
Maison >Périphériques technologiques >IA >Courir avec vous est rapide et stable, le partenaire de course du robot est là
Courir avec vous est rapide et stable, le partenaire de course du robot est là

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-16 18:50:211233parcourir
Ce robot s'appelle Cassie et a déjà établi un record du monde au 100 mètres. Récemment, des chercheurs de l'Université de Californie à Berkeley ont développé un nouvel algorithme d'apprentissage par renforcement profond, lui permettant de maîtriser des compétences telles que les virages serrés et de résister à diverses interférences.
 Des recherches sur la locomotion des robots bipèdes n'ont pas été menées depuis des décennies, mais elles continuent a été capable d'exécuter diverses compétences locomotrices. Un cadre général pour un contrôle robuste. Le défi vient de la complexité de la dynamique sous-actionnée des robots bipèdes et des différentes planifications associées à chaque compétence locomotrice.
Des recherches sur la locomotion des robots bipèdes n'ont pas été menées depuis des décennies, mais elles continuent a été capable d'exécuter diverses compétences locomotrices. Un cadre général pour un contrôle robuste. Le défi vient de la complexité de la dynamique sous-actionnée des robots bipèdes et des différentes planifications associées à chaque compétence locomotrice. La question clé que les chercheurs espèrent résoudre est la suivante : comment développer une solution pour les robots bipèdes de grande dimension à taille humaine ? Comment contrôler des habiletés de mouvement des jambes diverses, agiles et robustes telles que la marche, la course et le saut ?
Une étude récente pourrait apporter une bonne solution.
