
Maison >Périphériques technologiques >IA >Pour compenser les lacunes de la planification du Transformer, le Searchformer de l'équipe de Tian Yuandong est devenu populaire.
Pour compenser les lacunes de la planification du Transformer, le Searchformer de l'équipe de Tian Yuandong est devenu populaire.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-26 08:01:22731parcourir
La puissante capacité de généralisation de Transformer a encore été prouvée !
Ces dernières années, les structures basées sur des transformateurs ont attiré l'attention du monde entier en raison de leurs excellentes performances dans diverses tâches. En utilisant cette structure et en la combinant avec de grandes quantités de données, les modèles résultants tels que les grands modèles de langage (LLM) peuvent être bien adaptés à des scénarios d'application pratiques.
Malgré leur succès dans certains domaines, les architectures basées sur des transformateurs et les LLM sont toujours confrontées à des défis, notamment dans la gestion des tâches de planification et d'inférence. Des recherches antérieures ont montré que le LLM a des difficultés à gérer des tâches de planification en plusieurs étapes ou des tâches de raisonnement d'ordre supérieur.
Afin d'améliorer les performances de raisonnement et de planification de Transformer, la communauté des chercheurs a également proposé certaines méthodes ces dernières années. L'une des méthodes les plus courantes et les plus efficaces consiste à simuler le processus de pensée humaine : d'abord générer une « pensée » intermédiaire, puis produire une réponse. Par exemple, la méthode d'incitation Chain of Thought (CoT) encourage le modèle à prédire les étapes intermédiaires et à effectuer une « réflexion » étape par étape. L'arbre de réflexion (ToT) utilise des stratégies de branchement et des méthodes d'évaluation pour permettre au modèle de générer plusieurs chemins de réflexion différents, puis de sélectionner parmi eux le meilleur chemin. Bien que ces techniques soient souvent efficaces, des recherches ont montré que, dans de nombreux cas, ces méthodes dégradent les performances du modèle, notamment pour des raisons d'auto-application.
Une technique qui fonctionne bien sur un ensemble de données peut ne pas fonctionner correctement sur d'autres ensembles de données. Cela peut être dû à un changement dans le type de raisonnement requis, comme le passage d’un raisonnement spatial à un raisonnement mathématique ou de bon sens.
En revanche, les techniques traditionnelles de planification et de recherche symbolique démontrent d'excellentes capacités de raisonnement. De plus, les solutions calculées par ces méthodes traditionnelles possèdent souvent des garanties formelles, puisque les algorithmes de planification symbolique suivent généralement un processus de recherche basé sur des règles bien définies.
Afin de doter Transformer de capacités de raisonnement complexes, l'équipe Meta FAIR Tian Yuandong a récemment proposé Searchformer.

Titre de l'article : Beyond A* : Better Planning with Transformers via Search Dynamics Bootstrapping
Adresse de l'article : https://arxiv.org/pdf/2402.14083.pdf
Searchformer est un transformateur modèle, mais pour les tâches de planification en plusieurs étapes telles que la navigation dans un labyrinthe et la poussée de boîtes, il peut calculer le plan optimal et le nombre d'étapes de recherche utilisées peut être bien inférieur à celui des algorithmes de planification symbolique tels que la recherche A*.
