
Maison >Tutoriel système >Linux >Comment l'utilisation du processeur est-elle calculée sous Linux ?
Comment l'utilisation du processeur est-elle calculée sous Linux ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-15 11:15:111386parcourir
Lorsqu'ils observent l'état d'exécution des services en ligne sur un serveur en ligne, la plupart des gens aiment d'abord utiliser la commande top pour voir l'utilisation globale du processeur du système actuel. Par exemple, pour une machine aléatoire, les informations d'utilisation affichées par la commande top sont les suivantes :

Ce résultat de sortie est pour le moins simple, mais il n'est pas si facile de tout comprendre même si c'est complexe. Par exemple :
Question 1 : Comment les informations d'utilisation produites par top sont-elles calculées ?
Question 2 : La colonne ni est sympa. Elle affiche la surcharge du processeur lors du traitement ?
Question 3 : wa représente io wait, donc le CPU est-il occupé ou inactif pendant cette période ?
Aujourd'hui, nous avons une étude approfondie des statistiques d'utilisation du processeur. Grâce à l'étude d'aujourd'hui, vous comprendrez non seulement les détails de mise en œuvre des statistiques d'utilisation du processeur, mais vous aurez également une compréhension plus approfondie d'indicateurs tels que nice et io wait.
Aujourd'hui, nous commençons avec nos propres pensées !
1. Pensez-y d'abord
En laissant de côté l'implémentation de Linux, si vous avez les exigences suivantes, vous disposez d'un serveur quad-core sur lequel quatre processus sont exécutés.
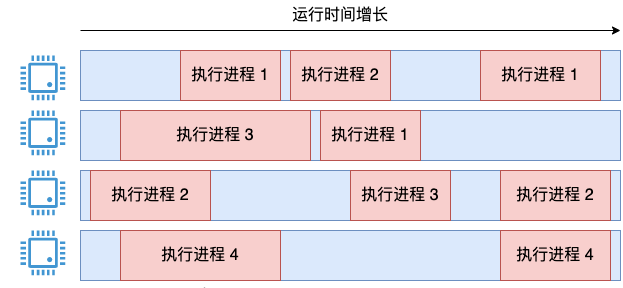
Vous permet de concevoir et de calculer l'utilisation du processeur de l'ensemble du système. Il prend en charge la sortie comme la commande top et répond aux exigences suivantes :
- L'utilisation du processeur doit être aussi précise que possible ; Il est nécessaire de refléter autant que possible l'état instantané du processeur au deuxième niveau.
- Vous pouvez vous arrêter et réfléchir quelques minutes.

Une idée est d'additionner le temps d'exécution de tous les processus, puis de le diviser par le temps d'exécution total du système * 4.
Cette idée ne pose aucun problème. Il est possible d'utiliser cette méthode pour compter l'utilisation du processeur sur une longue période, et les statistiques sont suffisamment précises.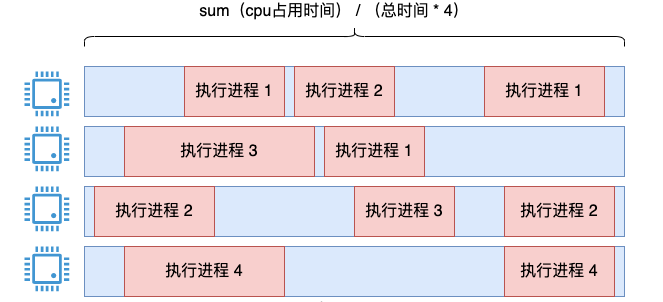
Mais tant que vous aurez utilisé top, vous saurez que l'utilisation du processeur par top n'est pas constante pendant une longue période, mais sera mise à jour dynamiquement par unités de 3 secondes par défaut (cet intervalle de temps peut être défini en utilisant -d ). Notre solution peut refléter l’utilisation totale, mais il est difficile de refléter cet état instantané. Vous pensez peut-être que je peux le compter comme un toutes les 3 secondes, n'est-ce pas ? Mais à quel moment commence cette période de 3 secondes. La granularité est difficile à contrôler.
