
Maison >Périphériques technologiques >IA >Quel est le décodage spéculatif que GPT-4 pourrait également utiliser ? Un article résumant les situations passées, présentes et applicatives
Quel est le décodage spéculatif que GPT-4 pourrait également utiliser ? Un article résumant les situations passées, présentes et applicatives

- 王林avant
- 2024-02-20 15:45:02982parcourir
Il est bien connu que l'inférence de grands modèles de langage (LLM) nécessite généralement l'utilisation d'un échantillonnage autorégressif, et ce processus d'inférence est assez lent. Pour résoudre ce problème, le décodage spéculatif est devenu une nouvelle méthode d’échantillonnage pour l’inférence LLM. À chaque étape d'échantillonnage, cette méthode prédira d'abord plusieurs jetons possibles, puis vérifiera s'ils sont précis en parallèle. Contrairement au décodage autorégressif, le décodage spéculatif peut décoder plusieurs jetons en une seule étape, accélérant ainsi l'inférence.
Bien que le décodage spéculatif présente un grand potentiel à bien des égards, il soulève également certaines questions clés qui nécessitent des recherches approfondies. Tout d’abord, nous devons réfléchir à la manière de sélectionner ou de concevoir un modèle approximatif approprié pour trouver un équilibre entre l’exactitude de la conjecture et l’efficacité de la génération. Deuxièmement, il est important de garantir que les critères d’évaluation préservent à la fois la diversité et la qualité des résultats générés. Enfin, l’alignement du processus d’inférence entre le modèle approximatif et le grand modèle cible doit être soigneusement étudié pour améliorer la précision de l’inférence.
Des chercheurs de l'Université polytechnique de Hong Kong, de l'Université de Pékin, de la MSRA et d'Alibaba ont mené une enquête complète sur le décodage spéculatif, et Machine Heart en a fait un résumé complet. Titre de la thèse U : Déverrouiller l'efficacité de l'inférence de modèles de langage à grande échelle : une étude complète du décodage spéculatif
F 
- L'évolution du décodage spéculatif
- L'article détaille d'abord les premières recherches sur la technologie de décodage spéculatif et montre son processus de développement à travers une chronologie (voir Figure 2).
- Le décodage par blocs est une méthode d'intégration de têtes neuronales à action directe (FFN) supplémentaires sur le décodeur Transformer, qui peut générer plusieurs jetons en une seule étape.
Afin d'exploiter pleinement le potentiel de l'algorithme d'échantillonnage par blocs, une solution de décodage spéculatif est proposée. Cet algorithme couvre un modèle approximatif indépendant, utilisant généralement un transformateur non autorégressif spécialisé, capable d'effectuer des tâches de génération de manière efficace et précise.
Après l'émergence du décodage spéculatif, certains chercheurs ont alors proposé « l'algorithme d'échantillonnage spéculatif », qui ajoutait un échantillonnage de noyau accéléré sans perte au décodage spéculatif.
Dans l'ensemble, ces tentatives innovantes de décodage spéculatif ont commencé à renforcer le paradigme Draftthen-Verify et démontrent un grand potentiel dans l'accélération du LLM.
Formules et définitions
Cette section décrit d'abord brièvement le contenu du décodage autorégressif standard, puis développe en profondeur l'algorithme de décodage spéculatif, y compris une description complète de la définition formelle, de la méthodologie, et les détails de l'algorithme.
Cet article propose un cadre organisationnel pour classer les recherches connexes, comme le montre la figure 3 ci-dessous. 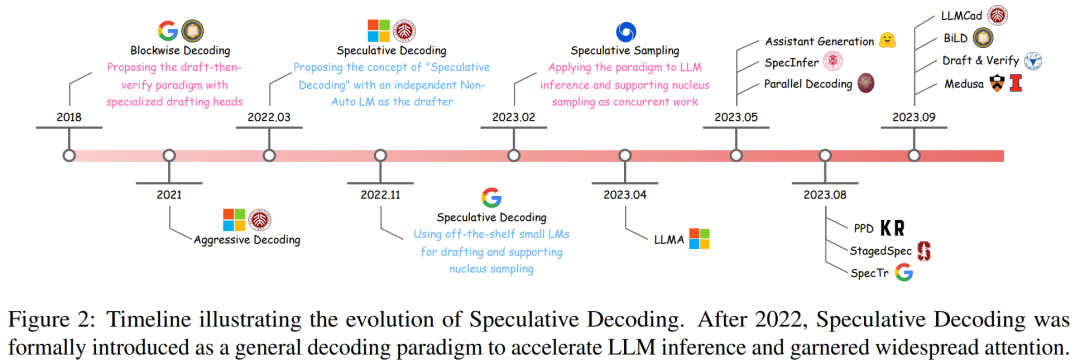
Sur la base des travaux précédents, cet article définit à nouveau formellement « l'algorithme de décodage spéculatif » :
L'algorithme de décodage spéculatif est un mode de décodage qui est d'abord généré puis vérifié dans cette étape, il doit d'abord être capable de générer plusieurs jetons possibles, puis d'utiliser le grand modèle de langage cible pour évaluer tous ces jetons en parallèle afin d'accélérer l'inférence. Le tableau d'algorithmes 2 est un processus de décodage spéculatif détaillé.