Pour ce faire, l'équipe a proposé une nouvelle méthode : le bootstrapping de la dynamique de recherche. Cette méthode entraîne d'abord un modèle Transformer pour imiter le processus de recherche de A* (comme le montre la figure 1), puis l'affine afin qu'il puisse trouver le plan optimal avec moins d'étapes de recherche

Plus de détails dans. en d'autres termes, la première étape consiste à former un modèle Transformer qui imite la recherche A*. Ici, l'approche de l'équipe consiste à exécuter la recherche A* sur des instances de tâches de planification générées de manière aléatoire. Lorsque A* est exécuté, l'équipe enregistre les calculs effectués de manière optimale. planifiez-les et organisez-les en séquences de mots, c'est-à-dire en jetons. De cette manière, l'ensemble de données d'entraînement résultant contient la trajectoire d'exécution de A* et code des informations sur la dynamique de recherche de A* lui-même. Ensuite, un modèle Transformer est formé. lui permettant de générer ces séquences de jetons selon la planification optimale pour toute tâche de planification
La deuxième étape consiste à utiliser la méthode d'itération experte pour améliorer encore la formation en utilisant la séquence améliorée de recherche ci-dessus (y compris la trajectoire d'exécution de A*). La méthode d'itération experte permet au Transformer de générer des solutions optimales avec moins d'étapes de recherche. Ce processus aboutit à un algorithme de programmation neuronale qui est implicitement codé dans les pondérations du réseau du Transformer et a une grande efficacité pour trouver le plan optimal avec moins d'étapes de recherche. Recherche A*. Par exemple, lors de l'exécution de la tâche de poussée de boîte, le nouveau modèle peut résoudre 93,7 % des tâches de test, tandis que le nombre d'étapes de recherche est 26,8 % inférieur à la recherche A* en moyenne.
L'équipe a déclaré : Cela ouvre. la manière pour Transformer de surpasser les algorithmes de planification symbolique traditionnelsExpériences
Pour mieux comprendre l'impact des données d'entraînement et du volume des paramètres du modèle sur les performances du modèle résultant, ils ont mené des études d'ablation Ils ont utilisé deux types. d'ensembles de données pour entraîner le modèle : l'un a une séquence de jetons qui contient uniquement des solutions (solution uniquement, dans laquelle seules la description de la tâche et la planification finale sont incluses) ; l'autre est une séquence de recherche augmentée, dans laquelle contient la description de la tâche, la recherche ; dynamique des arbres et planification finale). Dans l'expérience, l'équipe a utilisé une variante déterministe et non déterministe de la recherche A* pour générer chaque ensemble de données de séquenceNavigation dans le labyrintheDans la première expérience, l'équipe s'est entraînée. un ensemble de modèles de transformateur encodeur-décodeur pour prédire le chemin optimal dans un labyrinthe 30×30
La figure 4 montre qu'en prédisant les étapes de calcul intermédiaires, des performances plus robustes peuvent être obtenues lorsque la quantité de données est faible.
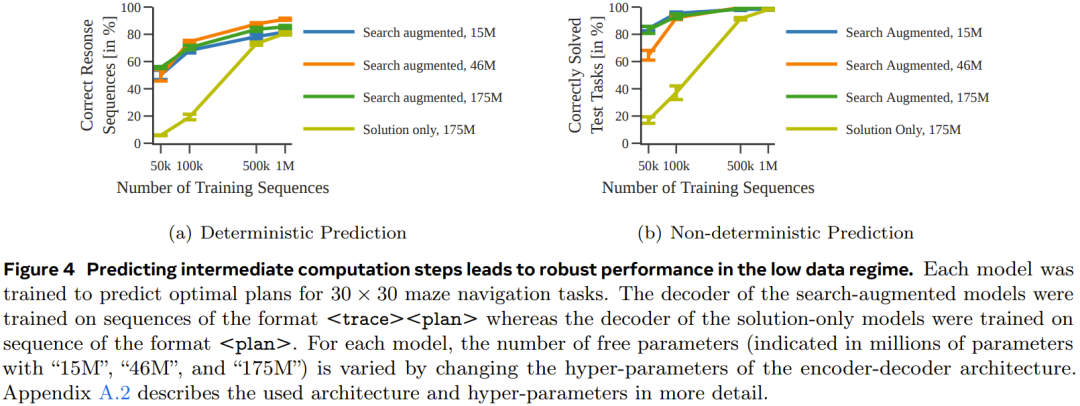
La figure 5 donne les performances du modèle entraîné en utilisant uniquement des solutions.
