
Maison >Périphériques technologiques >IA >Générez 25 images d'animation de haute qualité en deux étapes, calculées comme 8 % de SVD. Jouable en ligne
Générez 25 images d'animation de haute qualité en deux étapes, calculées comme 8 % de SVD. Jouable en ligne

- PHPzavant
- 2024-02-20 15:54:161040parcourir
Les ressources informatiques consommées ne représentent que 2/25 du modèle traditionnel de diffusion vidéo stable(SVD) !
AnimateLCM-SVD-xt est publié, modifiant le modèle de diffusion vidéo pour le débruitage répété, ce qui prend du temps et nécessite beaucoup de calculs.
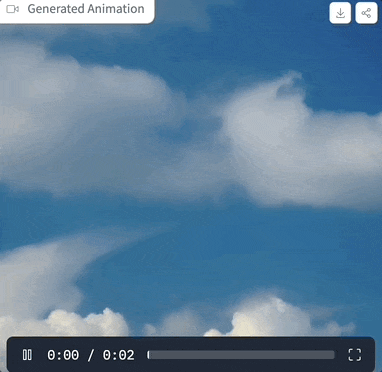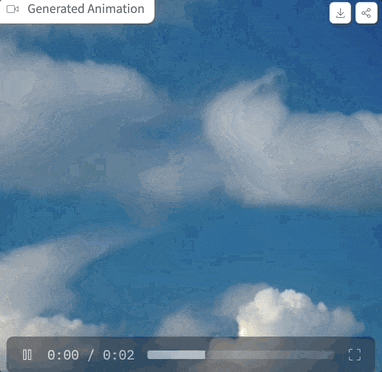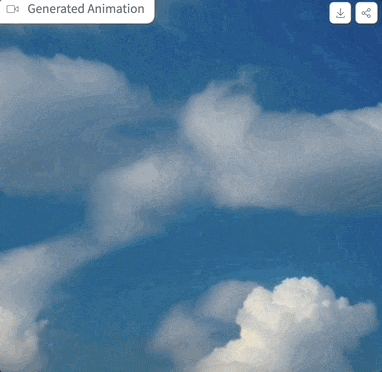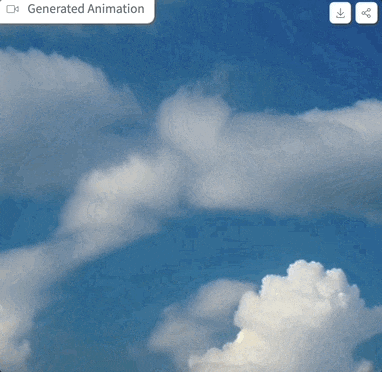
Regardons d'abord l'effet d'animation généré.
Le style cyberpunk est facile à contrôler, le garçon porte des écouteurs, debout dans la rue néon de la ville :
 Photos
Photos
Un style réaliste peut également être utilisé, un couple de jeunes mariés se blottit ensemble, tenant un bouquet exquis, dans Soyez témoin de l'amour sous l'ancien mur de pierre :
 image
image
Style de science-fiction, et ressentez également l'invasion extraterrestre de la terre :
 image
image
AnimateLCM-SVD-xt de MMLab, The Chinese Université de Hong Kong, proposé conjointement par des chercheurs d'Avolution AI, du Shanghai Artificial Intelligence Laboratory et du SenseTime Research Institute.
 images
images
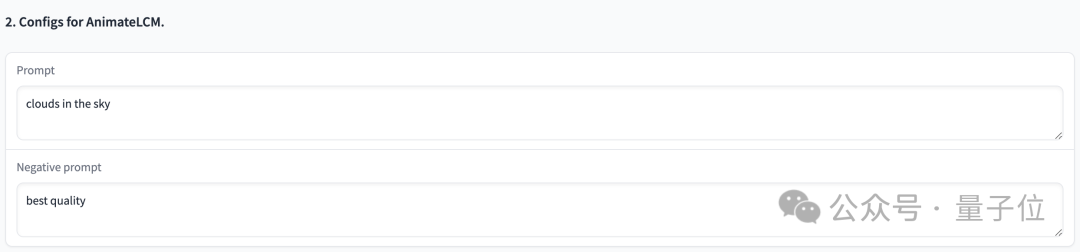
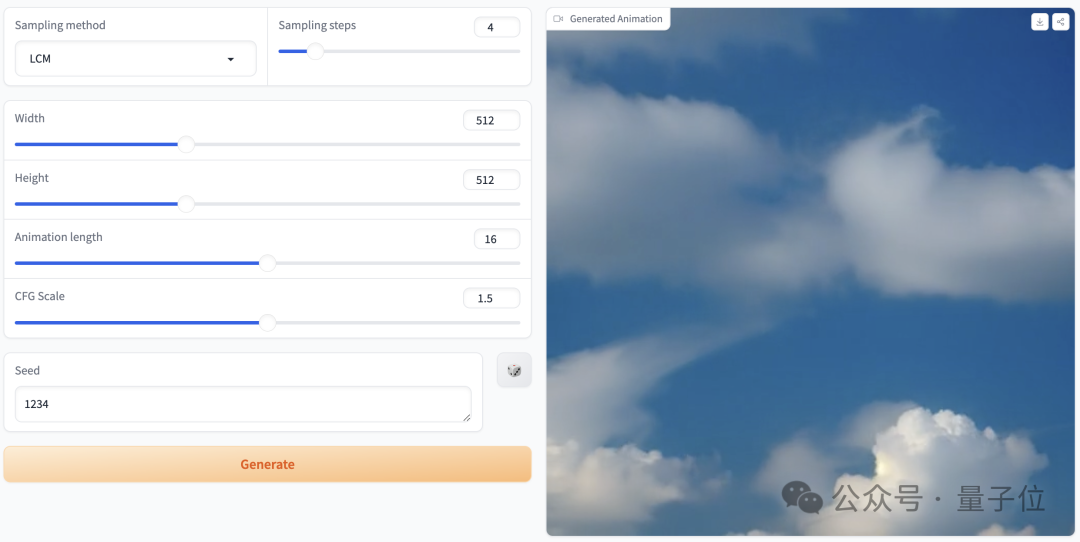
Vous pouvez générer des animations de haute qualité avec 25 images et une résolution de 576x1024 en 2 à 8 étapes, et sans guidage du classificateur
