
Maison >Périphériques technologiques >IA >« Émergence intelligente » de la génération vocale : 100 000 heures de formation sur les données, Amazon propose 1 milliard de paramètres BASE TTS
« Émergence intelligente » de la génération vocale : 100 000 heures de formation sur les données, Amazon propose 1 milliard de paramètres BASE TTS

- WBOYavant
- 2024-02-16 18:40:251336parcourir
Avec le développement rapide des modèles d'apprentissage profond génératifs, le traitement du langage naturel (NLP) et la vision par ordinateur (CV) ont subi des changements importants. Des modèles supervisés précédents qui nécessitaient une formation spécialisée, à un modèle général qui ne nécessite que des instructions simples et claires pour accomplir diverses tâches. Cette transformation nous offre une solution plus efficace et plus flexible.
Dans le domaine du traitement de la parole et de la synthèse vocale (TTS), une transformation est en cours. En exploitant des milliers d’heures de données, le modèle rapproche de plus en plus la synthèse de la parole humaine réelle.
Dans une étude récente, Amazon a officiellement lancé BASE TTS, augmentant l'échelle des paramètres du modèle TTS à un niveau sans précédent de 1 milliard.

Titre de l'article : BASE TTS : Leçons tirées de la création d'un modèle de synthèse vocale à un milliard de paramètres sur 100 000 heures de données
Lien de l'article : https://arxiv.org/pdf/2402.08093. pdf
BASE TTS est un système TTS multilingue et multi-locuteurs (LTTS) à grande échelle. Il a utilisé environ 100 000 heures de données vocales du domaine public pour la formation, soit deux fois plus que VALL-E, qui disposait auparavant de la plus grande quantité de données de formation. Inspiré par l'expérience réussie de LLM, BASE TTS traite le TTS comme le problème de la prédiction du prochain jeton et le combine avec une grande quantité de données de formation pour obtenir de puissantes capacités multilingues et multi-locuteurs.
Les principales contributions de cet article sont résumées comme suit :
Le BASE TTS proposé est actuellement le plus grand modèle TTS avec 1 milliard de paramètres et est formé sur la base d'un ensemble de données composé de 100 000 heures de données vocales du domaine public. Grâce à une évaluation subjective, BASE TTS surpasse le modèle de référence public LTTS en termes de performances.
Cet article montre comment améliorer la capacité de BASE TTS à restituer une prosodie appropriée pour un texte complexe en l'étendant à des ensembles de données et à des tailles de modèle plus grands. Afin d'évaluer les capacités de compréhension et de rendu du texte des modèles TTS à grande échelle, les chercheurs ont développé un ensemble de tests de « capacités émergentes » et ont rapporté les performances de différentes variantes de BASE TTS sur ce benchmark. Les résultats montrent qu'à mesure que la taille de l'ensemble de données et le nombre de paramètres augmentent, la qualité de BASE TTS s'améliore progressivement.
3. Une nouvelle représentation discrète de la parole basée sur le modèle WavLM SSL est proposée, visant à capturer uniquement les informations phonologiques et prosodiques du signal vocal. Ces représentations surpassent les méthodes de quantification de base, leur permettant d'être décodées en formes d'onde de haute qualité par des décodeurs simples, rapides et en streaming malgré des niveaux de compression élevés (seulement 400 bit/s).
Ensuite, regardons les détails du papier.
Modèle BASE TTS
Semblable aux récents travaux de modélisation de la parole, les chercheurs ont adopté une approche basée sur le LLM pour gérer les tâches TTS. Le texte est introduit dans un modèle autorégressif basé sur Transformer qui prédit des représentations audio discrètes (appelées codes vocaux), qui sont ensuite décodées en formes d'onde par un décodeur entraîné séparément composé de couches linéaires et convolutives.
