
Maison >Tutoriel système >Linux >Comprenez l'état de santé de Linux en 61 secondes !
Comprenez l'état de santé de Linux en 61 secondes !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-14 10:45:021356parcourir
En tant que fondement de tous les programmes, le système d'exploitation a un impact important sur les performances des applications. Or, les différences de vitesse entre les différents composants d’un ordinateur sont très importantes. Par exemple, la différence de vitesse entre un processeur et un disque dur est supérieure à la différence de vitesse entre un lapin et une tortue.
Ci-dessous, nous présenterons brièvement les bases du CPU, de la mémoire et des E/S, et présenterons quelques commandes pour évaluer leurs performances.
1.CPU
Présentez d’abord le composant informatique le plus important de l’ordinateur : l’unité centrale de traitement. Généralement, nous pouvons observer ses performances via la commande top.
1.1 commande supérieure
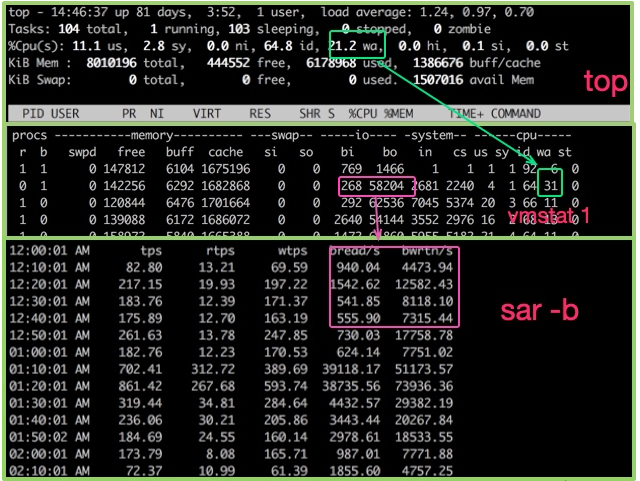
Cliquez sur la touchetop命令可用于观测CPU的一些运行指标。如图,进入top命令之后,按1 pour voir l'état détaillé de chaque processeur principal.
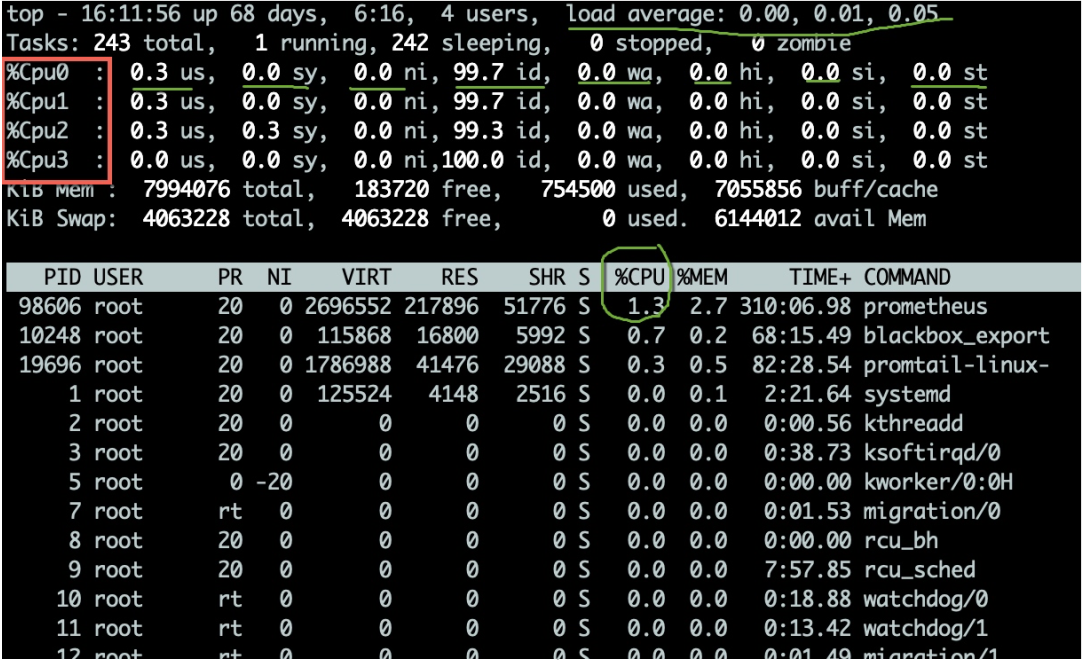
L'utilisation du processeur a plusieurs indicateurs, qui sont expliqués ci-dessous :
- us Le pourcentage de CPU occupé par le mode utilisateur.