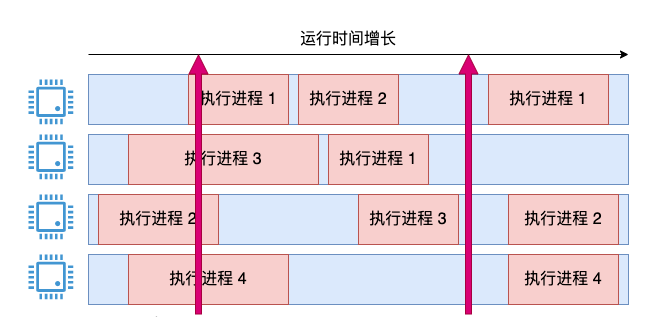
Le cœur de la question de réflexion précédente est de savoir comment résoudre des problèmes instantanés. En ce qui concerne l’état transitoire, vous avez peut-être une autre idée. Ensuite, j'utiliserai l'échantillonnage instantané pour voir combien de cœurs sont actuellement occupés. Si deux des quatre cœurs sont occupés, l'utilisation est de 50 %.
Cette réflexion va également dans le bon sens, mais il y a deux problèmes :
Les nombres que vous calculez sont tous des multiples de 25 % ;- Cette valeur instantanée peut provoquer des fluctuations brutales dans l'affichage de l'utilisation du processeur.
- Par exemple, la photo ci-dessous :
Améliorons-le et combinons les deux idées ci-dessus, peut-être pourrons-nous résoudre notre problème. En termes d'échantillonnage, nous avons défini la période pour qu'elle soit plus fine, mais en termes de calcul, nous avons défini la période pour qu'elle soit plus grossière.
Nous introduisons le concept de période d'adoption, de timing, comme l'échantillonnage toutes les millisecondes. Si le CPU est en cours d'exécution au moment de l'échantillonnage, cette ms est enregistrée comme utilisée. À ce moment, une utilisation instantanée du processeur sera obtenue et enregistrée.
Lors du comptage de l'utilisation du processeur dans les 3 secondes, comme la plage de temps t1 et t2 dans l'image ci-dessus. Additionnez ensuite toutes les valeurs instantanées durant cette période et prenez une valeur moyenne. Cela peut résoudre le problème ci-dessus, les statistiques sont relativement précises et le problème des valeurs instantanées oscillant violemment et étant trop grossières (ne peuvent changer que par unités de 25 %) est évité.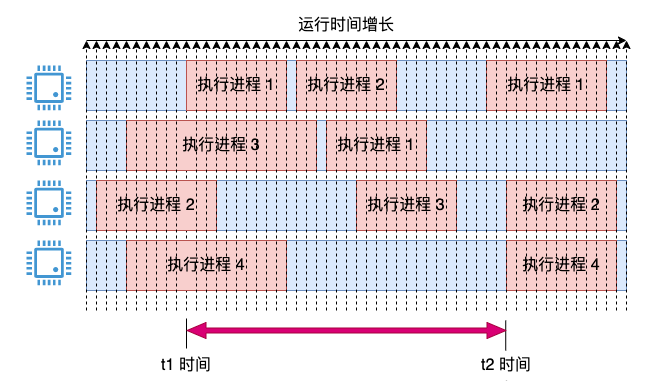
Certains étudiants peuvent se demander si le processeur change entre deux échantillonnages, comme le montre l'image ci-dessous.
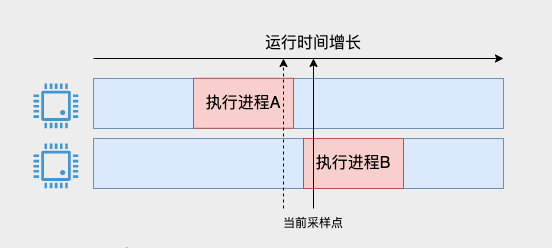
Lorsque le point d'échantillonnage actuel arrive, le processus A vient de terminer son exécution. Depuis un petit moment, il n'a pas été compté par le point d'échantillonnage précédent, et il ne peut pas non plus être compté cette fois. Pour le processus B, il n’a en réalité démarré que pendant une courte période. Cela semble un peu trop long pour enregistrer toutes les 1 ms.