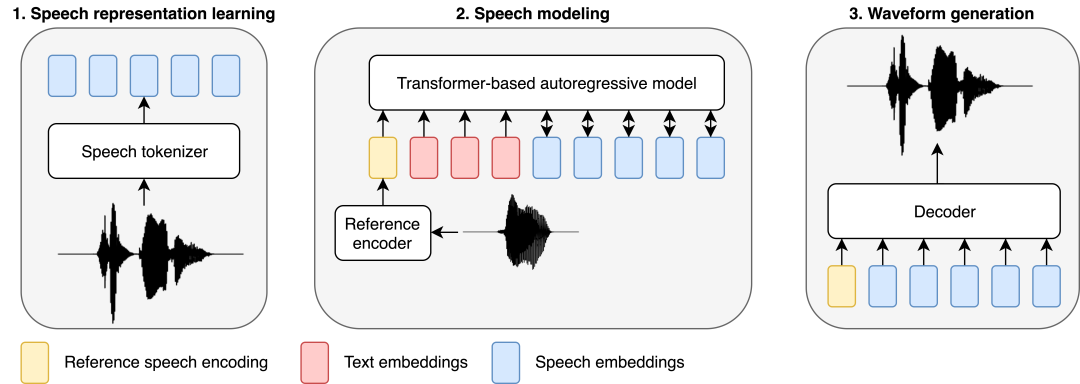
BASE TTS est conçu pour simuler la distribution conjointe de jetons de texte suivie de représentations vocales discrètes, que les chercheurs appellent codage vocal. La discrétisation de la parole par les codecs audio est au cœur de la conception, car elle permet une application directe des méthodes développées pour le LLM, qui constituent la base des résultats de recherche récents sur le LTTS. Plus précisément, nous modélisons le codage de la parole à l’aide d’un transformateur autorégressif de décodage avec un objectif de formation à entropie croisée. Bien que simple, cet objectif peut capturer la distribution de probabilité complexe de la parole expressive, atténuant ainsi le problème de lissage excessif observé dans les premiers systèmes neuronaux TTS. En tant que modèle de langage implicite, une fois que des variantes suffisamment grandes seront formées sur suffisamment de données, BASE TTS fera également un saut qualitatif dans le rendu de la prosodie.
Représentation du langage discret
Les représentations discrètes sont la base du succès du LLM, mais l'identification de représentations compactes et informatives dans la parole n'est pas aussi évidente que dans le texte et a été moins explorée auparavant. Pour BASE TTS, les chercheurs ont d’abord essayé d’utiliser la ligne de base VQ-VAE (Section 2.2.1), basée sur une architecture d’auto-encodeur pour reconstruire le spectrogramme mel à travers des goulots d’étranglement discrets. VQ-VAE est devenu un paradigme réussi pour la représentation de la parole et de l'image, notamment en tant qu'unité de modélisation pour TTS.
Les chercheurs ont également introduit une nouvelle méthode d’apprentissage de la représentation vocale grâce au codage vocal basé sur WavLM (Section 2.2.2). Dans cette approche, les chercheurs discrétisent les caractéristiques extraites du modèle SSL WavLM pour reconstruire les spectrogrammes mel. Les chercheurs ont appliqué une fonction de perte supplémentaire pour faciliter la séparation des locuteurs et ont compressé les codes vocaux générés à l'aide du Byte-Pair Encoding (BPE) pour réduire la longueur de la séquence, permettant ainsi l'utilisation du transformateur pour une modélisation audio plus longue.
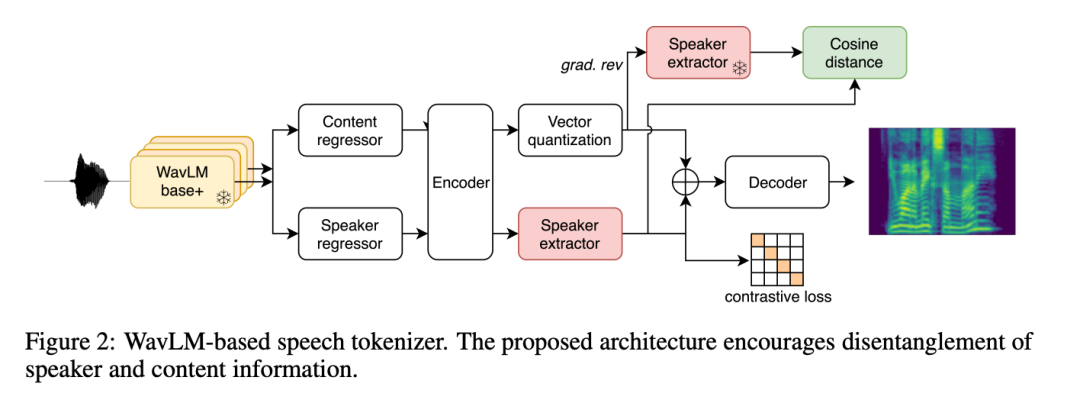
Les deux représentations sont compressées (325 bits/s et 400 bits/s respectivement) pour permettre une modélisation autorégressive plus efficace par rapport aux codecs audio populaires. Sur la base de ce niveau de compression, l'objectif suivant est de supprimer du code vocal les informations qui peuvent être reconstruites lors du décodage (locuteur, bruit audio, etc.) pour garantir que la capacité du code vocal soit principalement utilisée pour encoder des éléments phonétiques et prosodiques. information.