Dans ce travail, des chercheurs de Berkeley et d'autres institutions utilisent l'apprentissage par renforcement (RL) pour créer des contrôleurs pour des robots bipèdes non linéaires de grande dimension dans le monde réel afin de relever les défis ci-dessus. Ces contrôleurs peuvent exploiter les informations proprioceptives du robot pour s'adapter à des dynamiques incertaines qui changent avec le temps, tout en étant capables de s'adapter à de nouveaux environnements et paramètres, en tirant parti de l'agilité du robot bipède pour présenter un comportement robuste dans des situations inattendues. De plus, notre cadre fournit une recette générale pour reproduire diverses compétences locomotrices bipèdes.

- Titre de l'article : Apprentissage par renforcement pour un contrôle de locomotion bipède polyvalent, dynamique et robuste
- Lien de l'article : https://arxiv.org/pdf/2401.16889.pdf
La haute dimensionnalité et la non-linéarité des robots bipèdes à taille humaine et à contrôle de couple peuvent à première vue apparaître comme des obstacles pour le contrôleur, mais ces caractéristiques ont l'avantage de permettre des implémentations complexes grâce aux dimensions élevées du robot. dynamique.
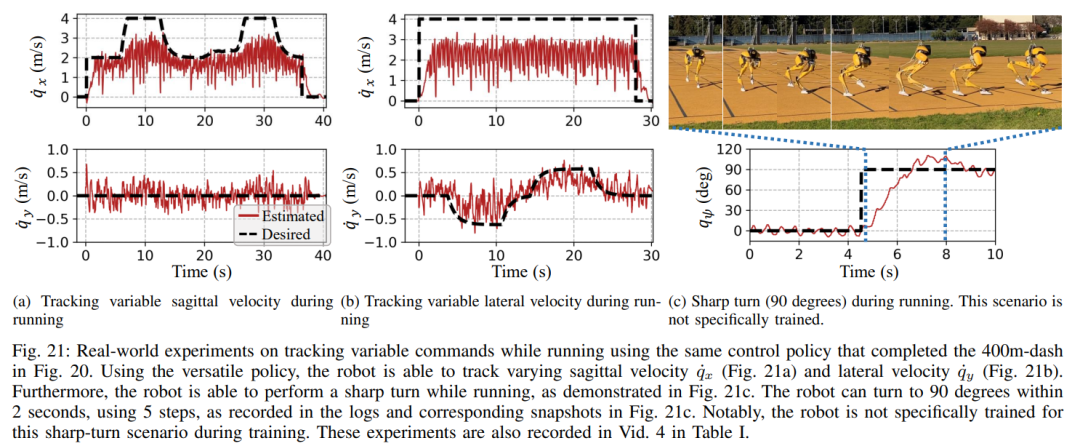
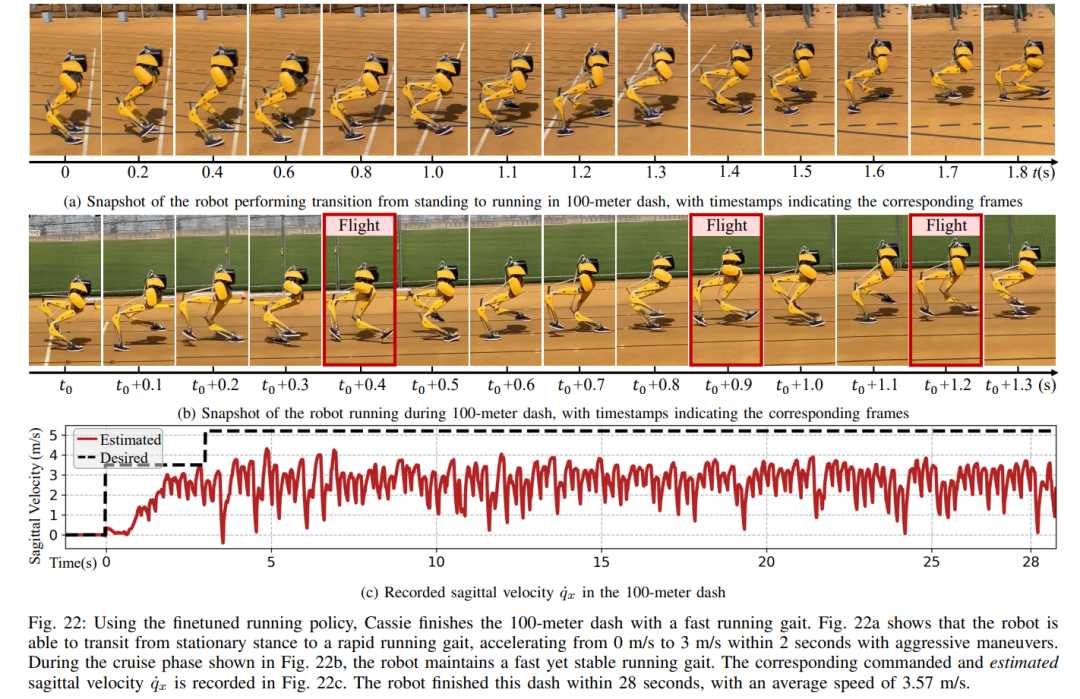
Les compétences que ce contrôleur confère au robot sont illustrées dans la figure 1, notamment se tenir debout de manière stable, marcher, courir et sauter. Ces compétences peuvent également être utilisées pour effectuer diverses tâches, notamment marcher à différentes vitesses et hauteurs, courir à différentes vitesses et dans différentes directions et sauter vers diverses cibles, tout en conservant leur robustesse pendant le déploiement réel. À cette fin, les chercheurs utilisent le RL sans modèle pour permettre aux robots d’apprendre par essais et erreurs la dynamique d’ordre complet du système. En plus des expériences réelles, les avantages de l'utilisation de RL pour le contrôle des mouvements des jambes sont analysés en profondeur et la manière de structurer efficacement le processus d'apprentissage pour exploiter ces avantages, tels que l'adaptabilité et la robustesse, est examinée en détail.