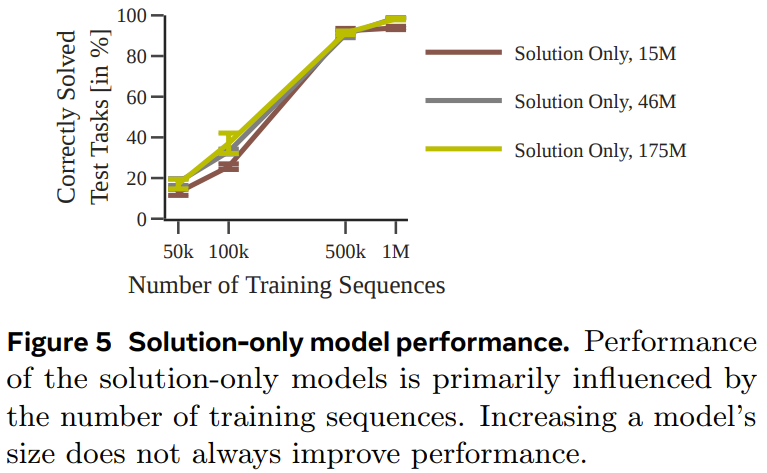
La figure 6 montre l'impact de la difficulté de la tâche sur les performances de chaque modèle.
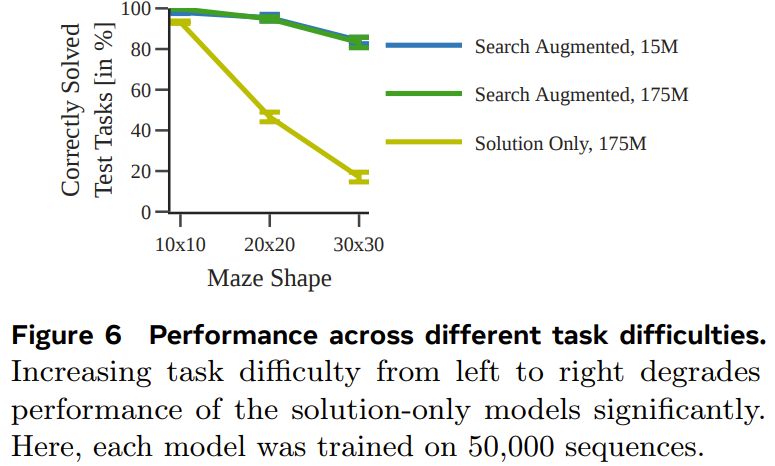
Dans l'ensemble, bien que le modèle entraîné en utilisant uniquement la solution puisse prédire le plan optimal lorsque l'ensemble de données d'entraînement utilisé est suffisamment grand et suffisamment diversifié, lorsque la quantité de données est petite, les performances du modèle amélioré par la recherche sont nettement meilleures. et s'adapte également mieux aux tâches plus difficiles.
Boîtes de poussée

Pour tester si des résultats similaires peuvent être obtenus sur des tâches différentes et plus complexes (avec différents modes de tokenisation), l'équipe a également généré un ensemble de données de planification de boîtes de poussée à des fins de test.
La figure 7 montre la probabilité que chaque modèle génère le plan correct pour chaque tâche de test.
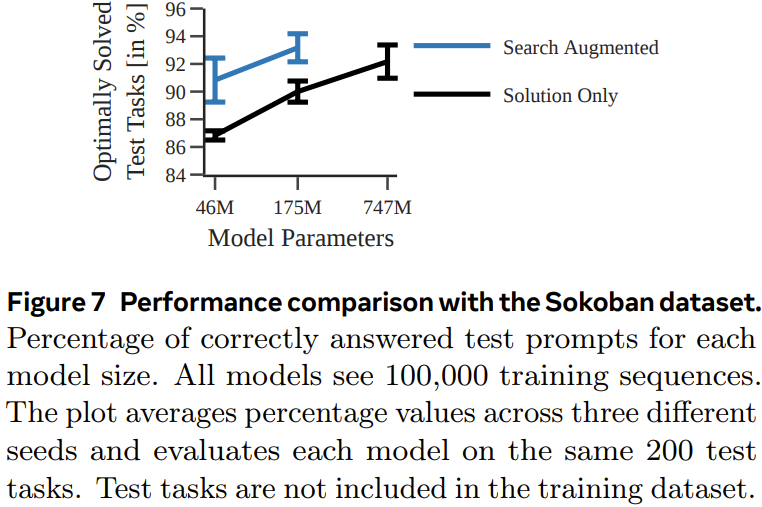
On peut voir que, comme l'expérience précédente, en s'entraînant à l'aide de traces d'exécution, le modèle amélioré par la recherche surpasse le modèle entraîné en utilisant uniquement des solutions.