Modélisation autorégressive de la parole (SpeechGPT)
Les chercheurs ont formé un modèle autorégressif « SpeechGPT » avec une architecture GPT-2, qui est utilisé pour prédire le codage de la parole conditionné par le texte et la parole de référence. La condition vocale de référence consistait en des énoncés sélectionnés au hasard provenant du même locuteur, qui étaient codés sous forme d'intégrations de taille fixe. Les intégrations de parole de référence, les codages de texte et de parole sont concaténés dans une séquence modélisée par un modèle autorégressif basé sur Transformer. Nous utilisons des intégrations positionnelles distinctes et des têtes de prédiction distinctes pour le texte et la parole. Ils ont formé un modèle autorégressif à partir de zéro sans pré-formation sur le texte. Afin de préserver les informations textuelles pour guider les onomatopées, SpeechGPT est également entraîné dans le but de prédire le prochain jeton de la partie texte de la séquence d'entrée, de sorte que la partie SpeechGPT est un LM contenant uniquement du texte. Un poids inférieur est adopté ici pour la perte de texte par rapport à la perte de parole.
Génération de forme d'onde
De plus, les chercheurs ont spécifié un décodeur distinct de codeur de parole en forme d'onde (appelé « codec de parole ») chargé de reconstruire l'identité du locuteur et les conditions d'enregistrement. Pour rendre le modèle plus évolutif, ils ont remplacé la couche LSTM par une couche convolutive pour décoder la représentation intermédiaire. La recherche montre que ce codec vocal basé sur la convolution est efficace sur le plan informatique, réduisant le temps de synthèse global du système de plus de 70 % par rapport aux décodeurs de base basés sur la diffusion.
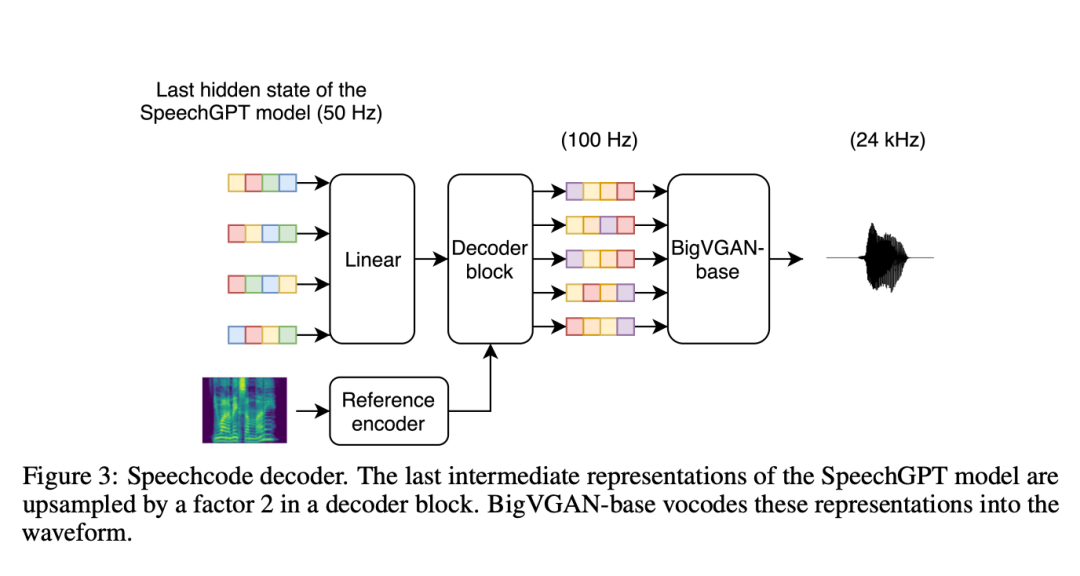
Les chercheurs ont également souligné qu'en fait l'entrée du codec vocal n'est pas l'encodage de la parole, mais le dernier état caché du transformateur autorégressif. Cela a été fait parce que les représentations latentes denses des méthodes TortoiseTTS précédentes fournissent des informations plus riches qu'un seul code phonétique. Au cours du processus de formation, les chercheurs ont saisi du texte et du code cible dans le SpeechGPT formé (gel des paramètres), puis ont ajusté le décodeur en fonction de l'état caché final. La saisie du dernier état caché de SpeechGPT permet d'améliorer la segmentation et la qualité acoustique de la parole, mais lie également le décodeur à une version spécifique de SpeechGPT. Cela complique les expériences car cela oblige les deux composants à toujours être construits séquentiellement. Cette limitation doit être abordée dans les travaux futurs.
