communication de séquence, soit en en manquant lorsqu'il s'agit d'efficacité du parallélisme de séquence à petite échelle.
À cette fin, l'équipe de recherche a proposé FastSeq, un nouveau parallélisme de séquence adapté aux grandes séquences et au parallélisme à petite échelle. FastSeq minimise la communication séquentielle en utilisant seulement deux opérateurs de communication par couche de transformateur, exploite AllGather pour améliorer l'efficacité de la communication et utilise stratégiquement des anneaux asynchrones pour chevaucher la communication AllGather avec les calculs qkv afin d'optimiser davantage les performances.
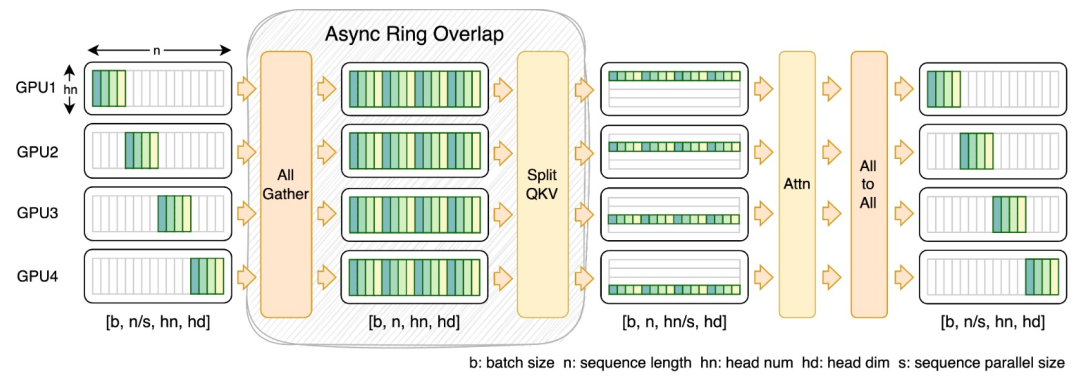
Optimisation des opérateurs
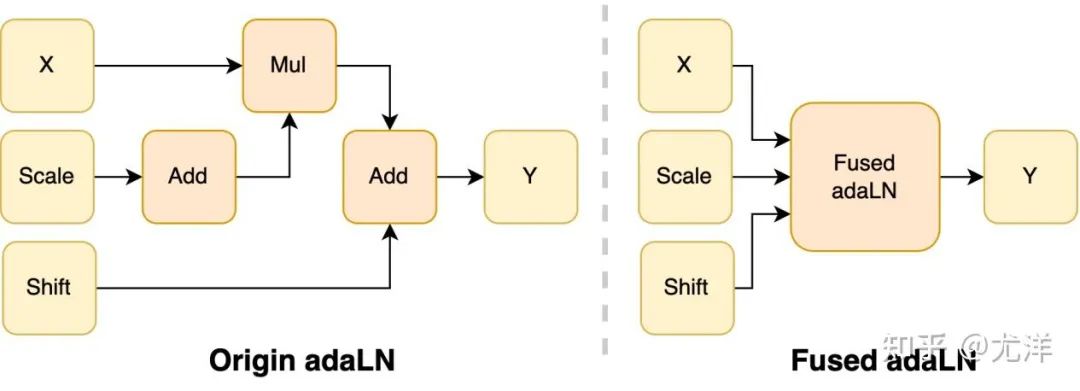
Le module adaLN est introduit dans le modèle DiT pour intégrer des informations conditionnelles dans le contenu visuel Bien que cette opération soit cruciale pour améliorer les performances du modèle, elle apporte également un grand nombre d'opérations élément par élément et est fréquemment appelée. le modèle, ce qui réduit l'efficacité de calcul globale. Afin de résoudre ce problème, l'équipe de recherche a proposé un noyau Fused adaLN efficace, qui fusionne plusieurs opérations en une seule, augmentant ainsi l'efficacité informatique et réduisant la consommation d'E/S d'informations visuelles.
Source de l'image : https://www.zhihu.com/people/berkeley-you-yang
En termes simples, OpenDiT présente les avantages de performances suivants :
1. GPU Jusqu'à 80 % d'accélération, 50 % d'économie de mémoire
- Conçu des opérateurs efficaces, notamment Fused AdaLN conçu pour DiT, ainsi que FlashAttention, Fused Layernorm et HybridAdam.
- Utiliser une approche parallèle hybride comprenant ZeRO, Gemini et DDP. Le partage du modèle ema réduit également davantage les coûts de mémoire.
2. FastSeq : une nouvelle approche parallèle de séquence
- est conçue pour les charges de travail de type DiT, où les séquences sont généralement plus longues mais les paramètres sont plus petits que LLM Small.
- Le parallélisme des séquences intra-nœuds peut économiser jusqu'à 48 % du volume de communication.