- sy Le pourcentage de CPU occupé par le mode noyau. Si cette valeur est trop élevée, vous devez coopérer avec la commande vmstat pour vérifier si les changements de contexte sont fréquents.
- ni Le pourcentage de CPU occupé par les applications hautement prioritaires.
- wa Le pourcentage de CPU occupé par l'attente des périphériques d'E/S. Si cette valeur est très élevée, il peut y avoir un goulot d'étranglement important dans le périphérique d'entrée et de sortie.
- salut Le pourcentage de CPU occupé par les interruptions matérielles.
- si Le pourcentage de CPU occupé par des interruptions logicielles.
- st Cela se produit généralement sur les machines virtuelles et fait référence au pourcentage de temps pendant lequel le processeur virtuel attend le processeur réel. Si cette valeur est trop grande, votre hôte risque de subir trop de pression. Si vous êtes un hébergeur cloud, votre fournisseur de services vend peut-être trop.
- id Pourcentage de CPU inactif.
En général, nous accordons plus d'attention au pourcentage de CPU inactif, qui peut refléter l'utilisation globale du CPU.
1.2 Qu'est-ce que la charge
Nous devons également évaluer la situation de file d'attente pour l'exécution des tâches CPU, ces valeurssont 负载(load). La charge CPU affichée par la commande top correspond respectivement aux valeurs des dernières 1 minute, 5 minutes et 15 minutes.
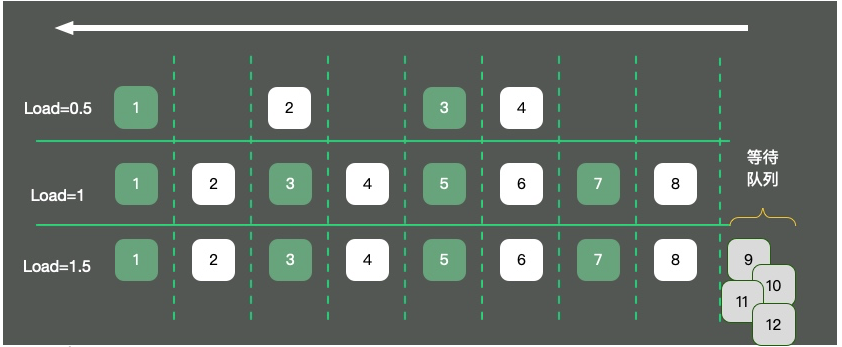
Comme le montre la figure, en prenant comme exemple un système d'exploitation monocœur, les ressources CPU sont abstraites dans une route à sens unique. Trois situations vont se produire :
-
Il n'y a que
4voitures sur la route, la circulation est fluide et la charge est d'environ 0,5. - Il y a 8 voitures sur la route, qui peuvent passer bout à bout en toute sécurité. À l'heure actuelle, la charge est d'environ 1.
- Il y a 12 voitures sur la route En plus des 8 voitures sur la route, il y a 4 voitures qui attendent à l'extérieur de la route et doivent faire la queue. À l'heure actuelle, la charge est d'environ 1,5.
Que signifie la charge 1 ? Il existe encore de nombreux malentendus sur cette question.
De nombreux étudiants pensent que lorsque la charge atteint 1, le système atteint un goulot d'étranglement. Ce n'est pas tout à fait exact. La valeur de la charge est étroitement liée au nombre de cœurs de processeur. Les exemples sont les suivants :
- La charge d'un seul noyau atteint 1 et la valeur de charge totale est d'environ 1.
- La charge sur chaque cœur du dual-core atteint 1 et la charge totale est d'environ 2.
- Chacun des quatre cœurs a une charge de 1 et la charge totale est d'environ 4.