Évaluation expérimentale
Les chercheurs ont exploré comment la mise à l'échelle affecte la capacité du modèle à produire une prosodie et une expression appropriées pour une saisie de texte difficile, de la même manière que LLM « émerge » de nouvelles capacités grâce à la mise à l'échelle des données et des paramètres. Pour vérifier si cette hypothèse s'applique également au LTTS, les chercheurs ont proposé un schéma d'évaluation des capacités émergentes potentielles dans le TTS, identifiant sept catégories difficiles : les noms composés, les émotions, les mots étrangers, le paralangage et la ponctuation, les problèmes et la complexité syntaxique.
De multiples expériences ont vérifié la structure de BASE TTS ainsi que sa qualité, ses fonctionnalités et ses performances de calcul :
Tout d'abord, les chercheurs ont comparé la qualité du modèle obtenu par le codage vocal basé sur un auto-encodeur et basé sur WavLM.
Les chercheurs ont ensuite évalué deux méthodes de décodage acoustique des codes vocaux : les décodeurs basés sur la diffusion et les codecs vocaux.
Après avoir terminé ces ablations structurelles, nous avons évalué les capacités émergentes de BASE TTS sur 3 variations de taille d'ensemble de données et de paramètres de modèle, ainsi que par des experts linguistiques.
De plus, les chercheurs ont effectué des tests subjectifs MUSHRA pour mesurer le naturel, ainsi que des mesures automatiques d'intelligibilité et de similarité des locuteurs, et ont rapporté des comparaisons de la qualité de la parole avec d'autres modèles de synthèse vocale open source.
Codage vocal VQ-VAE vs codage vocal WavLM
Afin de tester de manière exhaustive la qualité et la polyvalence des deux méthodes de tokenisation vocale, les chercheurs ont mené une évaluation MUSHRA sur 6 anglophones américains et 4 hispanophones. En termes de scores MUSHRA moyens en anglais, les systèmes basés sur VQ-VAE et WavLM étaient comparables (VQ-VAE : 74,8 vs WavLM : 74,7). Cependant, pour l'espagnol, le modèle basé sur WavLM est statistiquement significativement meilleur que le modèle VQ-VAE (VQ-VAE : 73,3 vs WavLM : 74,7). Notez que les données anglaises représentent environ 90 % de l'ensemble de données, tandis que les données espagnoles n'en représentent que 2 %.
