
Maison >Périphériques technologiques >IA >L'Université Tsinghua et Ideal ont proposé DriveVLM, un grand modèle de langage visuel pour améliorer les capacités de conduite autonome
L'Université Tsinghua et Ideal ont proposé DriveVLM, un grand modèle de langage visuel pour améliorer les capacités de conduite autonome

- 王林avant
- 2024-02-24 08:37:151047parcourir
Dans le domaine de la conduite autonome, les chercheurs explorent également l'orientation des grands modèles tels que GPT/Sora.
Par rapport à l'IA générative, la conduite autonome est également l'un des domaines de recherche et développement les plus actifs dans le domaine de l'IA récente. Un défi majeur dans la construction d'un système de conduite entièrement autonome est la compréhension de la scène par l'IA, qui implique des scénarios complexes et imprévisibles tels que des conditions météorologiques extrêmes, des tracés routiers complexes et un comportement humain imprévisible.
Le système de conduite autonome actuel se compose généralement de trois parties : la perception 3D, la prédiction de mouvement et la planification. Plus précisément, la perception 3D est principalement utilisée pour détecter et suivre des objets familiers, mais sa capacité à identifier des objets rares et leurs attributs est limitée, tandis que la prédiction et la planification de mouvements se concentrent principalement sur les actions de trajectoire des objets, mais ignorent généralement la relation entre les objets et les véhicules. . interactions au niveau décisionnel entre Ces limitations peuvent affecter la précision et la sécurité des systèmes de conduite autonome lors de la gestion de scénarios de trafic complexes. Par conséquent, la future technologie de conduite autonome doit être encore améliorée pour mieux identifier et prédire différents types d'objets, et pour planifier plus efficacement la trajectoire de conduite du véhicule afin d'améliorer l'intelligence et la fiabilité du système
La clé pour parvenir à une conduite autonome L'objectif est transformer une approche basée sur les données en une approche basée sur les connaissances, ce qui nécessite de former de grands modèles dotés de capacités de raisonnement logique. Ce n'est qu'ainsi que le système de conduite autonome pourra véritablement résoudre le problème de la longue traîne et évoluer vers les capacités L4. Actuellement, alors que des modèles à grande échelle tels que GPT4 et Sora continuent d'émerger, l'effet d'échelle a également démontré de puissantes capacités de tir à peu de tirs/zéro tir, ce qui a conduit les gens à envisager une nouvelle direction de développement.
Le dernier document de recherche provient du Tsinghua University Cross Information Institute et de Li Auto, dans lequel ils présentent un nouveau modèle appelé DriveVLM. Ce modèle s'inspire du modèle de langage visuel (VLM) émergeant dans le domaine de l'intelligence artificielle générative. DriveVLM a démontré d'excellentes capacités en matière de compréhension visuelle et de raisonnement.
Ce travail est le premier dans l'industrie à proposer un système de contrôle de la vitesse de conduite autonome. Sa méthode combine pleinement le processus de conduite autonome traditionnel avec un processus de modèle à grande échelle doté de capacités de réflexion logique, et c'est la première fois qu'un grand projet est déployé avec succès. -maquette à l'échelle d'un terminal pour tests (basé sur la plateforme Orin).
DriveVLM couvre un processus de Chain-of-Though (CoT), comprenant trois modules principaux : description du scénario, analyse du scénario et planification hiérarchique. Dans le module de description de scène, le langage est utilisé pour décrire l'environnement de conduite et identifier les objets clés de la scène ; le module d'analyse de scène étudie en profondeur les caractéristiques de ces objets clés et leur impact sur les véhicules autonomes tandis que le module de planification hiérarchique formule progressivement des plans à partir de les éléments Les actions et les décisions sont décrites par des waypoints.
Ces modules correspondent aux étapes de perception, de prédiction et de planification des systèmes de conduite autonome traditionnels, mais la différence est qu'ils gèrent la perception des objets, la prédiction au niveau de l'intention et la planification au niveau des tâches, qui ont été très difficiles dans le passé.
Bien que les VLM fonctionnent bien en compréhension visuelle, ils ont des limites en termes de base spatiale et de raisonnement, et leurs besoins en puissance de calcul posent des défis en termes de vitesse de raisonnement final. Par conséquent, les auteurs proposent en outre DriveVLMDual, un système hybride qui combine les avantages de DriveVLM et des systèmes traditionnels. DriveVLM-Dual intègre en option DriveVLM aux modules traditionnels de perception et de planification 3D tels que les détecteurs d'objets 3D, les réseaux d'occupation et les planificateurs de mouvement, permettant au système d'atteindre des capacités de mise à la terre 3D et de planification haute fréquence. Cette conception à double système est similaire aux processus de réflexion lents et rapides du cerveau humain et peut s'adapter efficacement aux différentes complexités des scénarios de conduite.