Ce problème existe, mais comme notre échantillonnage est d'une fois 1 ms, et lorsque nous le vérifions et l'utilisons réellement, il se situe au moins au deuxième niveau, qui inclura des informations provenant de milliers de points d'échantillonnage, donc cette erreur ne sera pas affectent notre compréhension de la situation globale.
En fait, c'est ainsi que Linux compte l'utilisation du processeur du système. Bien qu'il puisse y avoir des erreurs, il suffit de les utiliser comme données statistiques. En termes de mise en œuvre, Linux accumule toutes les valeurs instantanées dans certaines données, plutôt que de stocker réellement de nombreuses copies de données instantanées.
Ensuite, entrons dans Linux pour voir son implémentation spécifique des statistiques d'utilisation du processeur système.
2. Où sont les données d'utilisation de la commande supérieure
L'implémentation de Linux que nous avons mentionnée dans la section précédente consiste à accumuler des valeurs instantanées pour certaines données. Cette valeur est exposée à l'état de l'utilisateur par le noyau via le pseudo-fichier /proc/stat. Linux l'utilise lors du calcul de l'utilisation du processeur du système.
Dans l'ensemble, les détails internes du travail du commandement supérieur sont présentés dans la figure ci-dessous.
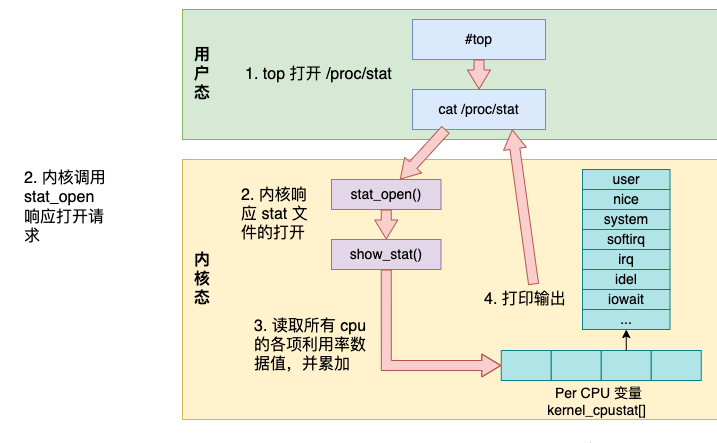
la commande top accède à /proc/stat pour obtenir diverses valeurs d'utilisation du processeur
;-
Le noyau appelle la fonction stat_open pour gérer l'accès à /proc/stat ;
-
Les données accessibles par le noyau proviennent du tableau kernel_cpustat et sont résumées ;
- Imprimer la sortie en mode utilisateur.
En utilisant strace pour tracer les différents appels système de la commande top, vous pouvez voir ses appels au fichier.
# strace top ... openat(AT_FDCWD, "/proc/stat", O_RDONLY) = 4 openat(AT_FDCWD, "/proc/2351514/stat", O_RDONLY) = 8 openat(AT_FDCWD, "/proc/2393539/stat", O_RDONLY) = 8 ...
Le noyau définit des fonctions de traitement pour chaque pseudo-fichier. La méthode de traitement du fichier /proc/stat est proc_stat_operations.«
En plus de /proc/stat, il existe également /proc/{pid}/stat décomposé par chaque processus, qui est utilisé pour calculer l'utilisation du processeur de chaque processus.
”
//file:fs/proc/stat.c
static int __init proc_stat_init(void)
{
proc_create("stat", 0, NULL, &proc_stat_operations);
return 0;
}
static const struct file_operations proc_stat_operations = {
.open = stat_open,
...
