
Maison >Périphériques technologiques >IA >Le modèle RNN défie l'hégémonie des Transformers ! 1 % de coût et des performances comparables à celles du Mistral-7B, prenant en charge plus de 100 langues, le plus grand nombre au monde
Le modèle RNN défie l'hégémonie des Transformers ! 1 % de coût et des performances comparables à celles du Mistral-7B, prenant en charge plus de 100 langues, le plus grand nombre au monde

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-19 21:30:39936parcourir
Alors que de grands modèles sont déployés, le statut de Transformer est également remis en question les uns après les autres.
Récemment, RWKV a publié le modèle Eagle 7B, basé sur la dernière architecture RWKV-v5.
Eagle 7B excelle dans les benchmarks multilingues et est à égalité avec les meilleurs modèles dans les tests d'anglais.
Dans le même temps, Eagle 7B utilise une architecture RNN Par rapport au modèle Transformer de même taille, le coût d'inférence est réduit de plus de 10 à 100 fois. On peut dire qu'il s'agit du 7B le plus respectueux de l'environnement. modèle au monde.
Étant donné que l'article sur RWKV-v5 ne sera peut-être pas publié avant le mois prochain, nous fournissons d'abord l'article sur RWKV, qui est la première architecture non Transformer à adapter les paramètres à des dizaines de milliards.
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2305.13048.pdf
EMNLP 2023 a accepté ce travail. Les auteurs viennent des meilleures universités, instituts de recherche et technologies du monde entier. entreprise mondiale.
Ce qui suit est la photo officielle d'Eagle 7B, qui montre que cet aigle survole Transformers.
 Photos
Photos
Eagle 7B
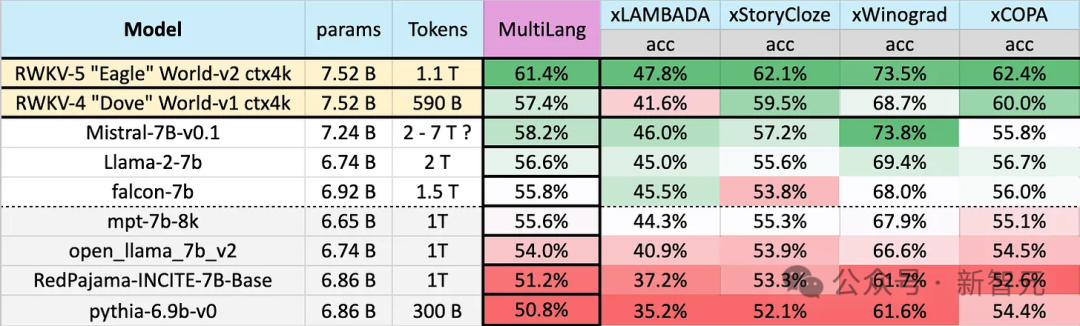
Eagle 7B utilise des données d'entraînement de 1,1T (billion) de jetons provenant de plus de 100 langues dans le test de référence multilingue ci-dessous, Eagle 7B se classe en moyenne en premier.
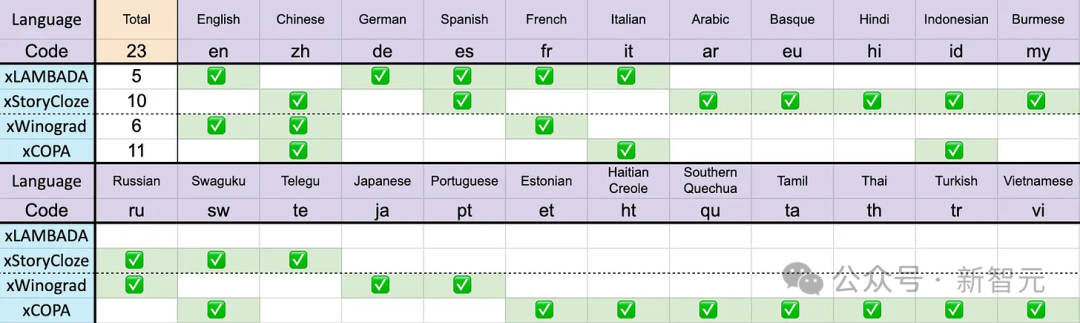
Les benchmarks incluent xLAMBDA, xStoryCloze, xWinograd et xCopa, couvrant 23 langues, ainsi que le raisonnement de bon sens dans leurs langues respectives.