Donc, pour une machine 16 cœurs avec une charge de 10, votre système est loin d'atteindre la limite de charge. Grâce à la commande uptime, vous pouvez également voir l'état de charge.
1.3 vmstat
Pour voir à quel point le processeur est occupé, vous pouvez également utiliser la commande vmstat. Voici quelques informations de sortie de la commande vmstat.
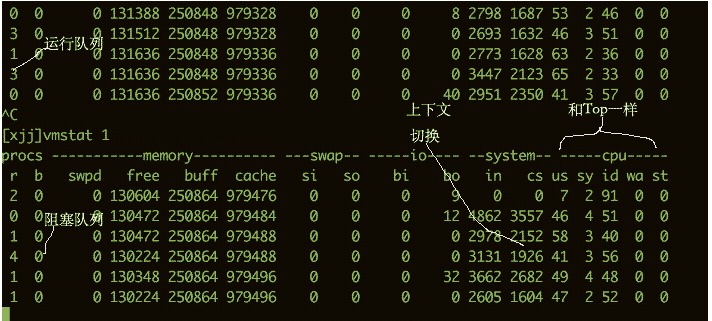
Nous sommes plus préoccupés par les colonnes suivantes :
-
bLe nombre de threads du noyau existant dans la file d'attente, comme l'attente d'E/S, etc. Si le nombre est trop grand, le processeur sera trop occupé. -
csreprésente le nombre de changements de contexte. Si le changement de contexte est effectué fréquemment, vous devez vous demander si le nombre de threads est trop important. -
si/soMontre une certaine utilisation des partitions d'échange. Les partitions d'échange ont un plus grand impact sur les performances et nécessitent une attention particulière.
$ vmstat 1 procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0 32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0 32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0 32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0 32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0 ^C
2. Mémoire
2.1 Commande d'observation
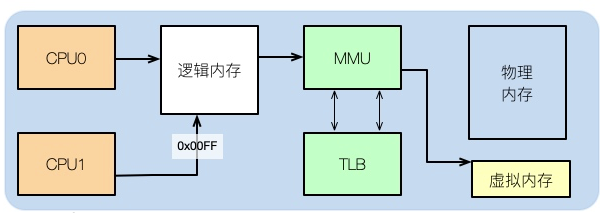
Pour comprendre une partie de l'impact de la mémoire sur les performances, vous devez examiner la répartition de la mémoire au niveau du système d'exploitation.
Après avoir fini d'écrire le code, par exemple, si nous écrivons un programme C++, si nous regardons son assemblage, nous pouvons voir que l'adresse mémoire qu'il contient n'est pas l'adresse mémoire physique réelle.
Ensuite, ce que l'application utilise, c'est la mémoire logique. Les étudiants qui ont étudié la structure des ordinateurs le savent tous.
Les adresses logiques peuvent être mappées sur la mémoire physique et la mémoire virtuelle. Par exemple, si votre mémoire physique est de 8 Go et qu'une partition SWAP de 16 Go est allouée, la mémoire totale disponible pour l'application est de 24 Go.
Vous pouvez voir plusieurs colonnes de données à partir de la commande supérieure. Faites attention aux trois zones délimitées par les carrés. L'explication est la suivante :
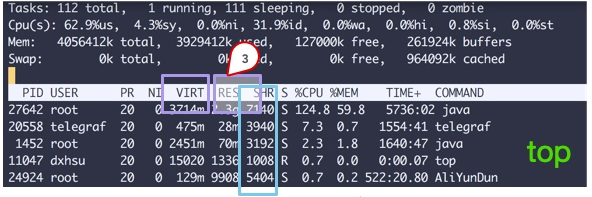
- VIRT Il s'agit de mémoire virtuelle, qui est généralement relativement volumineuse, vous n'avez donc pas besoin d'y prêter trop d'attention.
- RES Ce à quoi nous prêtons habituellement attention, c'est la valeur de cette colonne, qui représente la mémoire réellement occupée par le processus. Habituellement, lors de la surveillance, cette valeur est principalement surveillée.
- SHR fait référence à la mémoire partagée, comme certains fichiers so qui peuvent être réutilisés.