};
proc_stat_operations contient les méthodes d'opération correspondant à ce fichier. Lorsque le fichier /proc/stat est ouvert, stat_open sera appelé. stat_open appelle single_open_size et show_stat dans l'ordre pour afficher le contenu des données. Jetons un coup d'œil à son code :
//file:fs/proc/stat.c
static int show_stat(struct seq_file *p, void *v)
{
u64 user, nice, system, idle, iowait, irq, softirq, steal;
for_each_possible_cpu(i) {
struct kernel_cpustat *kcs = &kcpustat_cpu(i);
user += kcs->cpustat[CPUTIME_USER];
nice += kcs->cpustat[CPUTIME_NICE];
system += kcs->cpustat[CPUTIME_SYSTEM];
idle += get_idle_time(kcs, i);
iowait += get_iowait_time(kcs, i);
irq += kcs->cpustat[CPUTIME_IRQ];
softirq += kcs->cpustat[CPUTIME_SOFTIRQ];
...
}
//转换成节拍数并打印出来
seq_put_decimal_ull(p, "cpu ", nsec_to_clock_t(user));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(system));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq));
...
}
Dans le code ci-dessus, for_each_possible_cpu traverse la variable kcpustat_cpu qui stocke les données d'utilisation du processeur. Cette variable est une variable percpu, qui prépare un élément de tableau pour chaque cœur logique. Il stocke divers événements correspondant au noyau actuel, notamment user, nice, system, idel, iowait, irq, softirq, etc. Dans cette boucle, additionnez chaque utilisation de chaque cœur. Enfin, les données sont sorties via seq_put_decimal_ull.
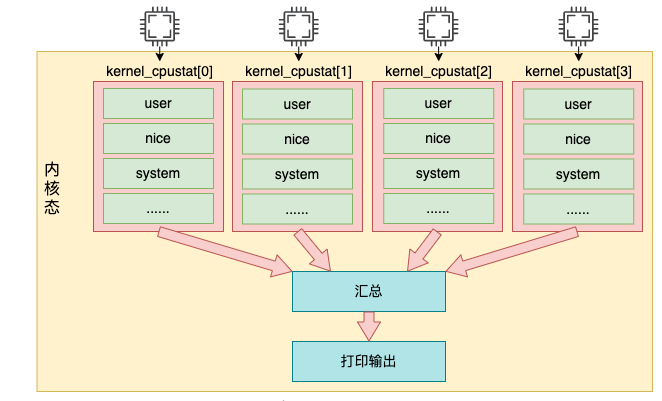 Notez que dans le noyau, chaque temps est en fait enregistré en nanosecondes, mais ils sont tous convertis en unités de battement lors de la sortie. Quant à la longueur de l’unité de battement, nous la présenterons dans la section suivante. En bref, la sortie de /proc/stat est lue à partir de la variable percpu kernel_cpustat.
Notez que dans le noyau, chaque temps est en fait enregistré en nanosecondes, mais ils sont tous convertis en unités de battement lors de la sortie. Quant à la longueur de l’unité de battement, nous la présenterons dans la section suivante. En bref, la sortie de /proc/stat est lue à partir de la variable percpu kernel_cpustat. Voyons quand les données de cette variable sont ajoutées.
三、统计数据怎么来的
前面我们提到内核是以采样的方式来统计 cpu 使用率的。这个采样周期依赖的是 Linux 时间子系统中的定时器。
Linux 内核每隔固定周期会发出 timer interrupt (IRQ 0),这有点像乐谱中的节拍的概念。每隔一段时间,就打出一个拍子,Linux 就响应之并处理一些事情。
一个节拍的长度是多长时间,是通过 CONFIG_HZ 来定义的。它定义的方式是每一秒有几次 timer interrupts。不同的系统中这个节拍的大小可能不同,通常在 1 ms 到 10 ms 之间。可以在自己的 Linux config 文件中找到它的配置。
# grep ^CONFIG_HZ /boot/config-5.4.56.bsk.10-amd64 CONFIG_HZ=1000
从上述结果中可以看出,我的机器每秒要打出 1000 次节拍。也就是每 1 ms 一次。
每次当时间中断到来的时候,都会调用 update_process_times 来更新系统时间。更新后的时间都存储在我们前面提到的 percpu 变量 kcpustat_cpu 中。
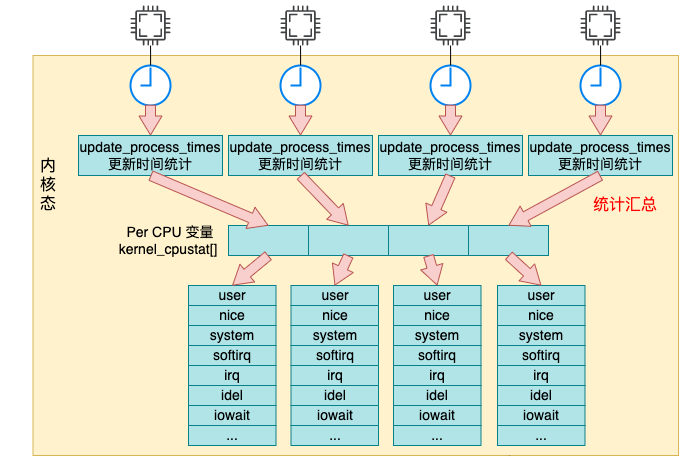
我们来详细看下汇总过程 update_process_times 的源码,它位于 kernel/time/timer.c 文件中。
//file:kernel/time/timer.c
void update_process_times(int user_tick)
{
struct task_struct *p = current;
//进行时间累积处理
account_process_tick(p, user_tick);
...