, la vidéo générée en 4 étapes peut atteindre une haute fidélité, ce qui est mieux que le SVD traditionnel Plus rapide et plus efficace : Photos
Photos
 Photos
Photos
 Images
Images
 Images
Images
 Images
Images
 photo
photo
 Photos
Photos
 images
images
 images.
images.
 photos
photos
 Photos
Photos
Comment faire ?
Sachez que bien que les modèles de diffusion vidéo reçoivent une attention croissante en raison de leur capacité à générer des vidéos cohérentes et haute fidélité, l'une des difficultés est que le processus de débruitage itératif prend non seulement du temps mais également des ressources informatiques, ce qui le limite. champ d'application.
Dans ce travail AnimateLCM, les chercheurs se sont inspirés du modèle de cohérence (CM), qui simplifie le modèle de diffusion d'images pré-entraîné pour réduire les étapes requises pour l'échantillonnage et met à l'échelle avec succès le modèle de cohérence latente de génération d'images conditionnelles (LCM ) .
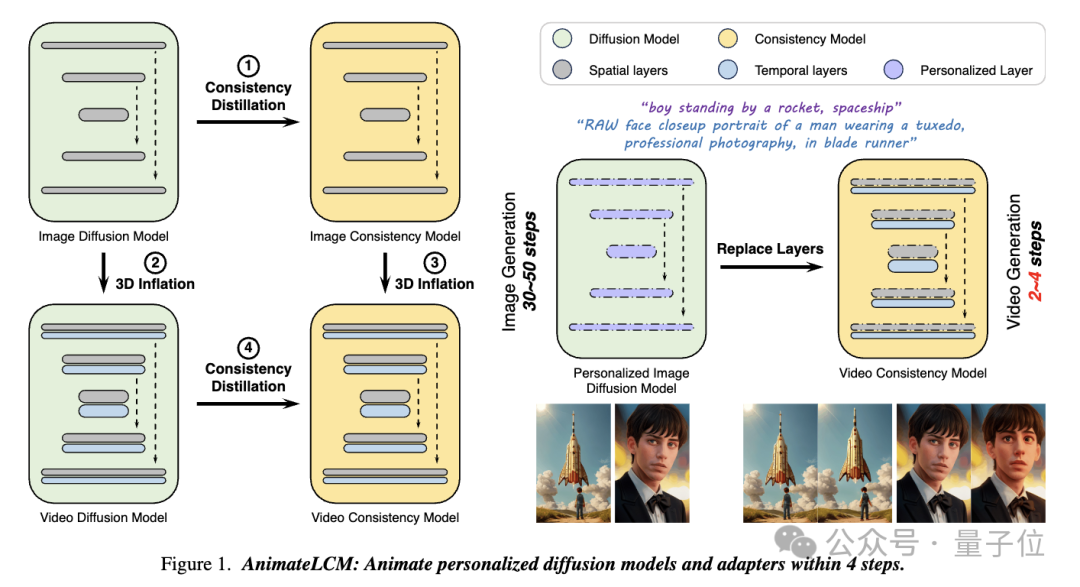 Picture
Picture
Plus précisément, les chercheurs ont proposé une stratégie d'Apprentissage de cohérence découplée(Apprentissage de cohérence découplée).
Distillez d'abord le modèle de diffusion stable en un modèle de cohérence d'image sur un ensemble de données image-texte de haute qualité, puis effectuez une distillation de cohérence sur les données vidéo pour obtenir un modèle de cohérence vidéo. Cette stratégie améliore l'efficacité de la formation en formant séparément aux niveaux spatial et temporel.
