
Maison >Périphériques technologiques >IA >Grand modèle gaussien multi-vues LGM : produit des objets 3D de haute qualité en 5 secondes, disponible en version d'essai
Grand modèle gaussien multi-vues LGM : produit des objets 3D de haute qualité en 5 secondes, disponible en version d'essai

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-20 15:10:19796parcourir
En réponse à la croissance continue de la demande d'outils de création 3D dans le métaverse, les gens ont récemment manifesté un grand intérêt pour la génération de contenu tridimensionnel (3D AIGC). Dans le même temps, la création de contenu 3D a également fait des progrès significatifs en termes de qualité et de rapidité.
Bien que les modèles génératifs à feed-forward actuels puissent générer des objets 3D en quelques secondes, leur résolution est limitée par le calcul intensif requis lors de la formation, ce qui entraîne la génération de contenu de faible qualité. Cela soulève la question suivante : un objet 3D haute résolution et de haute qualité peut-il être généré en seulement 5 secondes ?

Dans cet article, des chercheurs de l'Université de Pékin, du S-Lab de l'Université technologique de Nanyang et du Laboratoire d'intelligence artificielle de Shanghai ont proposé un nouveau cadre LGM, à savoir le grand modèle gaussien, qui réalise la transformation d'images à vue unique à partir de Ou la saisie de texte pour générer des objets tridimensionnels de haute résolution et de haute qualité en seulement 5 secondes.
Actuellement, les poids du code et du modèle sont open source. Les chercheurs proposent également une démo en ligne que tout le monde peut essayer.