Searchformer : améliorer la dynamique de recherche grâce au bootstrapping
En guise d'expérience finale, l'équipe a étudié comment les modèles améliorés par la recherche peuvent être améliorés de manière itérative pour calculer des plans optimaux avec moins d'étapes de recherche. Le but ici est de raccourcir la longueur de la trajectoire de recherche tout en obtenant la solution optimale.
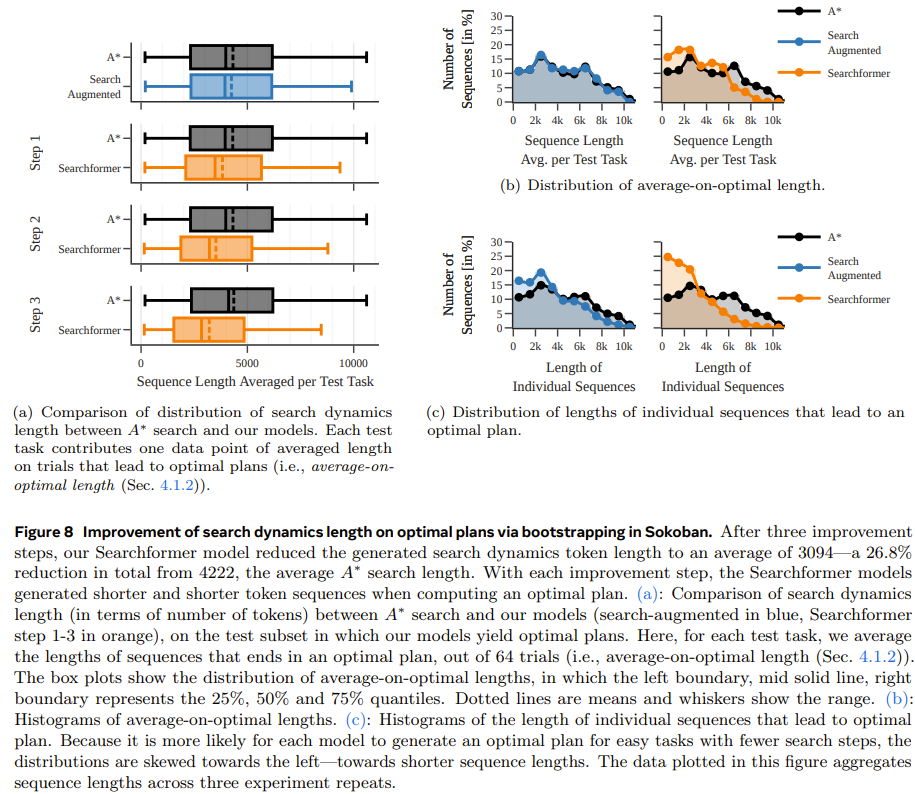
La figure 8 montre que la méthode de guidage dynamique de recherche nouvellement proposée peut raccourcir de manière itérative la longueur de la séquence générée par le modèle Searchformer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Renforcez l'industrie de la mode grâce à la technologie et aidez le district de Futian à construire un « centre de siège social de la mode dans la région de la Baie »
- En prenant l'« Exhibition Express », le parc industriel d'intelligence artificielle de Qingdao explore de nouvelles façons d'attirer les investissements
- Ronglian Cloud a été sélectionné dans la carte mondiale de l'industrie de l'IA générative 2023
- En se concentrant sur l'écosystème commercial numérique et l'industrie des métaverses, Lujiazui Digital Intelligence World s'efforce de créer un cluster industriel d'éléments de données.
- Robot ETF (159770) : Attirant des entrées nettes de capitaux pendant 4 jours consécutifs, les « Avis directeurs sur l'innovation et le développement des robots humanoïdes » peuvent promouvoir le processus de développement industriel