La nouvelle recherche clarifie également la définition des tâches de compréhension et de planification de scène (SUP) et propose de nouvelles mesures d'évaluation pour évaluer les capacités de DriveVLM et DriveVLM-Dual en matière d'analyse de scène et de planification de méta-actions. En outre, les auteurs ont effectué un travail approfondi d’exploration de données et d’annotation pour créer un ensemble de données SUP-AD interne pour la tâche SUP.
Des expériences approfondies sur l'ensemble de données nuScenes et nos propres ensembles de données démontrent la supériorité de DriveVLM, notamment avec un petit nombre de prises de vue. De plus, DriveVLM-Dual surpasse les méthodes de planification de mouvement de bout en bout de pointe.
Article "DriveVLM : La convergence de la conduite autonome et des modèles de langage à grande vision"

Lien article : https://arxiv.org/abs/2402.12289
Lien du projet : https://tsinghua-mars- lab.github.io/DriveVLM/
Le processus global de DriveVLM est illustré dans la figure 1 :
Encoder des images visuelles à cadre continu, interagir avec LMM via le module d'alignement des fonctionnalités
Démarrer à partir de la description de la scène Guider le ; en pensant au modèle VLM, en guidant d'abord les scènes statiques telles que le temps, la scène, l'environnement de la voie, etc., puis en guidant les principaux obstacles qui affectent les décisions de conduite
-
Analysez les principaux obstacles et faites-les correspondre grâce à la détection 3D traditionnelle et les obstacles compris par VLM, confirment davantage l'efficacité des obstacles et éliminent les illusions, décrivent les caractéristiques des obstacles clés de cette scène et leur impact sur notre conduite
; Donne des "méta-décisions" clés, telles que ralentir, se garer, tourner à gauche et à droite, etc., puis donne une description de la stratégie de conduite basée sur les méta-décisions, et enfin donne la future trajectoire de conduite de le véhicule hôte.
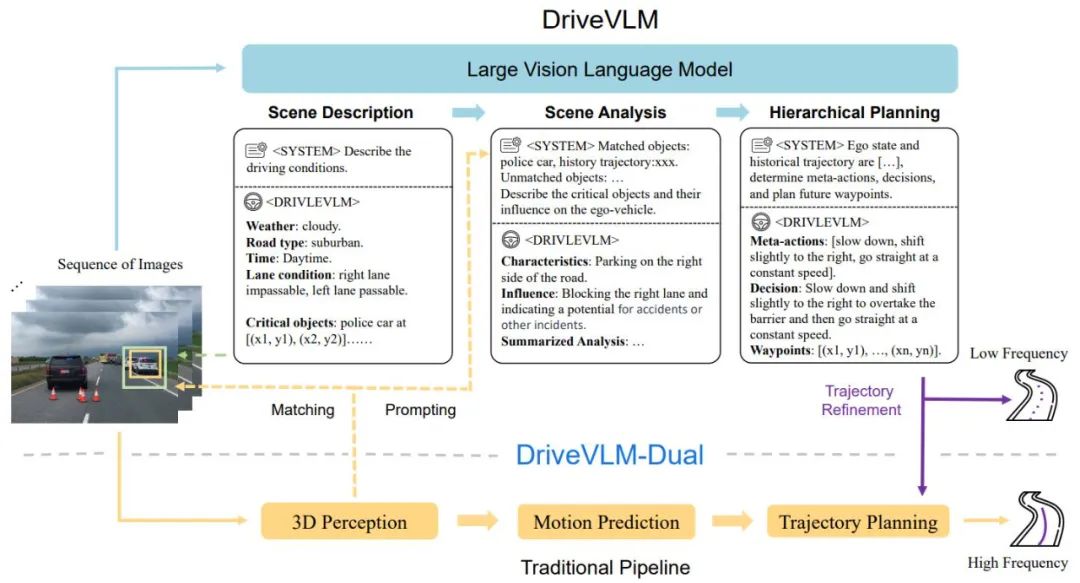
Figure 1. Pipeline des modèles DriveVLM et DriveVLM-Dual. Une séquence d'images est traitée par un grand modèle de langage visuel (VLM) pour effectuer un raisonnement spécial en chaîne de pensée (CoT) afin d'en dériver des résultats de planification de conduite. Le grand VLM implique un encodeur de transformateur visuel et un grand modèle de langage (LLM). Un encodeur visuel produit des balises d'image ; un extracteur basé sur l'attention aligne ensuite ces balises avec un LLM et enfin, le LLM effectue une inférence CoT ; Le processus CoT peut être divisé en trois modules : description du scénario, analyse du scénario et planification hiérarchique.