- Briser les limitations de mémoire d'un seul GPU et réduire le temps global de formation et d'inférence.
3. Facile à utiliser
- Vous pouvez obtenir d'énormes améliorations de performances avec seulement quelques lignes de modifications de code.
- Les utilisateurs n'ont pas besoin de comprendre comment la formation distribuée est mise en œuvre.
4. Pipeline complet de génération texte-image et texte-vidéo
- Les chercheurs et les ingénieurs peuvent facilement utiliser le pipeline OpenDiT et l'appliquer à des applications pratiques sans modifier la partie parallèle.
- L'équipe de recherche a vérifié l'exactitude d'OpenDiT en effectuant une formation texte-image sur ImageNet et a publié un point de contrôle.
Installation et utilisation
Pour utiliser OpenDiT, vous devez d'abord installer les prérequis :
- Python >= 3.10
- PyTorch >= 1.13 ( recommandé d'utiliser >2. 0)
- CUDA >= 11.6
Il est recommandé de créer un nouvel environnement en utilisant Anaconda (Python >= 3.10) pour exécuter les exemples :
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
Installer ColossalAI :
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
Installer OpenDiT :
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
(facultatif mais recommandé) Installer des bibliothèques pour accélérer la formation et l'inférence :
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
génération
Vous pouvez vous entraîner le modèle DiT en exécutant la commande suivante :
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
Toutes les méthodes d'accélération sont désactivées par défaut. Voici des détails sur certains des éléments clés du processus de formation :
- plugin : prend en charge les plugins booster utilisés par ColossalAI, zero2 et ddp. La valeur par défaut est zéro2, il est recommandé d'activer zéro2.
- mixed_precision : le type de données de l'entraînement de précision mixte, la valeur par défaut est fp16.
- grad_checkpoint : s'il faut activer le point de contrôle du dégradé. Cela permet d'économiser le coût de la mémoire du processus de formation. La valeur par défaut est Faux. Il est recommandé de le désactiver s'il y a suffisamment de mémoire.
- enable_modulate_kernel : s'il faut activer l'optimisation du noyau module pour accélérer le processus de formation. La valeur par défaut est False et il est recommandé de l'activer sur les GPU
- enable_layernorm_kernel : s'il faut activer l'optimisation du noyau layernorm pour accélérer le processus de formation. La valeur par défaut est False et il est recommandé de l'activer.
- enable_flashattn : s'il faut activer FlashAttention pour accélérer le processus de formation. La valeur par défaut est False et il est recommandé de l'activer.
- sequence_parallel_size : taille du parallélisme des séquences. Le parallélisme de séquence est activé lors de la définition d'une valeur > 1. La valeur par défaut est 1, il est recommandé de la désactiver s'il y a suffisamment de mémoire.
Si vous souhaitez utiliser le modèle DiT pour l'inférence, vous pouvez exécuter le code suivant. Vous devez remplacer le chemin du point de contrôle par votre propre modèle entraîné.
# Use scriptbash sample_img.sh# Use command linepython sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
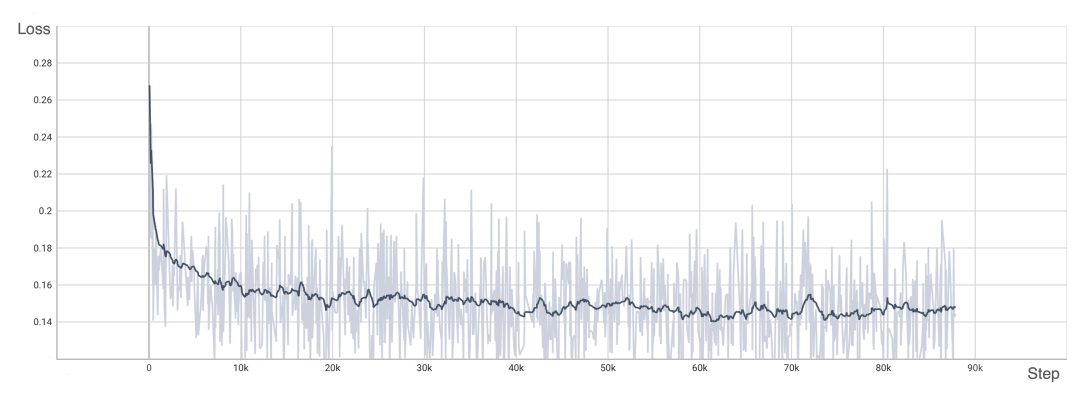
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment résoudre le problème de l'absence de la barre d'attributs en haut de l'IA ?
- De quoi est indépendant le modèle conceptuel d'une base de données ?
- Qu'est-ce qu'un modèle de développement logiciel et quels sont les modèles de développement logiciels courants ?
- Qu'est-ce que la technologie de l'IA ?
- Quelle est la différence entre Apple Mac Air et Pro