Cache CPU 2.2
Étant donné que la différence de vitesse entre les cœurs du processeur et les mémoires est très importante, la solution consiste à ajouter du cache. En fait, ces caches comportent souvent plusieurs couches, comme le montre la figure ci-dessous.
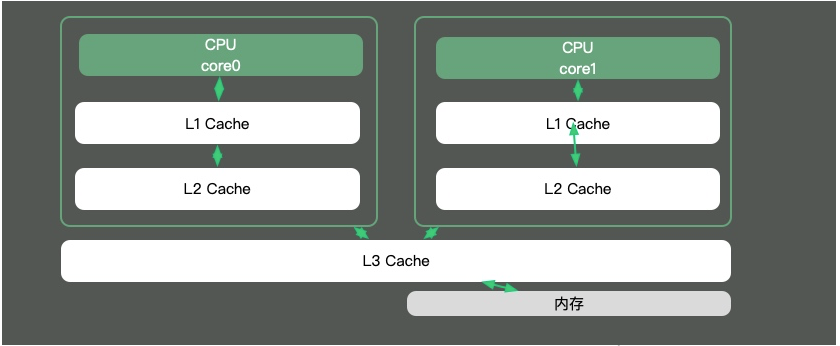
La plupart des points de connaissances en Java concernent le multi-threading. En effet, si la tranche de temps d'un thread s'étend sur plusieurs processeurs, il y aura des problèmes de synchronisation.
在Java中,最典型的和CPU缓存相关的知识点,就是并发编程中,针对Cache line的伪共享(false sharing)问题。
伪共享是指:在这些高速缓存中,是以缓存行为单位进行存储的。哪怕你修改了缓存行中一个很小很小的数据,它都会整个的刷新。所以,当多线程修改一些变量的值时,如果这些变量在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
通过以下命令即可看到当前操作系统的缓存行大小。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通过以下命令可以看到不同层次的缓存大小。
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size 32K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size 256K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size 20480K
在JDK8以上的版本,通过开启参数-XX:-RestrictContended,就可以使用注解@sun.misc.Contended进行补齐,来避免伪共享的问题。在并发优化中,我们再详细讲解。
2.3 HugePage
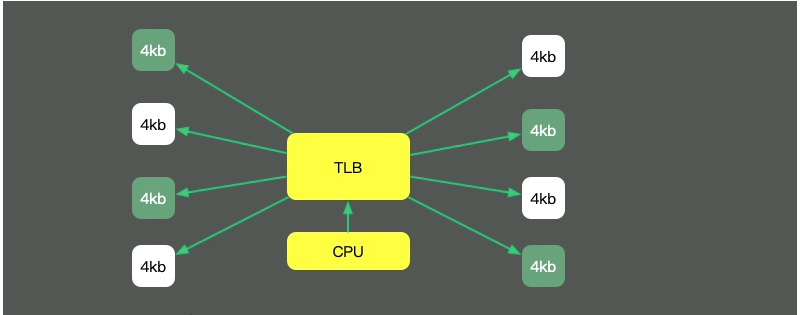
回头看我们最长的那副图,上面有一个叫做TLB的组件,它的速度虽然高,但容量也是有限的。这就意味着,如果物理内存很大,那么映射表的条目将会非常多,会影响CPU的检索效率。
默认内存是以4K的page来管理的。如图,为了减少映射表的条目,可采取的办法只有增加页的尺寸。像这种将Page Size加大的技术,就是Huge Page。
HugePage有一些副作用,比如竞争加剧,Redis还有专门的研究(https://redis.io/topics/latency) ,但在一些大内存的机器上,开启后会一定程度上增加性能。
2.4 预先加载
另外,一些程序的默认行为,也会对性能有所影响。比如JVM的-XX:+AlwaysPreTouch参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,但它的内存在真正用到时,才会分配。
但如果加上这个参数,JVM就会在启动的时候,把所有的内存预先分配。这样,启动时虽然慢了些,但运行时的性能会增加。
3.I/O