- Titre de l'article : LGM : Grand modèle gaussien multi-vues pour la création de contenu 3D haute résolution
- Page d'accueil du projet : https://me.kiui.moe/lgm/
- Code : https://github.com/3DTopia/LGM
- Paper : https://arxiv.org/abs/2402.05054
- Démo en ligne : https://huggingface.co/spaces/ashawkey/LGM
Pour atteindre un tel objectif, les chercheurs sont confrontés aux deux défis suivants :
- Représentation 3D efficace avec un montant de calcul limité : Les travaux de génération 3D existants utilisent NeRF basé sur trois plans comme représentation et rendu 3D. pipeline, sa modélisation intensive des scènes et sa technologie de rendu de volume par lancer de rayons limitent considérablement sa résolution d'entraînement (128 × 128), rendant la texture du contenu final généré floue et de mauvaise qualité.
- Réseau de génération de base 3D à haute résolution : Les travaux de génération 3D existants utilisent des transformateurs denses comme réseau de base pour garantir une quantité de paramètres suffisamment dense pour modéliser des objets universels, mais cela est sacrifié dans une certaine mesure. La résolution de formation entraîne une mauvaise qualité de l’objet tridimensionnel final.
À cette fin, cet article propose une nouvelle méthode pour synthétiser des représentations tridimensionnelles haute résolution à partir d'images à quatre vues, puis utiliser le texte existant pour une image multi-vue ou une image unique pour des modèles d'image multi-vues. . Prend en charge les tâches Text-to-3D et Image-to-3D de haute qualité .
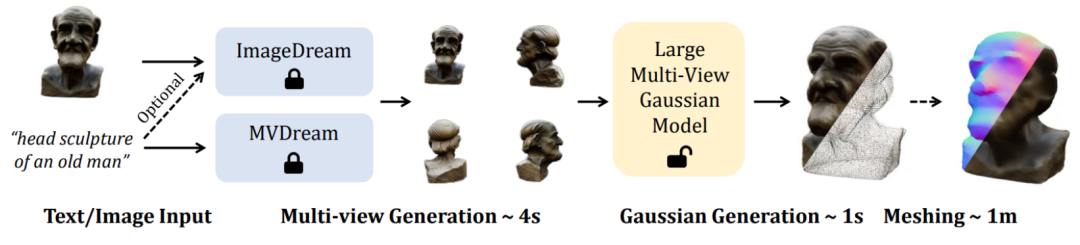
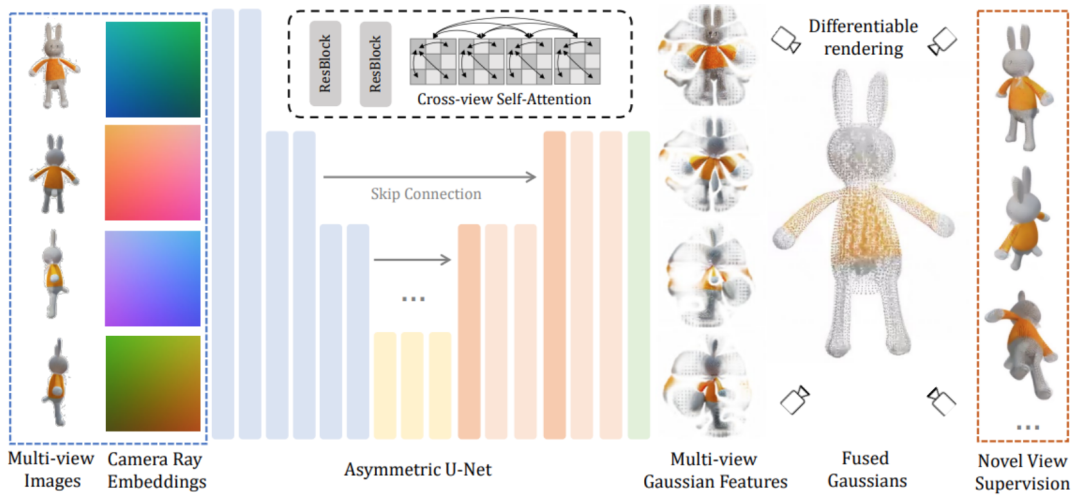
Techniquement, Le module principal LGM est un grand modèle gaussien multi-vues. Inspirée de la pulvérisation gaussienne, cette méthode utilise un U-Net asymétrique efficace et léger comme réseau principal pour prédire directement les primitives gaussiennes haute résolution à partir d'images à quatre vues, et enfin restituer les images sous n'importe quel angle de vue.
Plus précisément, le réseau fédérateur U-Net accepte des images de quatre perspectives et les coordonnées de Plucker correspondantes, et génère un nombre fixe de caractéristiques gaussiennes depuis plusieurs perspectives. Cet ensemble de caractéristiques gaussiennes est directement fusionné dans l'élément gaussien final et des images sous différents angles de vision sont obtenues grâce à un rendu différenciable.
Dans ce processus, un mécanisme d'auto-attention à vues croisées est utilisé pour implémenter une modélisation de corrélation entre différentes vues sur des cartes de caractéristiques basse résolution tout en maintenant une faible surcharge de calcul.
Il est à noter qu'il n'est pas facile d'entraîner efficacement un tel modèle à haute résolution. Pour parvenir à une formation solide, les chercheurs sont toujours confrontés aux deux problèmes suivants.
Premièrement, les images multi-vues cohérentes tridimensionnelles rendues dans l'ensemble de données objaverse sont utilisées dans la phase de formation, tandis que dans la phase d'inférence, les modèles existants sont directement utilisés pour synthétiser des images multi-perspectives à partir de texte ou d'images. Étant donné que les images multi-vues synthétisées sur la base du modèle présentent toujours le problème de l'incohérence multi-vues, afin de combler le fossé dans ce domaine, cet article propose une stratégie d'amélioration des données basée sur la distorsion de la grille : appliquer la randomisation aux images de trois vues. dans l'espace image Distorsion pour simuler l'incohérence multi-vues.
Deuxièmement, parce que les images multi-vues générées lors de l'étape d'inférence ne garantissent pas strictement la cohérence de la géométrie tridimensionnelle de la perspective de la caméra, cet article perturbe également aléatoirement les poses de caméra des trois perspectives pour simuler ce phénomène. , afin que le modèle puisse mieux raisonner. La scène est plus stable .
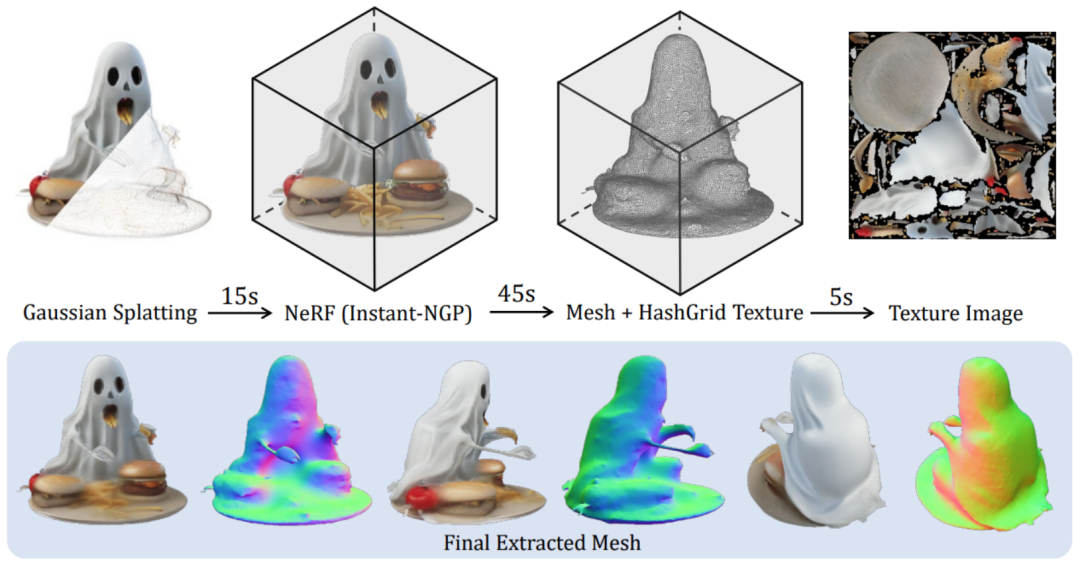
Enfin, les primitives gaussiennes générées sont restituées en images correspondantes via un rendu différentiable, et apprises directement de bout en bout sur les images bidimensionnelles grâce à un apprentissage supervisé.Une fois la formation terminée, LGM peut réaliser des tâches de texte en 3D et d'image en 3D de haute qualité grâce au modèle de diffusion image vers multi-vues ou texte vers multi-vues existant.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment implémenter la fonction contain dans les chaînes python
- Qu'est-ce que la technologie de l'IA ?
- La veille de l'AIGC produisant du contenu pour le Metaverse
- Pour aider au développement de l'industrie Yuanverse, ce concours d'applications innovantes de communication mobile a été lancé
- L'AIGC remodèle l'écologie du contenu du métaverse, Baidu Xirang a inauguré le moment du « grand modèle »