Ensuite, cet article se penche sur les deux sous-étapes fondamentales qui font partie intégrante de ce paradigme : la génération et l'évaluation.
Générer

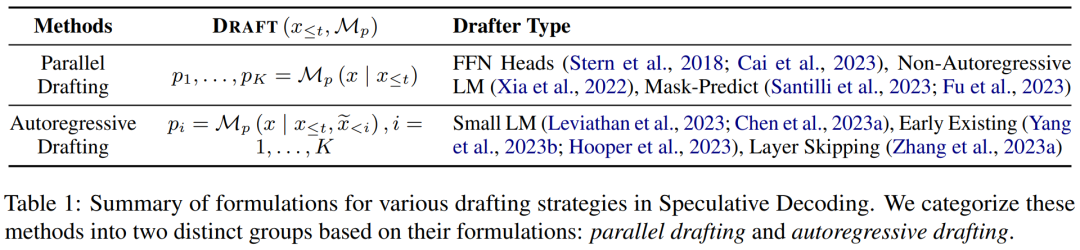
À chaque étape de décodage, l'algorithme de décodage spéculatif génère d'abord plusieurs jetons possibles en tant que spéculations sur le contenu de sortie du grand modèle de langage cible.
Cet article divise le contenu généré en deux catégories : rédaction indépendante et auto-rédaction, et résume ses formules dans le tableau 1 ci-dessous.
Validation
Dans chaque étape de décodage, les jetons générés par le modèle approximatif sont vérifiés en parallèle pour garantir que la qualité de sortie est hautement cohérente avec le grand modèle de langage cible. Ce processus détermine également le nombre de jetons autorisés à chaque étape, un facteur important qui peut affecter l'accélération.
Un résumé des divers critères de validation est présenté dans le tableau 2 ci-dessous, y compris ceux qui prennent en charge le décodage glouton et l'échantillonnage du noyau dans l'inférence de grands modèles de langage.

Les sous-étapes de génération et de vérification continuent de s'itérer jusqu'à ce que la condition de terminaison soit remplie, c'est-à-dire que le jeton [EOS] soit décodé ou que la phrase atteigne la longueur maximale.
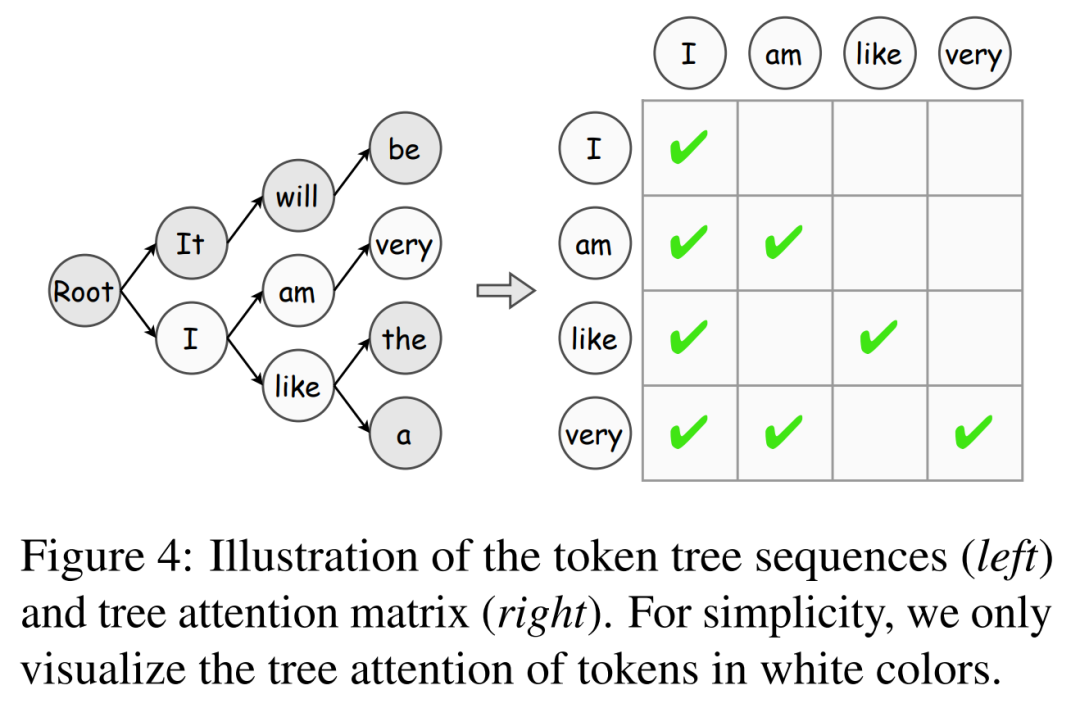
De plus, cet article présente l'algorithme de vérification de l'arbre de jetons, qui est une stratégie efficace pour augmenter progressivement l'acceptation des jetons.