Eagle 7B a remporté la première place dans trois d'entre eux. Bien que l'un d'entre eux n'ait pas battu Mistral-7B et se soit classé deuxième, les données d'entraînement utilisées par l'adversaire étaient bien supérieures à celles d'Eagle.
 Photos
Photos
Le test d'anglais illustré ci-dessous contient 12 points de repère distincts, un raisonnement de bon sens et une connaissance du monde.
Dans le test de performance en anglais, le niveau d'Eagle 7B est proche de Falcon (1,5T), LLaMA2 (2T), Mistral (>2T) et est comparable à MPT-7B, qui utilise également environ 1T d'entraînement. données.
 Photos
Photos
Et, dans les deux tests, la nouvelle architecture v5 a fait un énorme bond en avant par rapport à la précédente v4.
Eagle 7B est actuellement hébergé par la Linux Foundation et est sous licence Apache 2.0 pour une utilisation personnelle ou commerciale sans restriction.
Support multilingue
Comme mentionné précédemment, les données de formation d'Eagle 7B proviennent de plus de 100 langues, tandis que les 4 benchmarks multilingues utilisés ci-dessus n'incluent que 23 langues.
 Photos
Photos
Bien qu'il ait obtenu la première place, en général, Eagle 7B a subi une perte. Après tout, le test de référence ne peut pas évaluer directement les performances du modèle dans plus de 70 autres langues.
Le coût supplémentaire de la formation ne vous aidera pas à améliorer votre classement. Si vous vous concentrez sur l'anglais, vous obtiendrez peut-être de meilleurs résultats qu'aujourd'hui.
——Alors, pourquoi RWKV fait-il ça ? Le responsable a déclaré :
Construire une IA inclusive pour tout le monde dans ce monde —— pas seulement pour les Anglais
Parmi les nombreux retours sur le modèle RWKV, le plus courant est :
L'approche multilingue nuit Le score d'évaluation en anglais du modèle a ralenti le développement du Transformer linéaire
Il est injuste de comparer les performances multilingues avec un modèle anglais pur
Déclaré officiellement : "Dans la plupart des cas, nous sommes d'accord avec ces avis,"
"Mais nous n'avons pas l'intention de changer cela, car nous construisons l'IA pour le monde - et ce n'est pas seulement un monde anglophone." L'anglais est parlé dans la population mondiale (environ 1,3 milliard de personnes), mais en prenant en charge les 25 principales langues du monde, le modèle peut atteindre environ 4 milliards de personnes, soit 50 % de la population mondiale.
 L'équipe espère que l'intelligence artificielle du futur pourra aider tout le monde, par exemple en permettant aux modèles de fonctionner sur du matériel bas de gamme à bas prix, par exemple en prenant en charge davantage de langues.
L'équipe espère que l'intelligence artificielle du futur pourra aider tout le monde, par exemple en permettant aux modèles de fonctionner sur du matériel bas de gamme à bas prix, par exemple en prenant en charge davantage de langues.
L'équipe étendra progressivement l'ensemble de données multilingues pour prendre en charge un plus large éventail de langues et étendra progressivement la couverture à 100 % des régions du monde, en veillant à ce qu'aucune langue ne soit oubliée.