}
这个函数的参数 user_tick 指的是采样的瞬间是处于内核态还是用户态。接下来调用 account_process_tick。
//file:kernel/sched/cputime.c
void account_process_tick(struct task_struct *p, int user_tick)
{
cputime = TICK_NSEC;
...
if (user_tick)
//3.1 统计用户态时间
account_user_time(p, cputime);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
//3.2 统计内核态时间
account_system_time(p, HARDIRQ_OFFSET, cputime);
else
//3.3 统计空闲时间
account_idle_time(cputime);
}
在这个函数中,首先设置 cputime = TICK_NSEC, 一个 TICK_NSEC 的定义是一个节拍所占的纳秒数。接下来根据判断结果分别执行 account_user_time、account_system_time 和 account_idle_time 来统计用户态、内核态和空闲时间。
3.1 用户态时间统计
//file:kernel/sched/cputime.c
void account_user_time(struct task_struct *p, u64 cputime)
{
//分两种种情况统计用户态 CPU 的使用情况
int index;
index = (task_nice(p) > 0) ? CPUTIME_NICE : CPUTIME_USER;
//将时间累积到 /proc/stat 中
task_group_account_field(p, index, cputime);
......
}
account_user_time 函数主要分两种情况统计:
- 如果进程的 nice 值大于 0,那么将会增加到 CPU 统计结构的 nice 字段中。
- 如果进程的 nice 值小于等于 0,那么增加到 CPU 统计结构的 user 字段中。
看到这里,开篇的问题 2 就有答案了,其实用户态的时间不只是 user 字段,nice 也是。之所以要把 nice 分出来,是为了让 Linux 用户更一目了然地看到调过 nice 的进程所占的 cpu 周期有多少。
我们平时如果想要观察系统的用户态消耗的时间的话,应该是将 top 中输出的 user 和 nice 加起来一并考虑,而不是只看 user!
接着调用 task_group_account_field 来把时间加到前面我们用到的 kernel_cpustat 内核变量中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,
u64 tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
...