Le tableau 3 montre les résultats par locuteur :
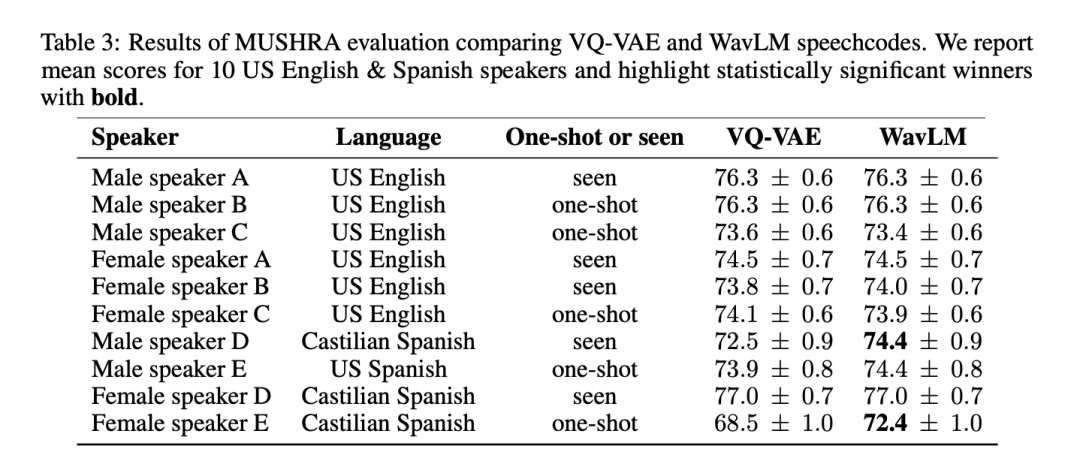
Étant donné que le système basé sur WavLM a fonctionné au moins aussi bien ou mieux que la ligne de base VQ-VAE, nous l'avons utilisé pour représenter BASE TTS dans d'autres expériences.
Décodeur basé sur la diffusion et décodeur de code vocal
Comme mentionné ci-dessus, BASE TTS simplifie le décodeur de base basé sur la diffusion en proposant un codec vocal de bout en bout. La méthode est fluide et augmente la vitesse d'inférence de 3 fois. Pour garantir que cette approche ne dégrade pas la qualité, le codec vocal proposé a été évalué par rapport aux lignes de base. Le tableau 4 liste les résultats de l'évaluation MUSHRA sur 4 Américains anglophones et 2 hispanophones :
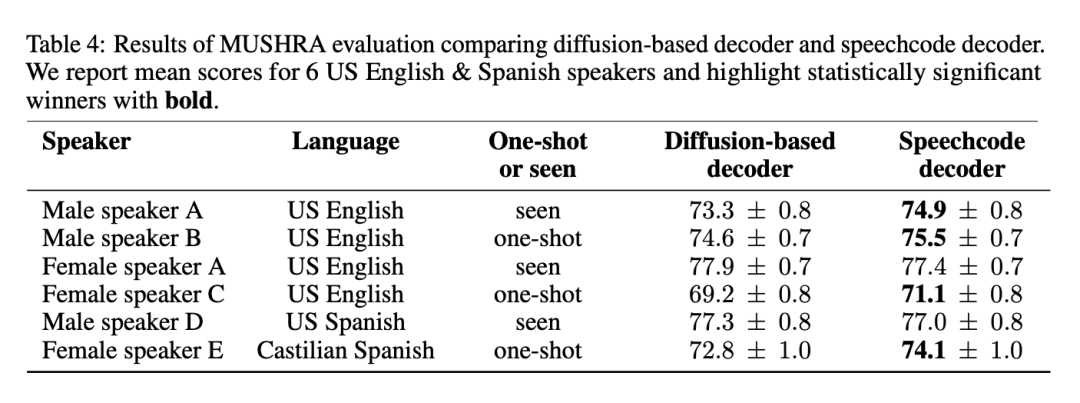
Les résultats montrent que le codec vocal est la méthode privilégiée car il ne réduit pas la qualité, Et pour la plupart des paroles, cela améliore la qualité tout en fournissant une inférence plus rapide. Les chercheurs ont également déclaré que la combinaison de deux modèles génératifs puissants pour la modélisation de la parole est redondante et peut être simplifiée en abandonnant le décodeur de diffusion.