Ensemble de données + architecture évolutive
Pendant le processus de formation du modèle, il convient de noter un phénomène :
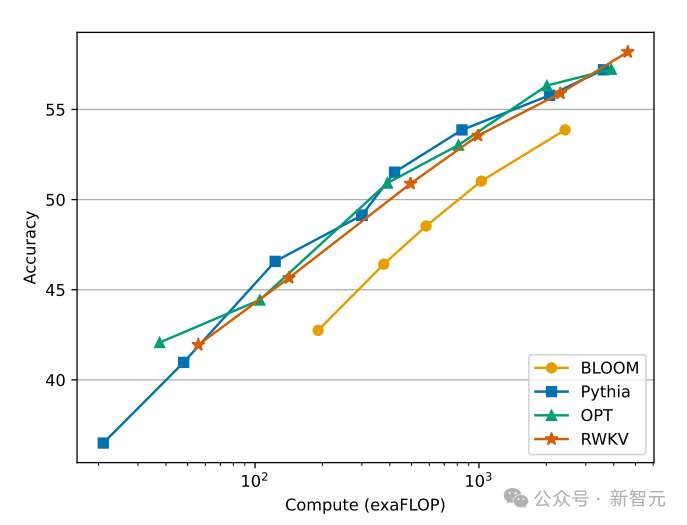
À mesure que l'échelle des données de formation continue d'augmenter, les performances du modèle s'améliorent progressivement. Lorsque les données d'entraînement atteignent environ 300 B, le modèle affiche des performances similaires à celles de python-6.9b, qui a une taille de données d'entraînement de 300 B.
Picture
Ce phénomène est le même qu'une expérience précédemment menée sur l'architecture RWKV-v4 - c'est-à-dire que lorsque la taille des données d'entraînement est la même, les performances d'un transformateur linéaire comme RWKV Ce sera similaire à Transformateur.
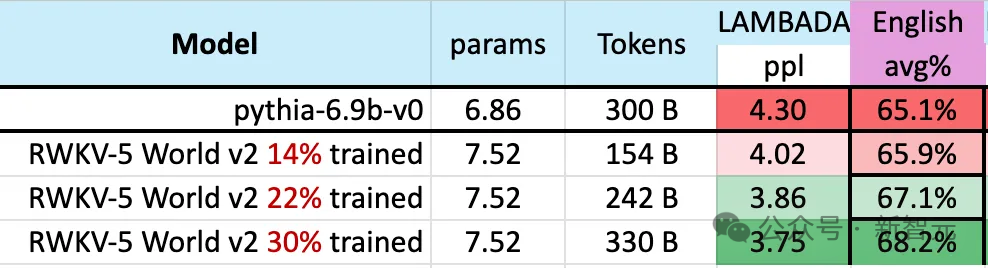 Nous ne pouvons donc pas nous empêcher de nous demander : si tel est effectivement le cas, les données sont-elles plus importantes pour l'amélioration des performances du modèle que l'architecture exacte ?
Nous ne pouvons donc pas nous empêcher de nous demander : si tel est effectivement le cas, les données sont-elles plus importantes pour l'amélioration des performances du modèle que l'architecture exacte ?
Photo
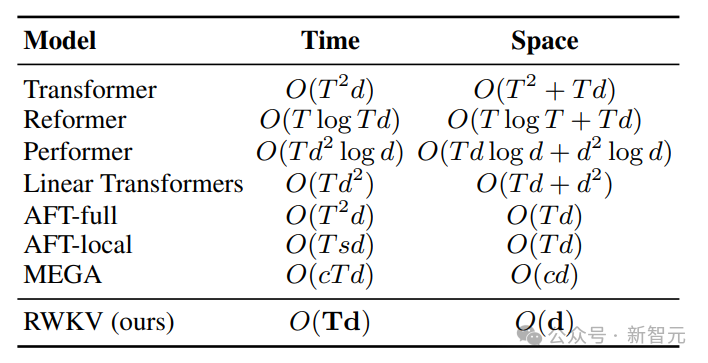
Nous savons que le coût de calcul et de stockage du modèle de classe Transformer est de niveau carré, alors que dans la figure ci-dessus, le coût de calcul de l'architecture RWKV n'augmente que linéairement avec le nombre de Tokens.