3.1 观测命令
I/O设备可能是计算机里速度最差的组件了。它指的不仅仅是硬盘,还包括外围的所有设备。
硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,仅作参考)。
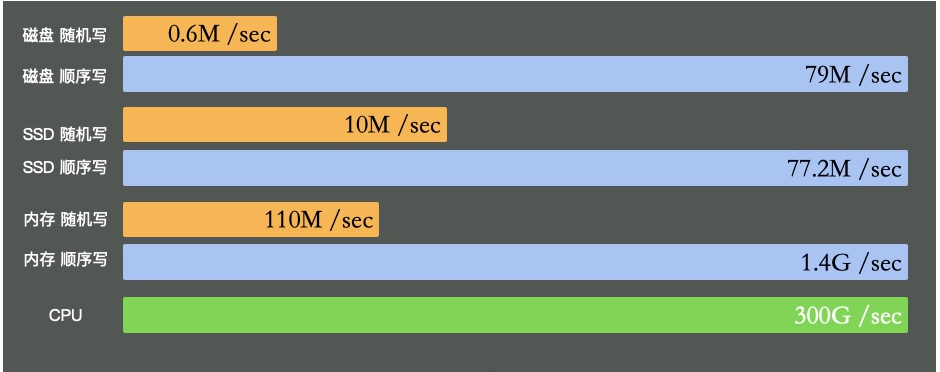
可以看到普通磁盘的随机写和顺序写相差是非常大的。而随机写完全和cpu内存不在一个数量级。
缓冲区依然是解决速度差异的唯一工具,在极端情况比如断电等,就产生了太多的不确定性。这些缓冲区,都容易丢。
La meilleure façon de refléter l'activité des E/S est la commande supérieure et vmstat命令中的wa%. Si votre application écrit beaucoup de journaux, l'attente d'E/S peut être très longue.
Pour les disques durs, vous pouvez utiliser la commande iostat pour afficher l'utilisation spécifique du matériel. Tant que %util dépasse 80 %, votre système ne pourra pratiquement pas fonctionner.
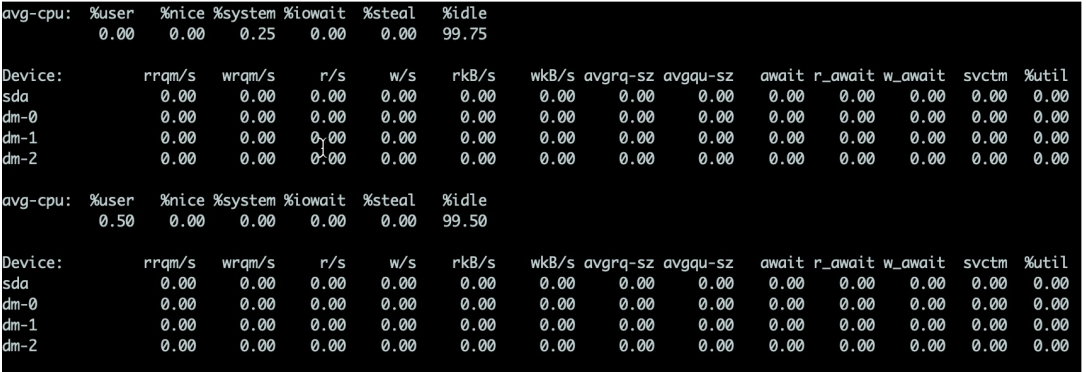
Les détails sont les suivants :
- %util Le paramètre de jugement le plus important. Généralement, si ce paramètre est à 100%, cela signifie que l'équipement fonctionne presque à pleine capacité
- Device indique sur quel disque dur l'événement se produit. Si vous êtes rapide, plusieurs lignes s'afficheront
- avgqu-sz Cette valeur est la saturation de la file d'attente des requêtes, qui est la longueur moyenne de la file d'attente des requêtes. Il ne fait aucun doute que plus la file d’attente est courte, mieux c’est.
- attendez Le temps de réponse doit être inférieur à 5 ms, s'il est supérieur à 10 ms, il sera plus long. Ce temps comprend le temps d'attente et le temps de service
-
svctm signifie que l'attente moyenne dans la file d'attente par fois que l'appareil
I/O操作的服务时间。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/Oest trop longue et que les applications exécutées sur le système ralentiront.
