
Maison >Périphériques technologiques >IA >Le nouveau SOTA de Vincent Tu ! Pika, l'Université de Pékin et Stanford lancent conjointement un RPG multimodal pour aider à résoudre deux problèmes majeurs de Wenshengtu
Le nouveau SOTA de Vincent Tu ! Pika, l'Université de Pékin et Stanford lancent conjointement un RPG multimodal pour aider à résoudre deux problèmes majeurs de Wenshengtu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-19 09:06:14653parcourir
Récemment, l'Université de Pékin, Stanford et le populaire Pika Labs ont publié conjointement une étude qui a amélioré les capacités des graphiques vincentiens à grand modèle à un nouveau niveau.

Adresse papier : https://arxiv.org/pdf/2401.11708.pdf
Adresse code : https://github.com/YangLing0818/RPG-DiffusionMaster
Proposé par le auteur de l'article Une approche innovante est adoptée pour améliorer le cadre de génération/édition de texte en image en tirant parti des capacités d'inférence des grands modèles de langage multimodaux (MLLM).
En d'autres termes, cette méthode vise à améliorer les performances des modèles de génération de texte lors du traitement d'invites de texte complexes contenant plusieurs attributs, relations et objets.
Sans plus tarder, voici la photo :

Une fille twintail verte en robe orange est assise sur le canapé tandis qu'un bureau en désordre sous une grande fenêtre à gauche, un aquarium animé se trouve au en haut à droite du canapé, style réaliste.
Une fille avec deux queues de cheval vêtue d'une robe orange est assise sur le canapé. À côté de la grande fenêtre se trouve un bureau en désordre. Il y a un aquarium animé en haut à droite, la pièce. est un style réaliste.
Face à de multiples objets aux relations complexes, la structure de l'ensemble de l'image et la relation entre les personnes et les objets données par le modèle sont très raisonnables, faisant briller les yeux du spectateur.
Pour la même invite, jetons un coup d'œil aux performances des SDXL et DALL·E 3 de pointe actuels :

Jetons un coup d'œil au nouveau framework lorsqu'il vient lier plusieurs attributs à plusieurs objets Performance :