Alignement du modèle
L'amélioration de la précision de la spéculation est essentielle pour accélérer le décodage spéculatif : plus le comportement prédit du modèle approximatif est proche du grand modèle de langage cible, plus le taux d'acceptation de ses jetons générés est élevé. À cette fin, les travaux existants explorent diverses stratégies d'extraction de connaissances (KD) pour aligner le contenu de sortie du modèle approximatif avec celui du grand modèle de langage cible.
Le décodage bloqué utilise d'abord l'extraction de connaissances au niveau de la séquence (Seq-KD) pour l'alignement du modèle et entraîne le modèle approximatif avec des phrases générées par le grand modèle de langage cible.
De plus, Seq-KD est également une stratégie efficace pour améliorer la qualité de la génération de décodage parallèle, améliorant ainsi les performances de génération du décodage parallèle.
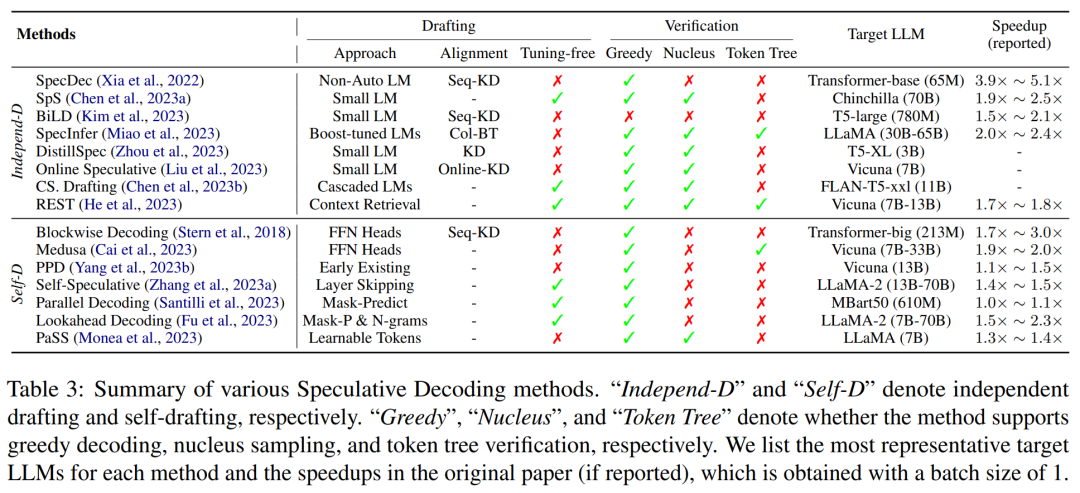
Les principales caractéristiques des méthodes de décodage spéculatif existantes sont résumées dans le tableau 3 ci-dessous, y compris le type de modèle approximatif ou de stratégie de génération, la méthode d'alignement du modèle, la stratégie d'évaluation prise en charge et le degré d'accélération.
Applications
En plus d'être un paradigme général, des travaux récents ont montré que certaines variantes du décodage spéculatif présentent une efficacité extraordinaire dans des tâches spécifiques. En outre, d’autres recherches ont appliqué ce paradigme pour résoudre des problèmes de latence propres à certains scénarios d’application, obtenant ainsi une accélération de l’inférence.
Par exemple, certains chercheurs pensent que le décodage spéculatif est particulièrement adapté aux tâches où l'entrée et la sortie du modèle sont très similaires, telles que la correction des erreurs grammaticales et la génération d'améliorations de récupération.
En plus de ces travaux, RaLMSpec (Zhang et al., 2023b) utilise le décodage spéculatif pour accélérer la récupération de modèles de langage augmentés (RaLM).
Opportunités et défis
Question 1 : Comment évaluer l'exactitude et l'efficacité de la génération du contenu prédit ? Bien que certains progrès aient été réalisés sur ce problème, il reste encore beaucoup à faire pour aligner les modèles approximatifs sur ce que génère le grand modèle de langage cible. Outre l’alignement du modèle, d’autres facteurs tels que la qualité de la génération et la détermination de la longueur des prévisions affectent également l’exactitude des prévisions et méritent une exploration plus approfondie.
Question 2 : Comment combiner le décodage spéculatif avec d'autres technologies de pointe ? En tant que mode de décodage général, le décodage spéculatif a été combiné avec d’autres technologies avancées pour démontrer son potentiel. En plus d’accélérer les grands modèles de langage pour le texte brut, l’application du décodage spéculatif au raisonnement multimodal, tel que la synthèse d’images, la synthèse texte-parole et la génération de vidéos, constitue également une direction intéressante et précieuse pour les recherches futures.
Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- À quoi fait référence le modèle Python IPO ?
- Quels sont les trois modèles de données de base de données courants ?
- Quel est le modèle OSI
- Bard a été formé sur les données ChatGPT ? Les meilleurs scientifiques de Google ont protesté en vain et ont quitté OpenAI
- En tête de la liste internationale faisant autorité en matière d'analyse sémantique conversationnelle SParC et CoSQL, le nouveau modèle de pré-formation des connaissances sur les tables de dialogue à plusieurs tours, interprétation STAR