 Le système RL pour le contrôle universel des mouvements bipèdes est illustré dans la figure 2 :
Le système RL pour le contrôle universel des mouvements bipèdes est illustré dans la figure 2 : 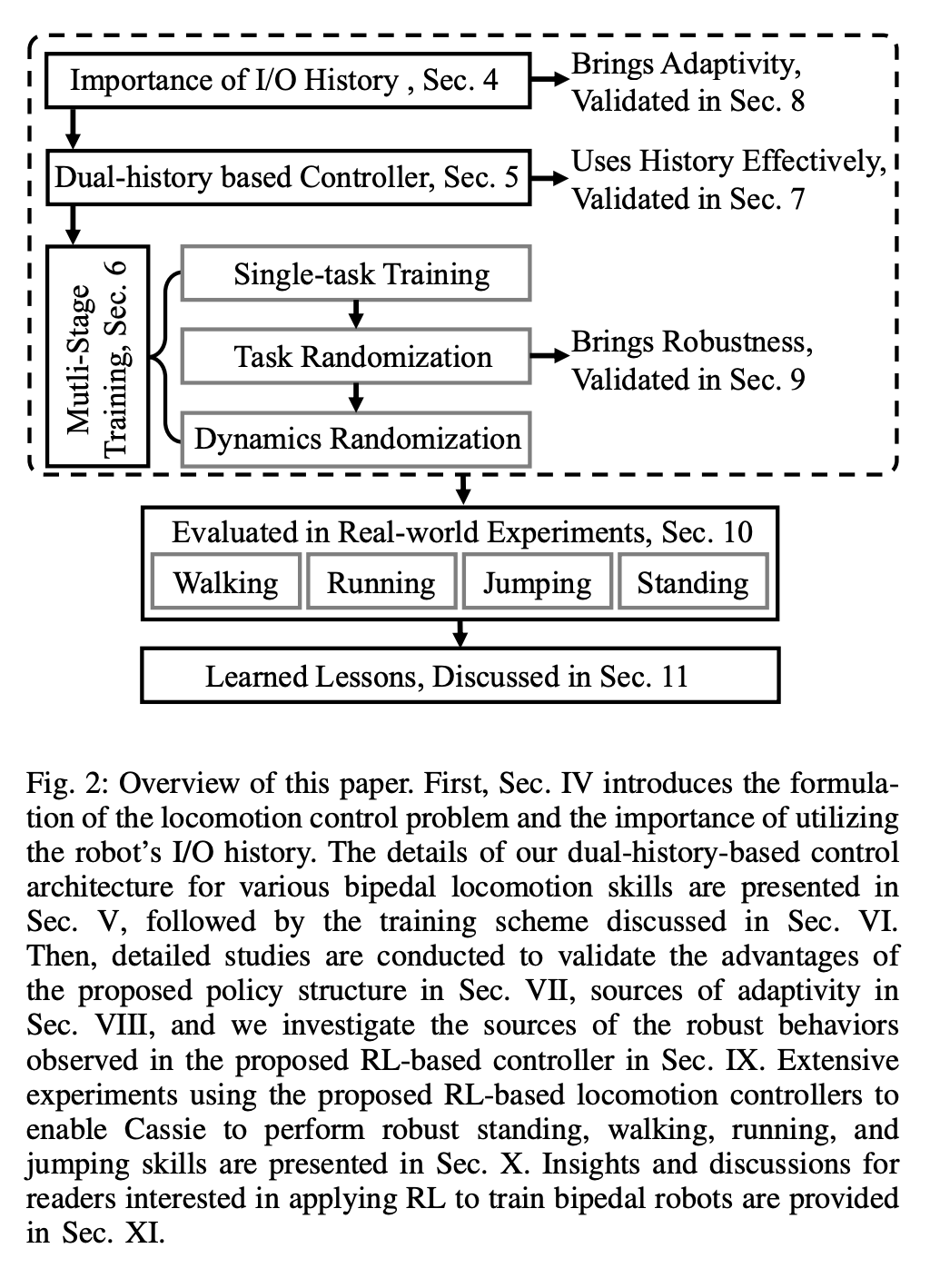 La section 4 présente d'abord l'importance de l'utilisation de l'historique des E/S du robot dans le contrôle des mouvements. Cette section du point de vue du contrôle et du RL. , il est démontré que l'historique des E/S à long terme du robot peut permettre l'identification du système et l'estimation de l'état dans le processus de contrôle en temps réel.
La section 4 présente d'abord l'importance de l'utilisation de l'historique des E/S du robot dans le contrôle des mouvements. Cette section du point de vue du contrôle et du RL. , il est démontré que l'historique des E/S à long terme du robot peut permettre l'identification du système et l'estimation de l'état dans le processus de contrôle en temps réel. La section 5 présente le cœur de la recherche : une nouvelle architecture de contrôle qui utilise les doubles historiques d'E/S à long terme et à court terme des robots bipèdes. Plus précisément, cette architecture de contrôle exploite non seulement l’historique à long terme du robot, mais également son historique à court terme.