3.2 Zéro copie
L'une des raisons pour lesquelles Kafka est plus rapide est qu'il n'utilise aucune copie. Ce qu'on appelle la copie zéro signifie que lors de l'exploitation des données, il n'est pas nécessaire de copier le tampon de données d'une zone mémoire à une autre. Puisqu’il y a une copie de mémoire en moins, l’efficacité du processeur est améliorée.
Jetons un coup d'œil aux différences entre eux :
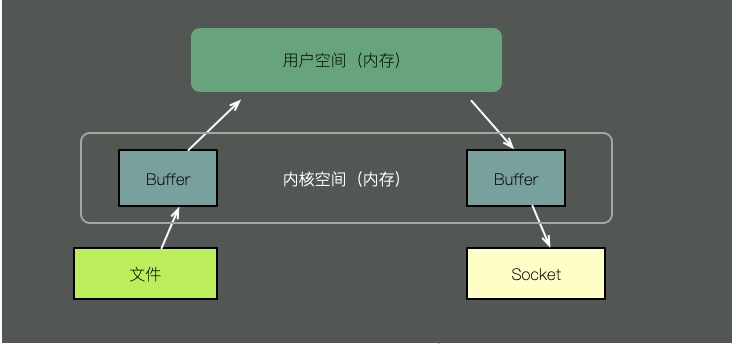
Pour envoyer le contenu d'un fichier via une socket, la méthode traditionnelle nécessite les étapes suivantes :
- Copiez le contenu du fichier dans l'espace du noyau.
- Copiez le contenu de l'espace noyau dans la mémoire de l'espace utilisateur, comme une application Java.
- L'espace utilisateur écrit le contenu dans le cache de l'espace noyau.
- Le socket lit le contenu du cache du noyau et l'envoie.
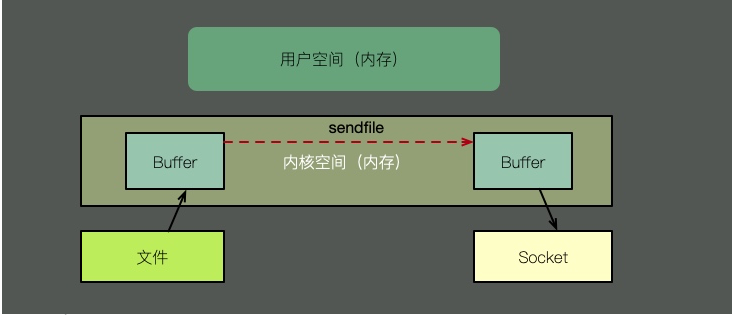
Zéro copie et modes multiples, utilisons sendfile pour illustrer. Comme le montre la figure ci-dessus, avec la prise en charge du noyau, zéro copie comporte une étape de moins, qui est la copie du cache du noyau dans l'espace utilisateur. C’est-à-dire qu’il économise de la mémoire et du temps de planification du CPU, ce qui est très efficace.
4.网络
除了iotop、iostat这些命令外,sar命令可以方便的看到网络运行状况,下面是一个简单的示例,用于描述入网流量和出网流量。
$ sar -n DEV 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00 12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00 12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00 12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00 12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C
当然,我们可以选择性的只看TCP的一些状态。
$ sar -n TCP,ETCP 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:17:19 AM active/s passive/s iseg/s oseg/s 12:17:20 AM 1.00 0.00 10233.00 18846.00 12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:20 AM 0.00 0.00 0.00 0.00 0.00 12:17:20 AM active/s passive/s iseg/s oseg/s 12:17:21 AM 1.00 0.00 8359.00 6039.00 12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:21 AM 0.00 0.00 0.00 0.00 0.00 ^C
5.End
不要寄希望于这些指标,能够立刻帮助我们定位性能问题。这些工具,只能够帮我们大体猜测发生问题的地方,它对性能问题的定位,只是起到辅助作用。想要分析这些bottleneck,需要收集更多的信息。
想要获取更多的性能数据,就不得不借助更加专业的工具,比如基于eBPF的BCC工具,这些牛x的工具我们将在其他文章里展开。读完本文,希望你能够快速的了解Linux的运行状态,对你的系统多一些掌控。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!