DriveVLM-Dual est un système hybride qui utilise la compréhension globale de DriveVLM de l'environnement et les suggestions de trajectoires de décision pour améliorer les capacités de prise de décision et de planification du pipeline de conduite autonome traditionnel. Il intègre les résultats de la perception 3D dans des signaux verbaux pour améliorer la compréhension de la scène 3D et affine davantage les points de cheminement de la trajectoire avec un planificateur de mouvement en temps réel.
Bien que les VLM soient efficaces pour identifier les objets à longue traîne et comprendre des scènes complexes, ils ont souvent du mal à comprendre avec précision l'emplacement spatial et l'état de mouvement détaillé des objets, une lacune qui pose un défi important. Pour aggraver les choses, la taille énorme du modèle VLM entraîne une latence élevée, ce qui entrave la capacité de réponse en temps réel de la conduite autonome. Pour relever ces défis, l'auteur propose DriveVLM-Dual, qui permet à DriveVLM et aux systèmes de conduite autonomes traditionnels de coopérer. Cette nouvelle approche implique deux stratégies clés : l'analyse d'objets clés combinée à la perception 3D pour fournir des informations de décision de conduite en haute dimension, et un raffinement de trajectoire à haute fréquence.
De plus, pour exploiter pleinement le potentiel de DriveVLM et DriveVLMDual dans la gestion de scénarios de conduite complexes et à longue traîne, les chercheurs ont formellement défini une tâche appelée planification de compréhension de scène, ainsi qu'un ensemble de mesures d'évaluation. De plus, les auteurs proposent un protocole d’exploration de données et d’annotation pour gérer les ensembles de données de compréhension et de planification des scènes.
Afin d'entraîner complètement le modèle, l'auteur a récemment développé un ensemble d'outils d'annotation et de solutions d'annotation Drive LLM grâce à une combinaison d'exploration automatisée, de pré-brossage d'algorithmes de perception, de résumé de grand modèle GPT-4 et d'annotation manuelle. Le modèle actuel a été formé. Avec ce schéma d'annotation efficace, chaque donnée Clip contient des dizaines de contenus d'annotation.

L'auteur a également proposé un pipeline complet d'exploration de données et d'annotation, comme le montre la figure 3, pour créer un ensemble de données de compréhension de scène pour la planification en conduite autonome (SUP-AD) pour la tâche proposée, contenant plus de 100 000 images et plus de 1 000 000 images. paires de textes. Plus précisément, les auteurs effectuent d’abord une exploration d’objets à longue traîne et une exploration de scènes difficiles à partir d’une grande base de données pour collecter des échantillons, puis sélectionnent une image clé de chaque échantillon et effectuent ensuite une annotation de scène.
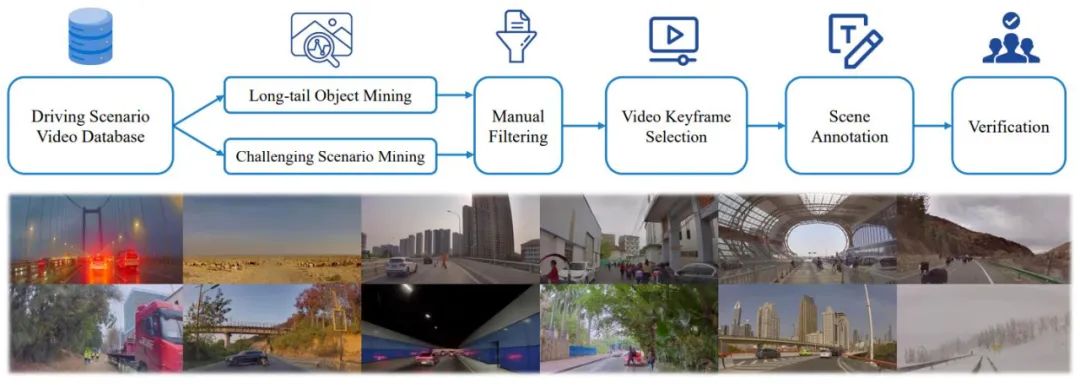
Figure 3. Pipeline d'exploration de données et d'annotation pour créer une compréhension de scénarios et planifier des ensembles de données (ci-dessus). Des exemples de scénarios échantillonnés aléatoirement à partir de l’ensemble de données (ci-dessous) démontrent la diversité et la complexité de l’ensemble de données.
SUP-AD est divisé en parties de formation, de vérification et de test, avec un ratio de 7,5 : 1 : 1,5. Les auteurs entraînent le modèle sur la répartition de formation et utilisent la description de scène et les métriques de méta-action nouvellement proposées pour évaluer les performances du modèle sur la répartition validation/test.