Le cadre de contrôle est le suivant :
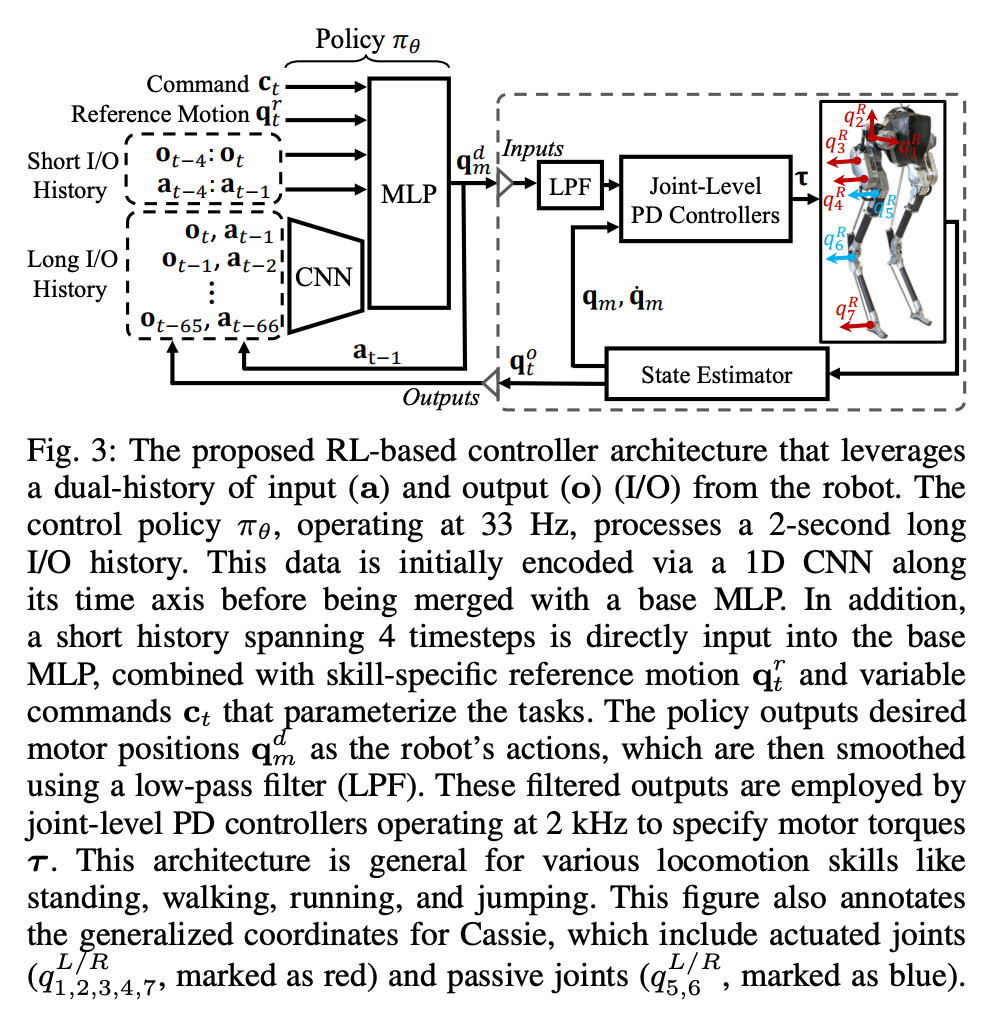 Dans cette structure à double historique, l'historique à long terme apporte de l'adaptabilité (vérifié dans la section 8), et l'historique à court terme est mieux mis en œuvre par l'utilisation L’historique à long terme est complété par un contrôle en temps réel (validé dans la section 7).