Puissance émergente : ablation des données et taille du modèle
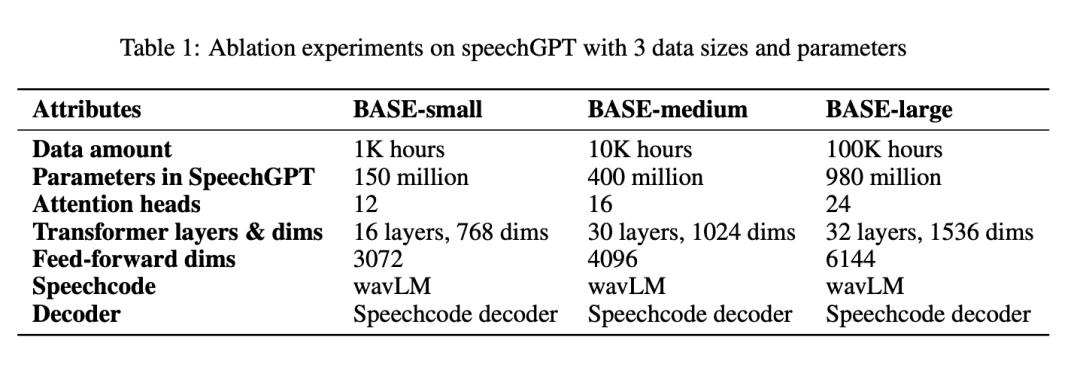
Le tableau 1 présente tous les paramètres par systèmes BASE-small, BASE-medium et BASE-large :
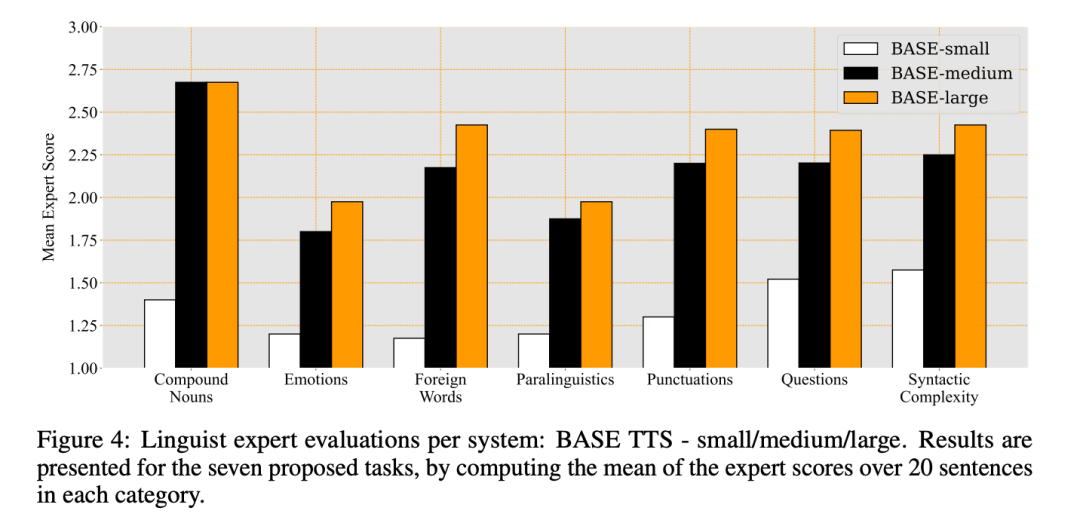
Résultats du jugement d'expert linguiste pour les trois systèmes et chacun des les scores moyens de chaque catégorie sont présentés dans la figure 4 :
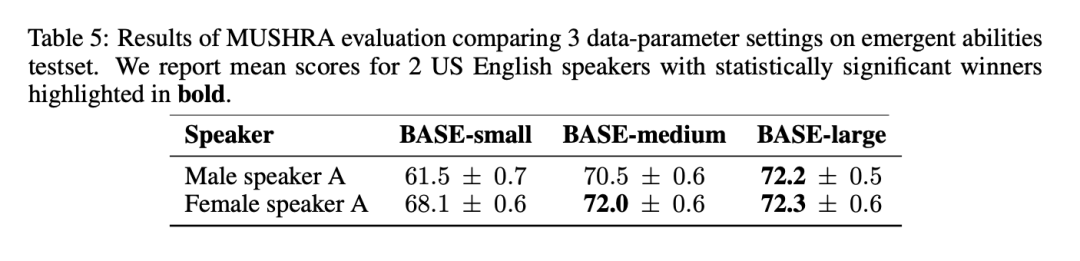
Dans les résultats MUSHRA du tableau 5, on peut remarquer que le naturel de la parole s'améliore considérablement de BASE-petit à BASE-moyen, mais de BASE-moyen à BASE - L'amélioration de large est plus petite :
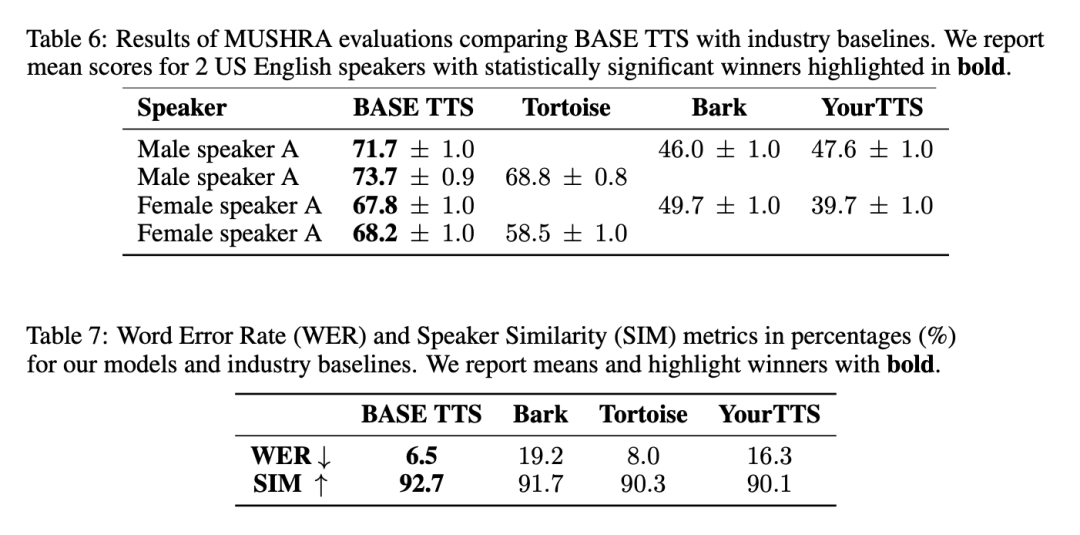
BASE TTS par rapport à la référence de l'industrie
En général, BASE TTS génère la parole la plus naturelle, a le moins de désalignement avec le texte saisi et est le plus similaire au discours du locuteur de référence. Les résultats pertinents sont présentés dans le Tableau 6 et le Tableau 7 :
Amélioration de l'efficacité de la synthèse apportée par le codec vocal
Le codec vocal est capable de traiter en continu, c'est-à-dire de générer la parole de manière incrémentielle. manière. En combinant cette fonctionnalité avec SpeechGPT autorégressif, le système peut atteindre une latence du premier octet aussi faible que 100 millisecondes – suffisamment pour produire une parole intelligible avec seulement quelques codes vocaux décodés.