De gauche à droite, une fille européenne blonde en queue de cheval en chemise blanche, une fille africaine aux cheveux bruns bouclés en chemise bleue imprimée d'un oiseau, une jeune asiatique. un homme aux cheveux courts noirs en costume marche joyeusement sur le campus.
De gauche à droite, une fille européenne portant une chemise blanche avec une queue de cheval blonde, une fille africaine aux cheveux bruns bouclés portant une chemise bleue avec un oiseau imprimé dessus et une fille portant un costume, un jeune homme asiatique aux cheveux noirs courts marche joyeusement sur le campus.
Les chercheurs ont nommé ce cadre RPG (Recaption, Plan and Generate), en utilisant MLLM comme planificateur global pour décomposer le processus complexe de génération d'images en plusieurs tâches de génération plus simples au sein de sous-régions.
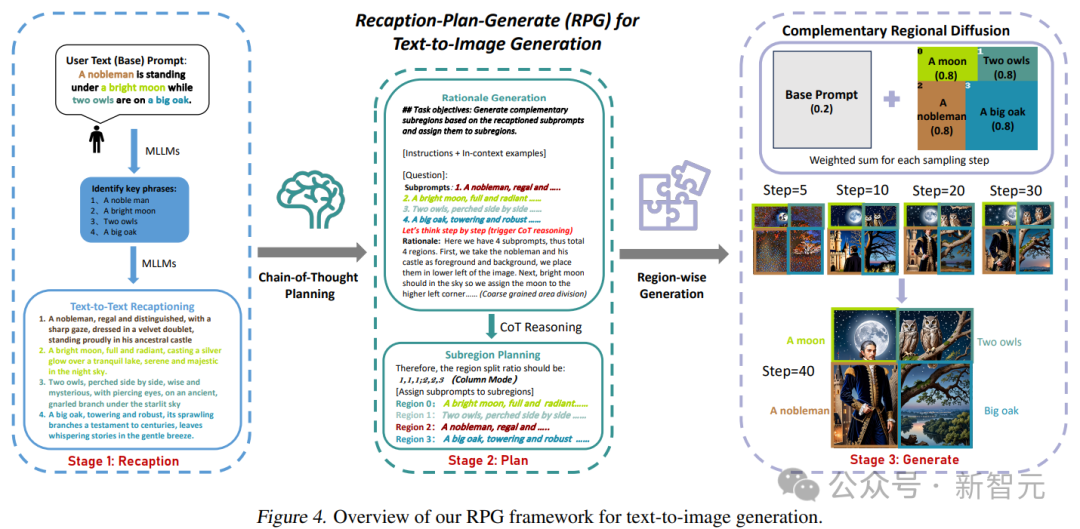
L'article propose une diffusion de régions complémentaire pour réaliser la génération de combinaisons de régions, et intègre également la génération et l'édition d'images guidées par texte dans le cadre RPG en boucle fermée, améliorant ainsi les capacités de généralisation.
Les expériences montrent que le cadre RPG proposé dans cet article surpasse les modèles de diffusion d'images texte de pointe actuels, notamment DALL·E 3 et SDXL, en particulier dans la synthèse d'objets multi-catégories et l'alignement sémantique d'images texte.
Il convient de noter que le framework RPG est largement compatible avec diverses architectures MLLM (telles que MiniGPT-4) et réseaux fédérateurs de diffusion (tels que ControlNet).
RPG
Le modèle de graphe vincentien actuel présente deux problèmes principaux : 1. Les méthodes basées sur la mise en page ou basées sur l'attention ne peuvent fournir qu'un guidage spatial approximatif et ont des difficultés à gérer les objets qui se chevauchent ; 2. Les méthodes basées sur les commentaires nécessitent une collecte ; des données de feedback de haute qualité et encourent des coûts de formation supplémentaires.
Pour résoudre ces problèmes, les chercheurs ont proposé trois stratégies de base du RPG, comme le montre la figure ci-dessous :
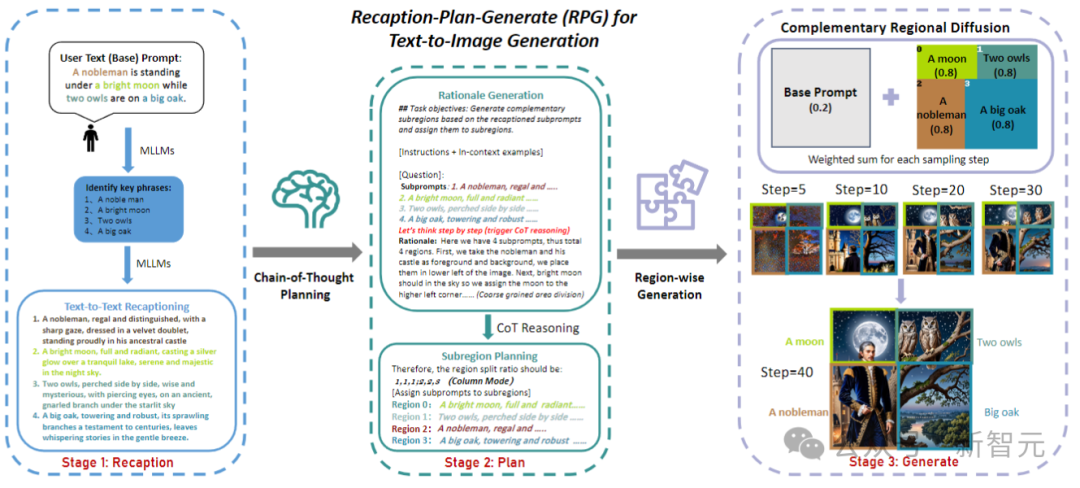
Étant donné une invite de texte complexe contenant plusieurs entités et relations, utilisez d'abord MLLM pour la décomposer en des indices de base et des sous-indices hautement descriptifs ; ensuite, l'espace d'image est divisé en sous-régions complémentaires à l'aide de la planification CoT du modèle multimodal ; enfin, une diffusion de régions complémentaires est introduite pour générer indépendamment l'image de chaque sous-région ; L'agrégation est effectuée à chaque étape d'échantillonnage.
Réajustement multimodal
transforme les signaux textuels en signaux hautement descriptifs, offrant ainsi une compréhension améliorée des signaux et un alignement sémantique dans les modèles de diffusion.