}
3.2 内核态时间统计
我们再来看内核态时间是如何统计的,找到 account_system_time 的代码。
//file:kernel/sched/cputime.c
void account_system_time(struct task_struct *p, int hardirq_offset, u64 cputime)
{
if (hardirq_count() - hardirq_offset)
index = CPUTIME_IRQ;
else if (in_serving_softirq())
index = CPUTIME_SOFTIRQ;
else
index = CPUTIME_SYSTEM;
account_system_index_time(p, cputime, index);
}
内核态的时间主要分 3 种情况进行统计。
- 如果当前处于硬中断执行上下文, 那么统计到 irq 字段中;
- 如果当前处于软中断执行上下文, 那么统计到 softirq 字段中;
- 否则统计到 system 字段中。
判断好要加到哪个统计项中后,依次调用 account_system_index_time、task_group_account_field 来将这段时间加到内核变量 kernel_cpustat 中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,
u64 tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
}
3.3 空闲时间的累积
没错,在内核变量 kernel_cpustat 中不仅仅是统计了各种用户态、内核态的使用时间,空闲也一并统计起来了。
如果在采样的瞬间,cpu 既不在内核态也不在用户态的话,就将当前节拍的时间都累加到 idle 中。
//file:kernel/sched/cputime.c
void account_idle_time(u64 cputime)
{
u64 *cpustat = kcpustat_this_cpu->cpustat;
struct rq *rq = this_rq();
if (atomic_read(&rq->nr_iowait) > 0)
cpustat[CPUTIME_IOWAIT] += cputime;
else
cpustat[CPUTIME_IDLE] += cputime;
}
在 cpu 空闲的情况下,进一步判断当前是不是在等待 IO(例如磁盘 IO),如果是的话这段空闲时间会加到 iowait 中,否则就加到 idle 中。从这里,我们可以看到 iowait 其实是 cpu 的空闲时间,只不过是在等待 IO 完成而已。
看到这里,开篇问题 3 也有非常明确的答案了,io wait 其实是 cpu 在空闲状态的一项统计,只不过这种状态和 idle 的区别是 cpu 是因为等待 io 而空闲。
四、总结
本文深入分析了 Linux 统计系统 CPU 利用率的内部原理。全文的内容可以用如下一张图来汇总:
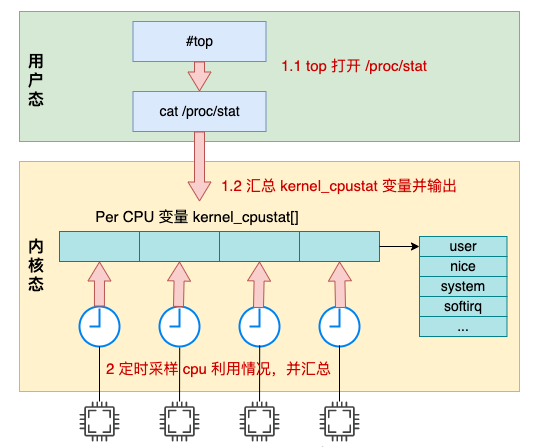
Linux 中的定时器会以某个固定节拍,比如 1 ms 一次采样各个 cpu 核的使用情况,然后将当前节拍的所有时间都累加到 user/nice/system/irq/softirq/io_wait/idle 中的某一项上。
top 命令是读取的 /proc/stat 中输出的 cpu 各项利用率数据,而这个数据在内核中是根据 kernel_cpustat 来汇总并输出的。
回到开篇问题 1,top 输出的利用率信息是如何计算出来的,它精确吗?
/proc/stat 文件输出的是某个时间点的各个指标所占用的节拍数。如果想像 top 那样输出一个百分比,计算过程是分两个时间点 t1, t2 分别获取一下 stat 文件中的相关输出,然后经过个简单的算术运算便可以算出当前的 cpu 利用率。
再说是否精确。这个统计方法是采样的,只要是采样,肯定就不是百分之百精确。但由于我们查看 cpu 使用率的时候往往都是计算 1 秒甚至更长一段时间的使用情况,这其中会包含很多采样点,所以查看整体情况是问题不大的。
另外从本文,我们也学到了 top 中输出的 cpu 时间项目其实大致可以分为三类:
第****一类:用户态消耗时间,包括 user 和 nice。如果想看用户态的消耗,要将 user 和 nice 加起来看才对。
第二类:内核态消耗时间,包括 irq、softirq 和 system。
第三类:空闲时间,包括 io_wait 和 idle。其中 io_wait 也是 cpu 的空闲状态,只不过是在等 io 完成而已。如果只是想看 cpu 到底有多闲,应该把 io_wait 和 idle 加起来才对。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment supprimer des fichiers en utilisant la ligne de commande Linux ? (exemple de code)
- 5 exemples wget pour télécharger des fichiers sur la ligne de commande Linux
- Comment attribuer un mot de passe à l'utilisateur dans un script shell
- Comment cingler le réseau sous Linux
- Comment trouver l'emplacement d'un fichier sous Linux