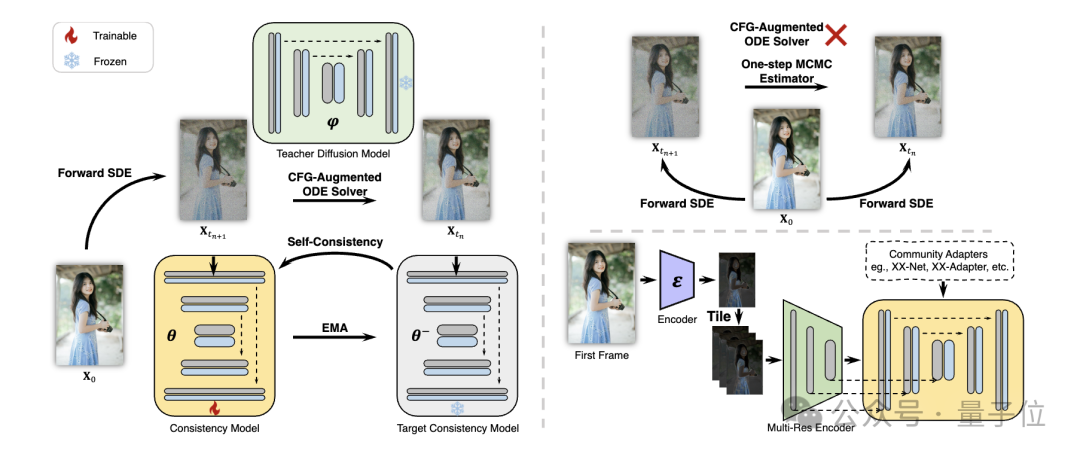 Pictures
Pictures
De plus, afin de mettre en œuvre diverses fonctions d'adaptateurs plug-and-play (par exemple, utiliser ControlNet pour réaliser une génération contrôlable) dans la communauté Stable Diffusion, les chercheurs ont également proposé Teacher- Adaptez gratuitement la stratégie (Adaptation sans enseignant) pour rendre l'adaptateur de contrôle existant plus cohérent avec le modèle de cohérence et obtenir une génération vidéo mieux contrôlable.
 Photos
Photos
Des expériences quantitatives et qualitatives prouvent l'efficacité de la méthode.
Dans la tâche de génération de texte en vidéo sans prise de vue sur l'ensemble de données UCF-101, AnimateLCM obtient les meilleures performances sur les métriques FVD et CLIPSIM.
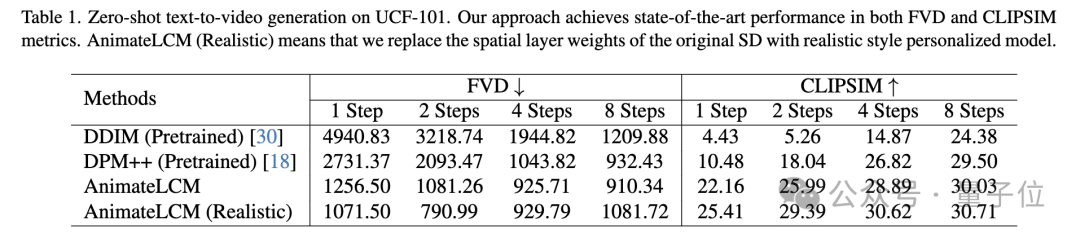 Picture
Picture
 Picture
Picture
Une étude d'ablation vérifie l'efficacité de l'apprentissage par cohérence découplée et des stratégies d'initialisation spécifiques :
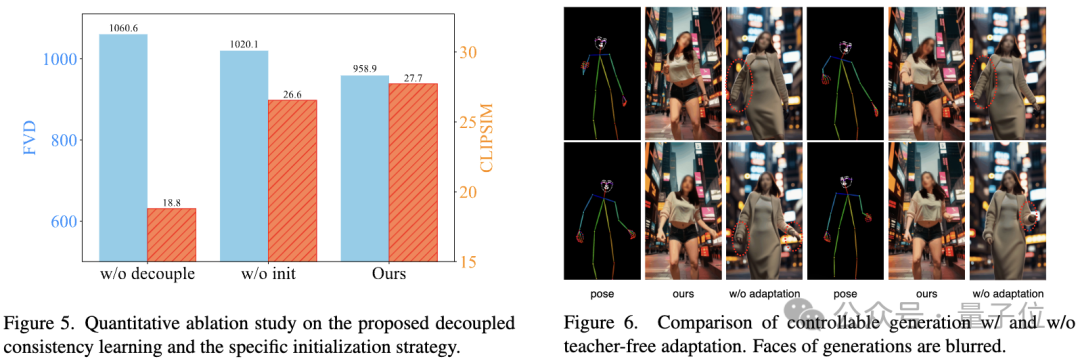 Picture
Picture
Lien du projet :
[1]https:// animatel cm. github.io/
[2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment implémenter une animation de rotation CSS
- Comment annuler l'alarme de l'ordinateur
- À quoi fait généralement référence la capacité de mémoire d'un ordinateur ?
- Unité centrale de traitement (CPU) Quel est le centre de commande de l'ensemble de l'ordinateur ?
- Comment résoudre le problème de l'absence d'utilisateurs et de groupes locaux dans la gestion informatique