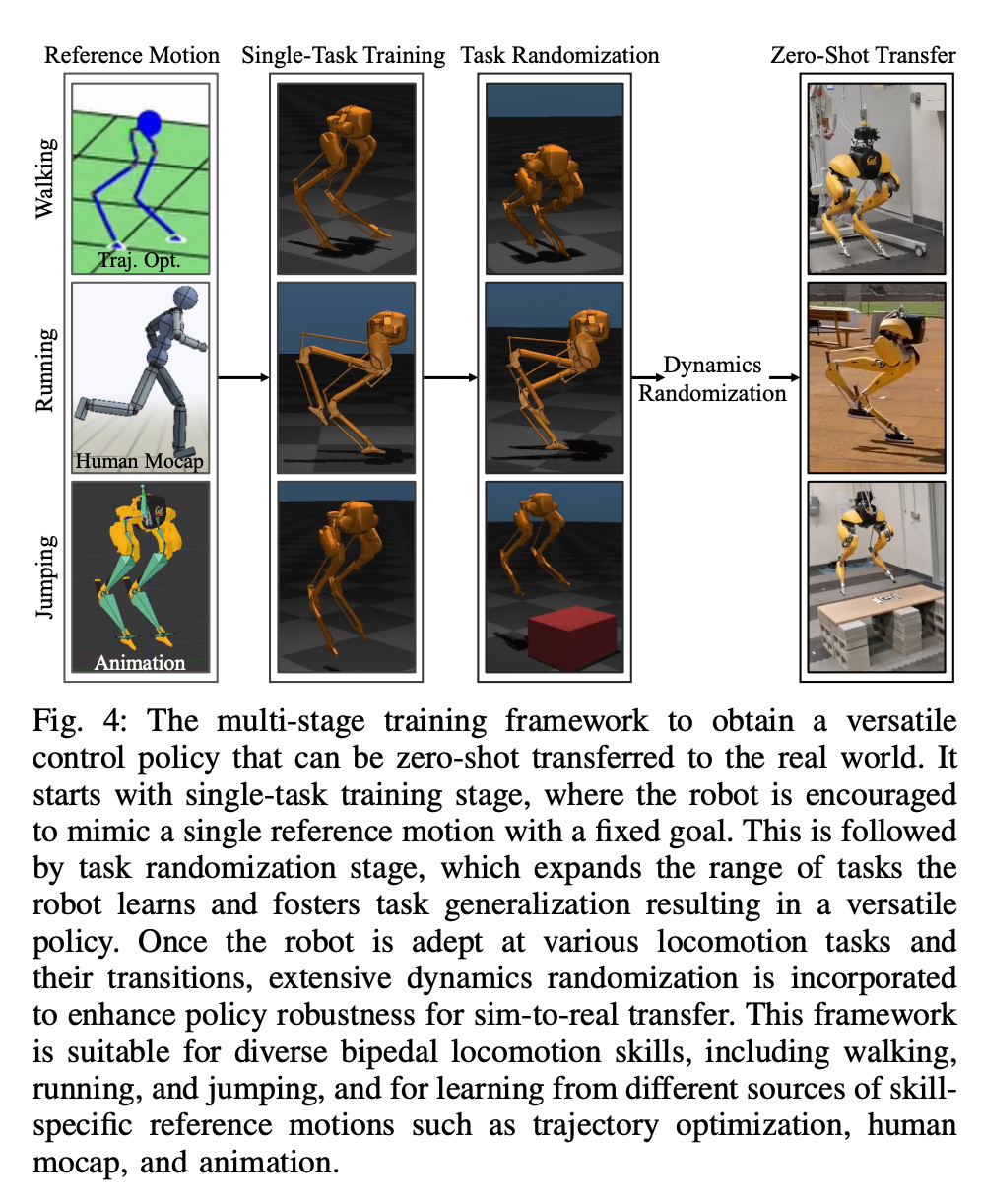
Dans cette structure à double historique, l'historique à long terme apporte de l'adaptabilité (vérifié dans la section 8), et l'historique à court terme est mieux mis en œuvre par l'utilisation L’historique à long terme est complété par un contrôle en temps réel (validé dans la section 7). La section 6 présente comment les stratégies de contrôle représentées par des réseaux de neurones profonds peuvent être optimisées grâce au RL sans modèle. Étant donné que les chercheurs visaient à développer un contrôleur