Cette latence minimale contraste fortement avec les décodeurs basés sur la diffusion, qui nécessitent que la séquence vocale entière (une ou plusieurs phrases) soit générée en une seule fois, avec une latence du premier octet égale au temps de génération total.
De plus, les chercheurs ont observé que le codec vocal rendait l'ensemble du système plus efficace sur le plan informatique d'un facteur 3 par rapport à la ligne de base de diffusion. Ils ont exécuté un benchmark qui a généré 1 000 instructions d'une durée d'environ 20 secondes avec une taille de lot de 1 sur un GPU NVIDIA® V100. En moyenne, un SpeechGPT comportant un milliard de paramètres utilisant un décodeur de diffusion prend 69,1 secondes pour terminer la synthèse, tandis que le même SpeechGPT utilisant un codec vocal ne prend que 17,8 secondes.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- L'innovation technologique accélère la mise en œuvre de l'industrie chinoise des interfaces cerveau-ordinateur
- La Corée du Sud a annoncé qu'elle investirait 500 milliards de wons au cours des cinq prochaines années pour soutenir l'industrie clé de la technologie de l'IA.
- Un robot humanoïde domestique à usage général sera lancé et l'industrie accélérera les percées
- Amazon Fire HD 10 Plus (2021) vaut-il la peine d'être acheté ?