Utilisez MLLM pour identifier les phrases clés dans l'invite utilisateur et obtenir les sous-éléments qu'elle contient :
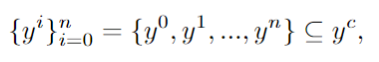
Utilisez LLM pour décomposer l'invite de texte en différentes sous-invites et les décrire plus en détail :
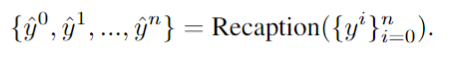
De cette manière, des détails plus denses et plus fins peuvent être générés pour chaque sous-repère afin d'améliorer efficacement la fidélité des images générées et de réduire les différences sémantiques entre les repères et les images.
Planification de la chaîne de pensée
divise l'espace de l'image en sous-régions complémentaires et attribue différents sous-indices à chaque sous-région, tout en décomposant la tâche de génération en plusieurs sous-tâches plus simples.
Plus précisément, l'espace image H×W est divisé en plusieurs régions complémentaires, et chaque invite d'amélioration est attribuée à une région spécifique R :
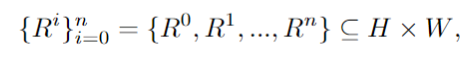
En utilisant la puissante capacité de raisonnement en chaîne de pensée de MLLM, effectuez zonage efficace. En analysant les résultats intermédiaires récupérés, des principes détaillés et des instructions précises peuvent être générés pour la synthèse d'images ultérieure.
Diffusion de zone supplémentaire
Dans chaque sous-zone rectangulaire, le contenu guidé par des sous-zones est généré indépendamment, puis redimensionné et connecté de manière à fusionner spatialement ces sous-zones.
Cette méthode résout efficacement le problème des grands modèles ayant des difficultés à gérer des objets qui se chevauchent. En outre, l'article étend ce cadre pour l'adapter aux tâches d'édition, en utilisant la diffusion de régions basée sur les contours pour opérer avec précision sur les régions incohérentes qui nécessitent une modification.
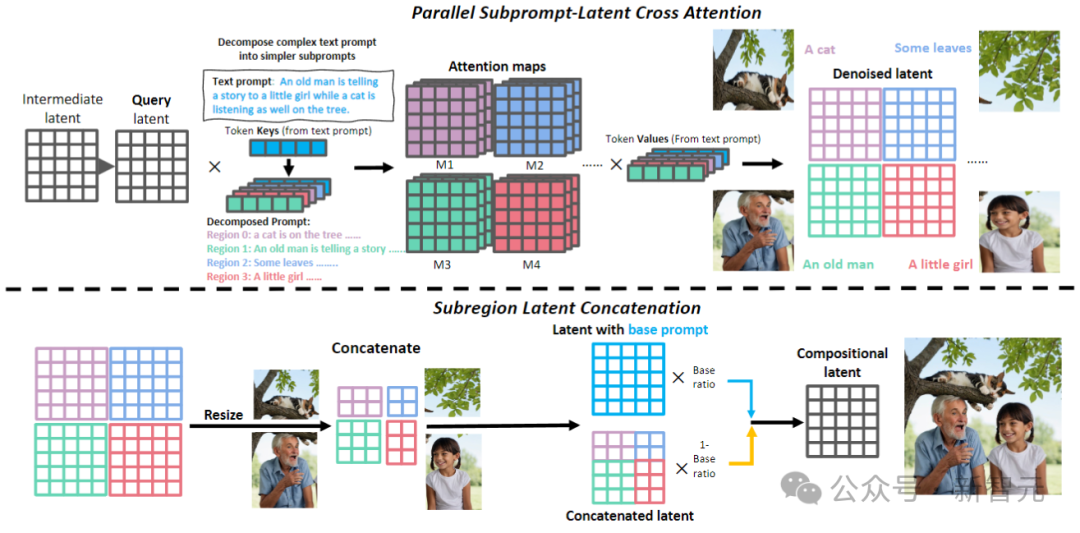
Édition d'images guidée par texte
comme indiqué dans l'image ci-dessus. Au stade du récit, RPG utilise MLLM comme sous-titres pour raconter l'image source et utilise ses puissantes capacités de raisonnement pour identifier les différences sémantiques fines entre l'image et le signal cible, analysant directement la manière dont l'image d'entrée s'aligne sur le signal cible.
Utilisez MLLM (GPT-4, Gemini Pro, etc.) pour vérifier les différences entre l'entrée et la cible concernant la précision numérique, les liaisons de propriétés et les relations entre les objets. Les commentaires de compréhension multimodaux qui en résulteront seront transmis au MLLM pour la planification de l'édition inférentielle.
Jetons un coup d'œil aux performances de l'effet de génération dans les trois aspects ci-dessus. Le premier est la liaison d'attributs, en comparant SDXL, DALL·E 3 et LMD+ :