capable d’utiliser des capacités motrices hautement dynamiques pour accomplir diverses tâches, la formation de cette section est caractérisée par une formation par simulation en plusieurs étapes. Cette stratégie de formation propose un cours structuré, commençant par une formation à tâche unique, où le robot se concentre sur une tâche fixe, puis une randomisation des tâches, qui diversifie les tâches de formation que le robot reçoit, et enfin une randomisation dynamique, qui modifie les paramètres dynamiques du robot.La stratégie
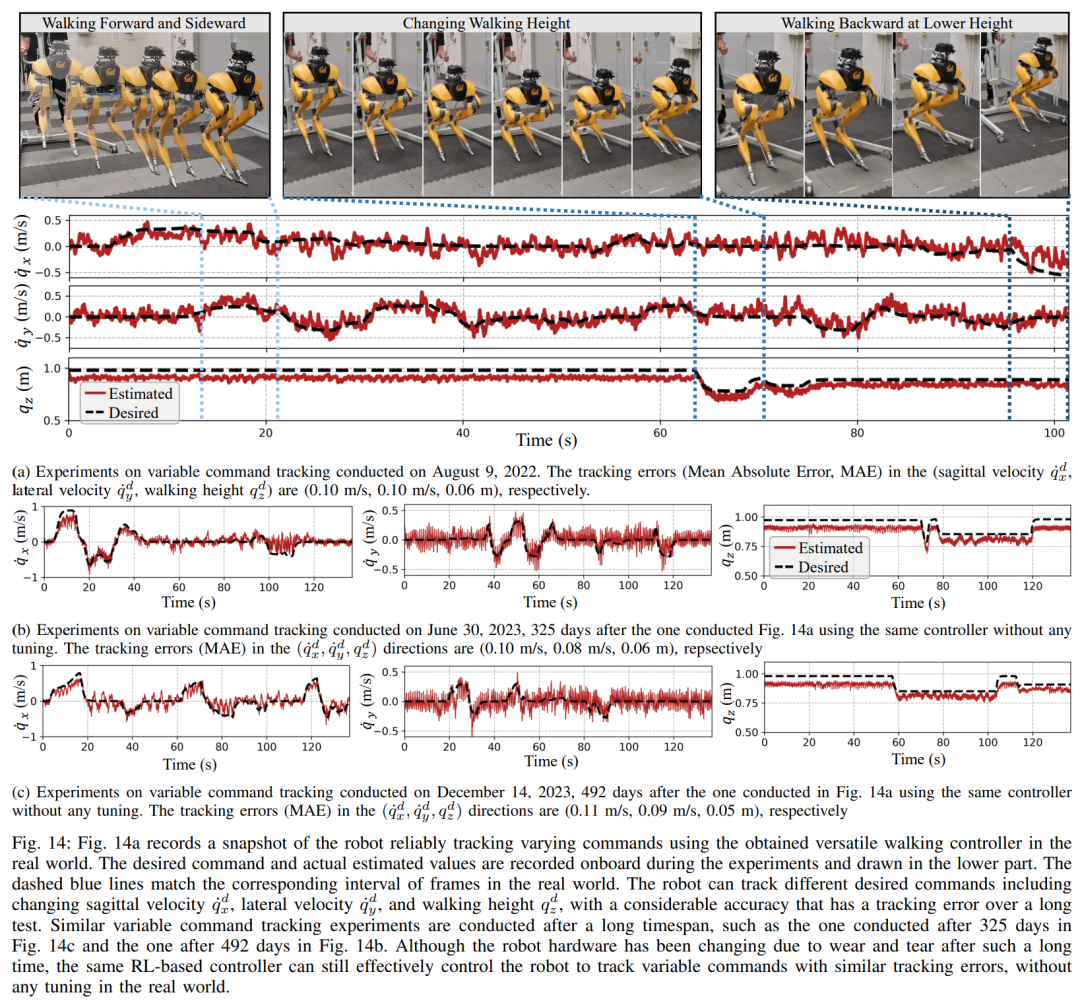
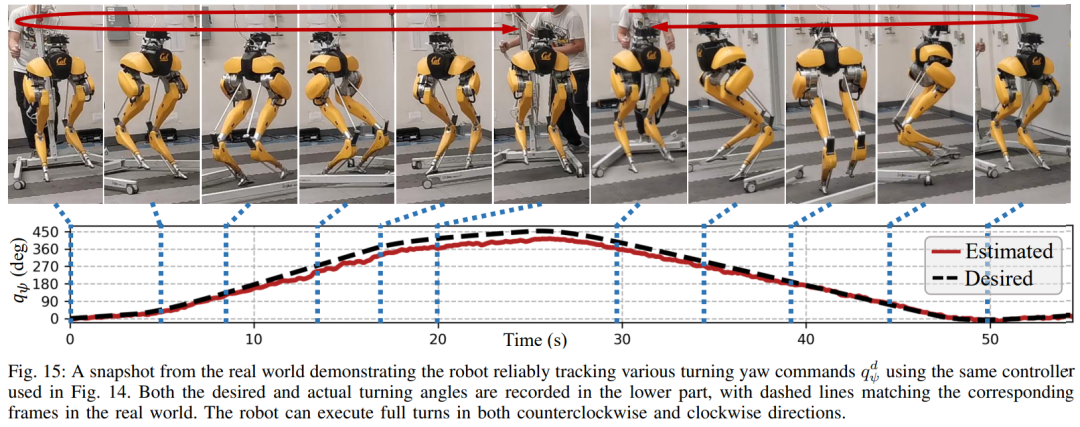
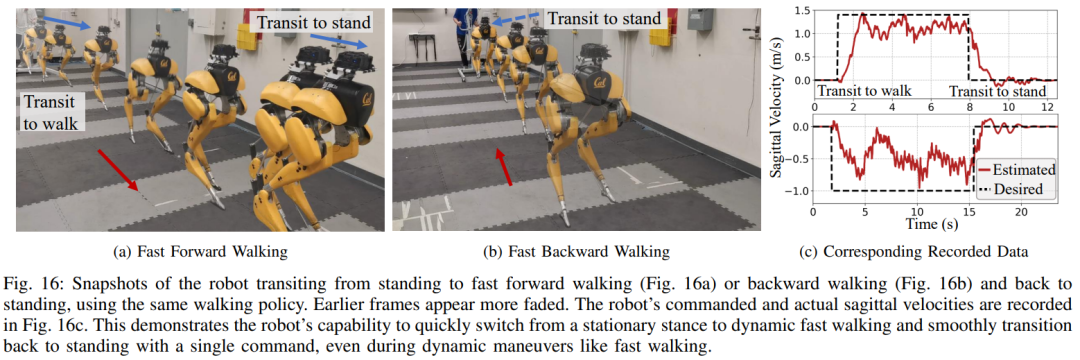

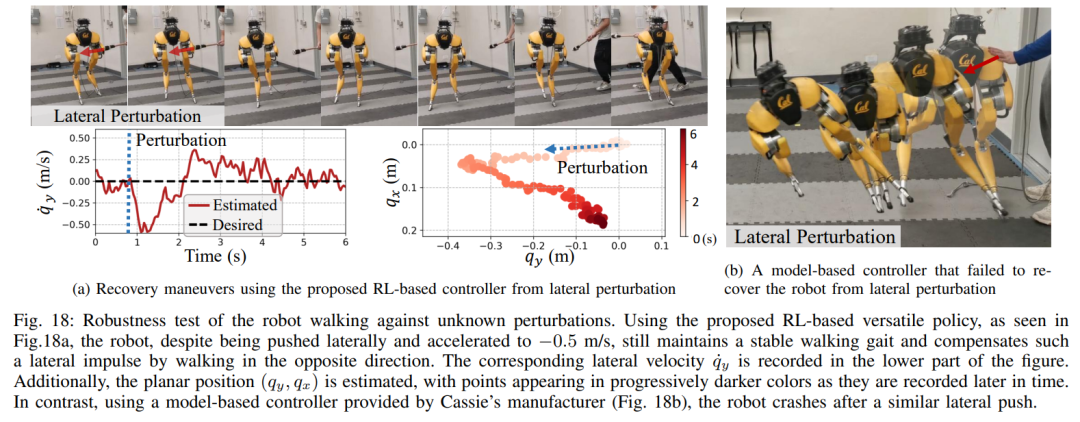
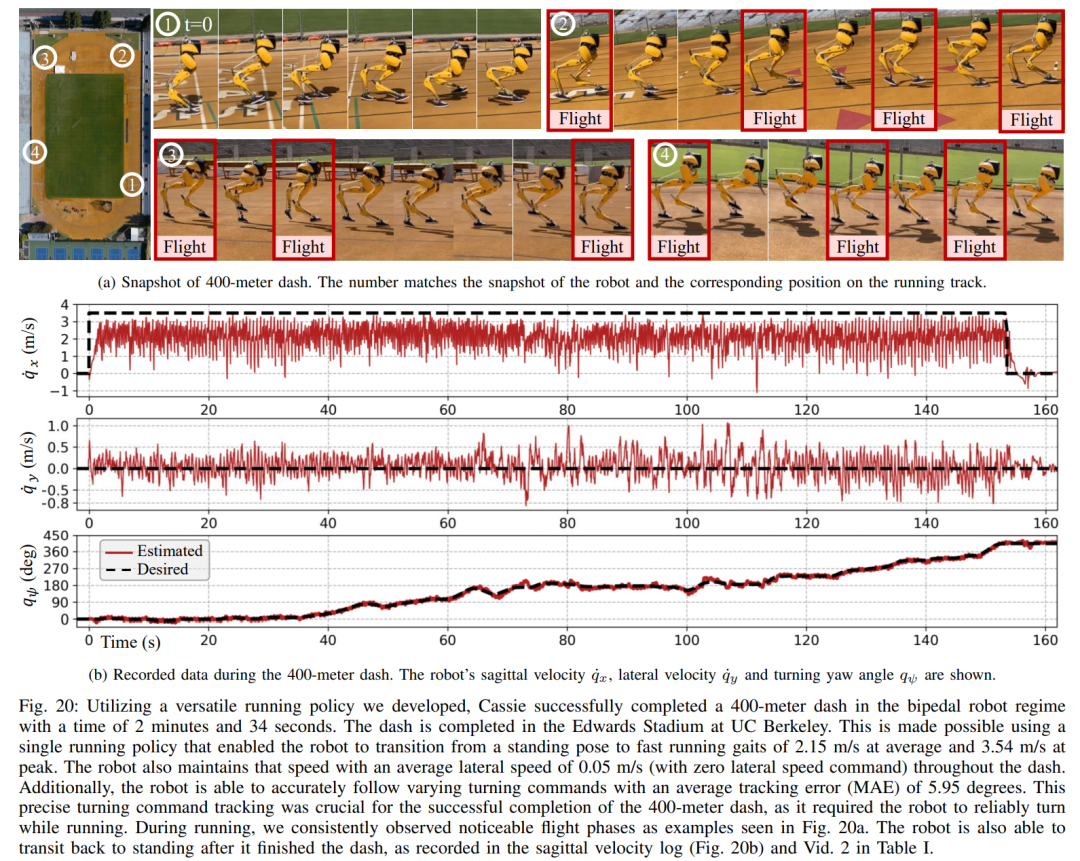

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Cet article est reproduit dans:. en cas de violation, veuillez contacter admin@php.cn Supprimer
Article précédent:Google Gemini 1.5 est lancé rapidement : architecture MoE, 1 million de contextesArticle suivant:Google Gemini 1.5 est lancé rapidement : architecture MoE, 1 million de contextes
Articles Liés
Voir plus- La chaîne industrielle de l'intelligence artificielle comprend
- 24,73 secondes ! Le robot bipède Cassie défie une course de 100 mètres et établit un record du monde
- Ronglian Cloud a été sélectionné dans la carte mondiale de l'industrie de l'IA générative 2023
- Application de la technologie informatique de confiance dans le domaine de la sécurité industrielle
- Le premier Forum du Sommet sur le développement collaboratif de la chaîne industrielle des robots du delta du fleuve Yangtze 2023 s'est tenu avec succès à Wuhu, Anhui.