L'ensemble de données nuScenes est un ensemble de données de conduite de scènes urbaines à grande échelle avec 1 000 scènes, chacune d'une durée d'environ 20 secondes. Les images clés sont annotées uniformément à 2 Hz sur l’ensemble de l’ensemble de données. Ici, les auteurs adoptent l'erreur de déplacement (DE) et le taux de collision (CR) comme indicateurs pour évaluer les performances du modèle en matière de segmentation de vérification.
Les auteurs démontrent les performances de DriveVLM avec plusieurs modèles de langage visuel à grande échelle et les comparent avec GPT-4V, comme le montre le tableau 1. DriveVLM utilise Qwen-VL comme épine dorsale, qui atteint les meilleures performances par rapport aux autres VLM open source et se caractérise par une réactivité et une interaction flexible. Les deux premiers grands modèles ont été open source et ont utilisé les mêmes données pour affiner la formation. GPT-4V utilise des invites complexes pour une ingénierie rapide.
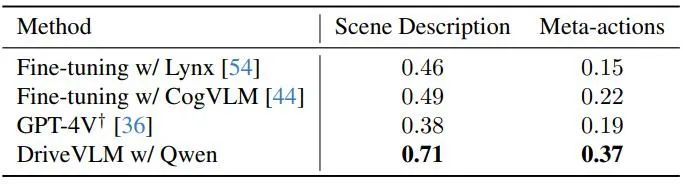
Tableau 1. Résultats de l'ensemble de tests sur l'ensemble de données SUP-AD. L'API officielle de GPT-4V est utilisée ici, et pour Lynx et CogVLM, les divisions de formation sont utilisées pour le réglage fin.
Comme le montre le tableau 2, DriveVLM-Dual atteint des performances de pointe sur les tâches de planification nuScenes lorsqu'il est associé à VAD. Cela montre que la nouvelle méthode, bien que conçue pour comprendre des scènes complexes, fonctionne également bien dans les scènes ordinaires. Notez que DriveVLM-Dual s'améliore considérablement par rapport à UniAD : l'erreur moyenne de déplacement de planification est réduite de 0,64 mètres et le taux de collision est réduit de 51 %.
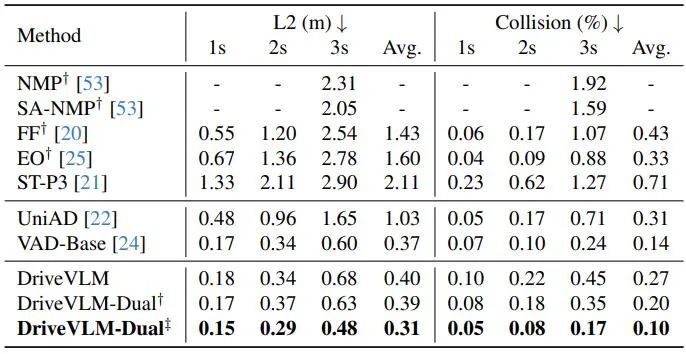
Tableau 2. Résultats de la planification pour l'ensemble de données de validation nuScenes. DriveVLM-Dual atteint des performances optimales. †Représente les résultats de perception et de prévision d'occupation à l'aide d'Uni-AD. ‡ Indique le travail avec VAD, où tous les modèles prennent les états du moi en entrée. Figure 4. Résultats qualitatifs de DriveVLM. La courbe orange représente la trajectoire future prévue du modèle au cours des 3 prochaines secondes. 
. -Figure 9. Concentration des données Sup-AD des grappes et troupeaux de vaches. Un troupeau de bovins se déplace lentement devant la voiture, ce qui oblige la politique à raisonner sur le fait que la voiture se déplace lentement et à garder une distance de sécurité avec le bétail. Figure 16. Visualisation de la sortie DriveVLM. DriveVLM peut détecter avec précision les arbres tombés et leur emplacement, puis planifier un détour approprié.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Où est l'adresse de la World VR Industry Conference ?
- La Corée du Sud a annoncé qu'elle investirait 500 milliards de wons au cours des cinq prochaines années pour soutenir l'industrie clé de la technologie de l'IA.
- Comment les robots collaboratifs peuvent-ils permettre la fabrication intelligente et la modernisation de l'industrie chimique quotidienne ? Écoutez ce que disent les experts
- Liu Qiang : Construire la prochaine génération d'écosystème de contenu industriel du métaverse du tourisme culturel sur Internet
- Le développement rapide du système d'exploitation Hongmeng sur divers appareils ouvrira une nouvelle industrie valant des milliards