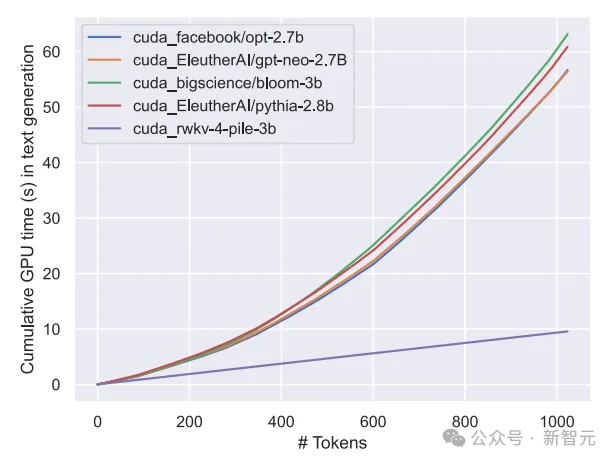 Peut-être devrions-nous nous tourner vers des architectures plus efficaces et évolutives pour accroître l'accessibilité, réduire le coût de l'IA pour tous et réduire l'impact environnemental.
Peut-être devrions-nous nous tourner vers des architectures plus efficaces et évolutives pour accroître l'accessibilité, réduire le coût de l'IA pour tous et réduire l'impact environnemental.
RWKV
L'architecture RWKV est un RNN avec des performances LLM de niveau GPT, tout en pouvant être formé en parallèle comme Transformer.
RWKV combine les avantages de RNN et Transformer - excellentes performances, inférence rapide, formation rapide, sauvegarde de la VRAM, longueur de contexte "illimitée" et intégration de phrases gratuite. RWKV n'utilise pas le mécanisme d'attention.
La figure suivante montre la comparaison des coûts de calcul entre les modèles RWKV et Transformer :
Photos
Afin de résoudre les problèmes de complexité temporelle et spatiale de Transformer, les chercheurs ont proposé diverses architectures :
 Picture
Picture
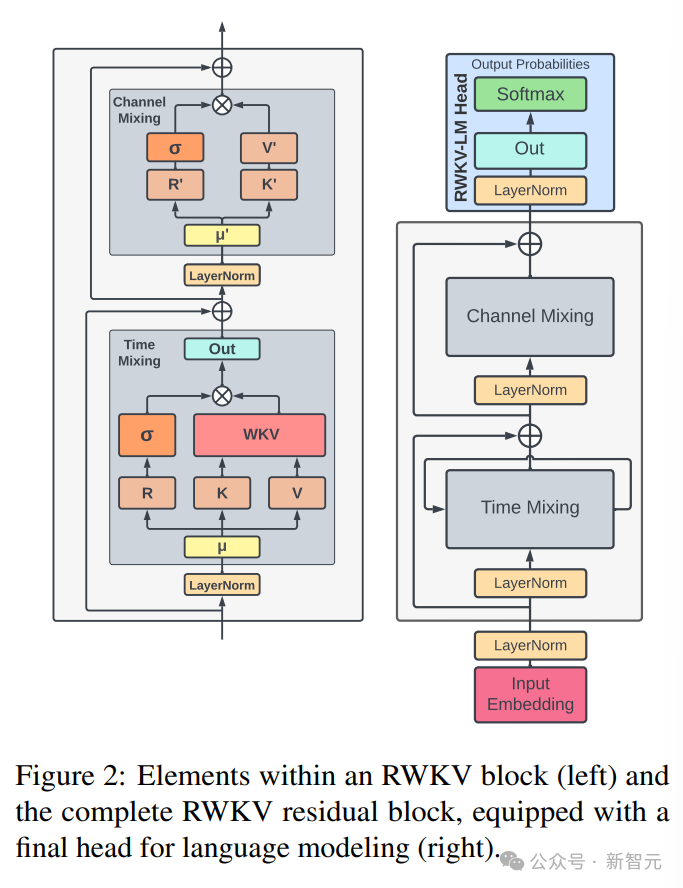
L'architecture RWKV se compose d'une série de blocs résiduels empilés. Chaque bloc résiduel se compose d'un sous-bloc de mélange temporel et d'un sous-bloc de mélange de canaux avec une structure en boucle
 Le côté gauche du L'image ci-dessous représente les éléments du bloc RWKV, avec le bloc résiduel RWKV à droite et l'en-tête final pour la modélisation du langage.