Nous pouvons le voir dans tout. trois tests Parmi les jeux, seul le RPG reflète le plus fidèlement ce que les invites décrivent.
Ensuite il y a la précision numérique, l'ordre d'affichage est le même que ci-dessus (SDXL, DALL·E 3, LMD+, RPG) :

-Je ne m'attendais pas à ce que compter soit assez difficile pour le grand modèle de figurine Vincent Oui, le RPG bat facilement l'adversaire.
Le dernier élément consiste à restaurer des relations complexes dans l'invite :

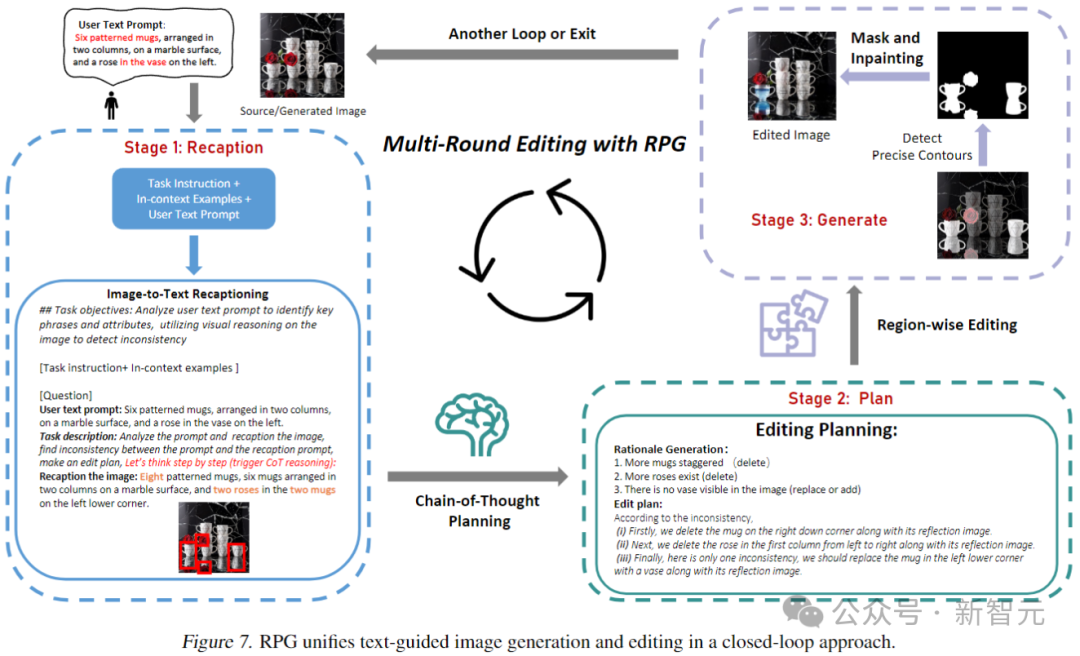
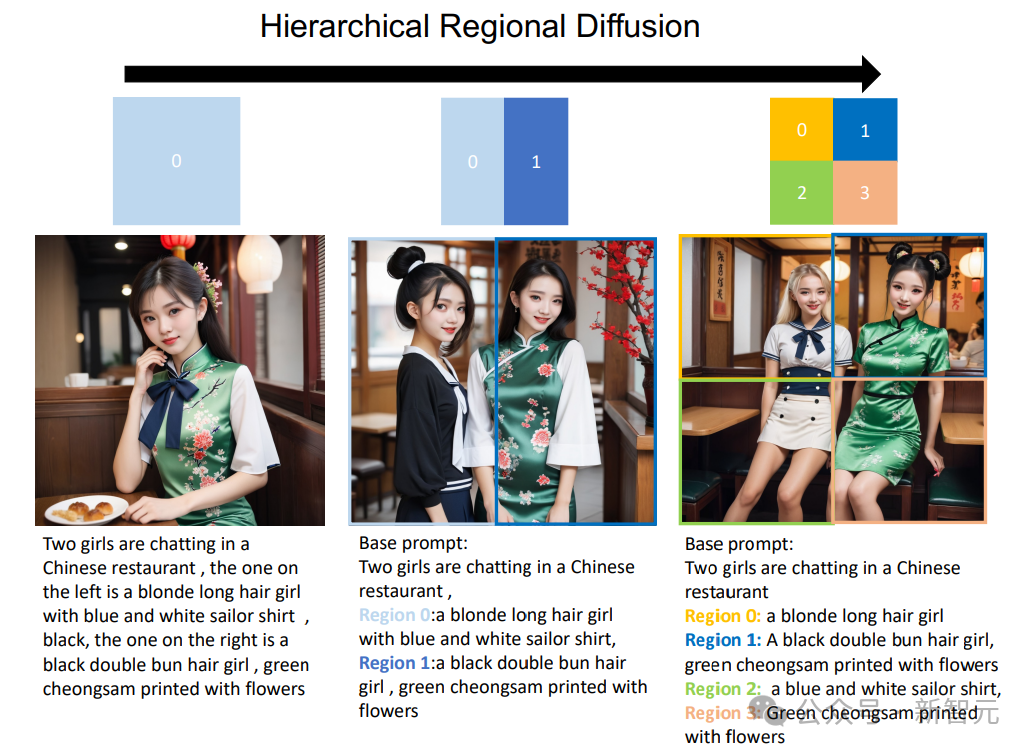
De plus, la diffusion de zones peut être étendue à un format hiérarchique, divisant des sous-régions spécifiques en sous-régions plus petites.
Comme le montre la figure ci-dessous, RPG peut apporter des améliorations significatives dans la génération de texte en image lors de l'ajout d'une hiérarchie de segmentation des régions. Cela offre une nouvelle perspective pour gérer des tâches de génération complexes, permettant de générer des images de composition arbitraire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!