Le côté gauche du L'image ci-dessous représente les éléments du bloc RWKV, avec le bloc résiduel RWKV à droite et l'en-tête final pour la modélisation du langage.
Picture
La récursion peut être exprimée comme une interpolation linéaire entre l'entrée actuelle et l'entrée du pas de temps précédent (comme le montre la ligne diagonale dans la figure ci-dessous), qui peut être indépendante pour chaque linéaire projection de l'intégration d'entrée Ajustement.
 Un vecteur qui gère le jeton actuel séparément est également introduit ici pour compenser la dégradation potentielle.
Un vecteur qui gère le jeton actuel séparément est également introduit ici pour compenser la dégradation potentielle.
 Images
Images
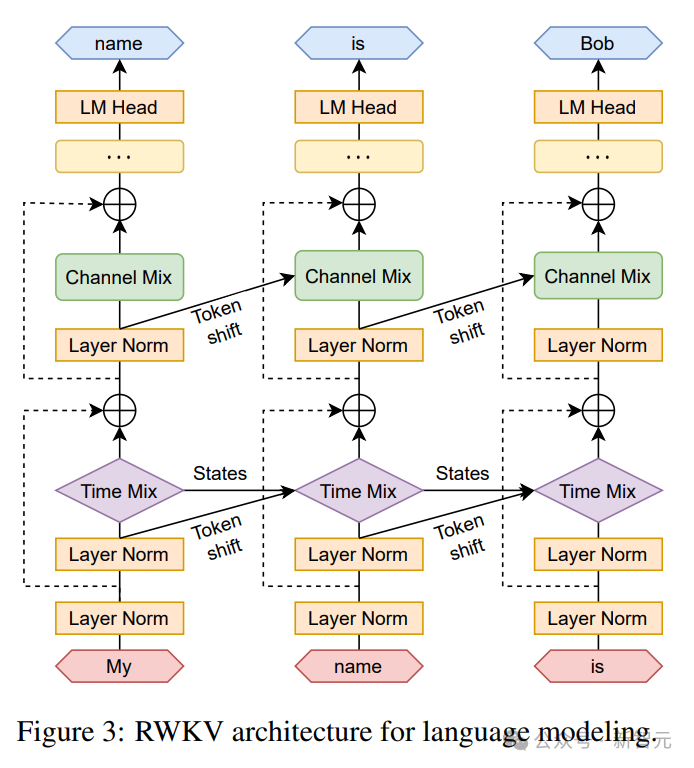
RWKV peut être efficacement parallélisé (multiplication matricielle) dans ce que nous appelons le mode de parallélisme temporel.
Dans un réseau récurrent, la sortie du moment précédent est généralement utilisée comme entrée du moment actuel. Cela est particulièrement évident dans l'inférence de décodage autorégressif pour les modèles de langage, qui nécessite que chaque jeton soit calculé avant de saisir l'étape suivante, permettant à RWKV de tirer parti de sa structure de type RNN, appelée mode temporel.
Dans ce cas, RWKV peut être facilement formulé de manière récursive pour le décodage lors de l'inférence. Il tire parti de chaque jeton de sortie en s'appuyant uniquement sur le dernier état. La taille de l'état est constante, contrairement à la longueur de la séquence.
agit ensuite comme un décodeur RNN, produisant une vitesse et une empreinte mémoire constantes par rapport à la longueur de la séquence, permettant de traiter plus efficacement des séquences plus longues.
En revanche, le cache KV de l'auto-attention augmente continuellement par rapport à la longueur de la séquence, ce qui entraîne une diminution de l'efficacité et une augmentation de l'empreinte mémoire et du temps à mesure que la séquence s'allonge.
Référence :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée des problèmes de blocage et d'utilisation de la mémoire du mot-clé synchronisé en Java
- À quelle couche du modèle de référence OSI correspond la couche de transport du modèle de référence TCP/IP ?
- Combien de types de modèles de boîtes CSS existe-t-il ?
- Comment utiliser des stratégies de mise en cache pour réduire l'empreinte mémoire des programmes PHP ?