
Maison >Tutoriel système >Linux >Lâchez-moi, le processeur du système Linux est plein à 100 % !
Lâchez-moi, le processeur du système Linux est plein à 100 % !

- WBOYavant
- 2024-02-13 23:27:121217parcourir
Hier après-midi, j'ai soudainement reçu une alerte e-mail du service d'exploitation et de maintenance, qui montrait que le taux d'utilisation du processeur du serveur de la plateforme de données atteignait 98,94 %. Ces derniers temps, ce taux d'utilisation est resté supérieur à 70 %. À première vue, il semble que les ressources matérielles aient atteint un goulot d'étranglement et doivent être étendues. Mais après y avoir réfléchi attentivement, j'ai découvert que notre système d'entreprise n'est pas une application hautement concurrente ou gourmande en CPU. Ce taux d'utilisation est trop exagéré et le goulot d'étranglement matériel ne peut pas être atteint aussi rapidement. Il doit y avoir un problème avec la logique du code métier quelque part.
2. Idées de dépannage
2.1 Localiser le pid du processus à charge élevée
Connectez-vous d'abord au serveur et utilisez la commande top pour confirmer la situation spécifique du serveur, puis analysez et jugez en fonction de la situation spécifique.

En observant la charge moyenne et la norme d'évaluation de charge (8 cœurs), on peut confirmer que le serveur a une charge élevée
;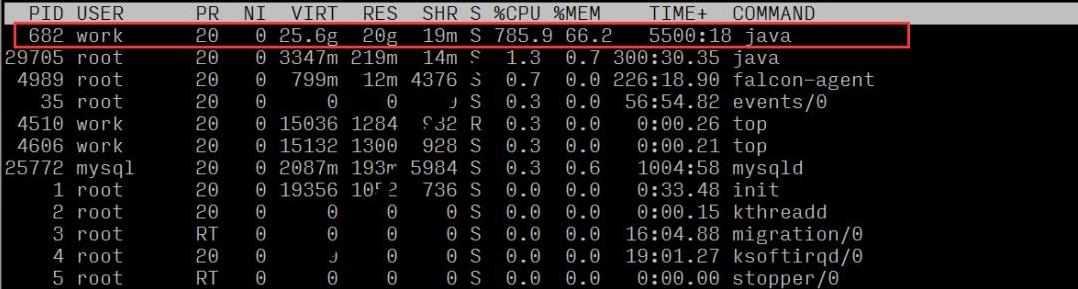
En observant l'utilisation des ressources de chaque processus, nous pouvons voir que le processus portant l'ID de processus 682 a un ratio CPU plus élevé
2.2 Localiser une activité anormale spécifique
Ici, nous pouvons utiliser la commande pwdx pour trouver le chemin du processus métier en fonction du pid, puis localiser le responsable et le projet :

On peut conclure que ce processus correspond au service web de la plateforme de données.
2.3 Localisez le fil anormal et les lignes de code spécifiques
La solution traditionnelle se déroule généralement en 4 étapes :
1. premier ordre par avec P : 1040 // Triez d'abord par charge de processus pour trouver maxLoad(pid)
2. top -Hp process PID : 1073 // Trouvez le PID du thread de chargement approprié
3. printf « 0x%x » PID du fil : 0x431 // Convertissez le PID du fil en hexadécimal pour préparer la recherche ultérieure dans le journal jstack
4. Processus jstack PID | vim +/fil hexadécimal PID – // Par exemple : jstack 1040|vim +/0x431 –
Mais pour la localisation des problèmes en ligne, chaque seconde compte, et les 4 étapes ci-dessus sont encore trop lourdes et prennent beaucoup de temps. Oldratlee, qui a déjà présenté Taobao, a encapsulé le processus ci-dessus dans un outil : show-busy-java-threads.sh. Vous pouvez facilement localiser ce type de problème en ligne :
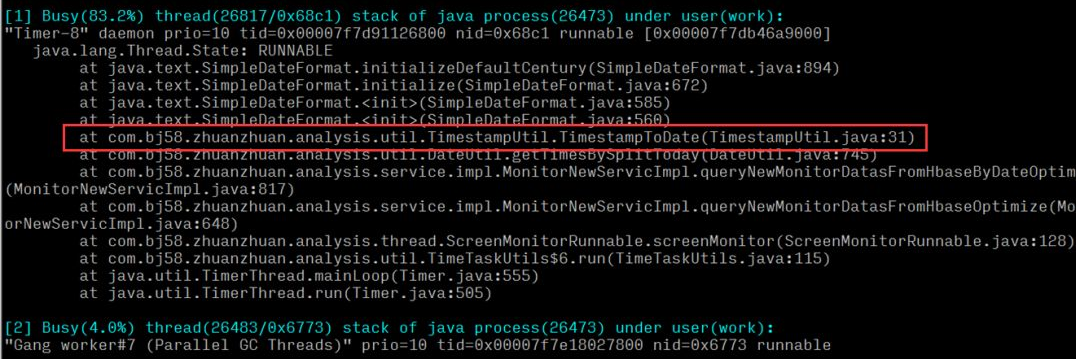
On peut conclure que le processeur d'exécution d'une méthode d'outil temporel dans le système est relativement élevé. Après avoir localisé la méthode spécifique, vérifiez s'il existe des problèmes de performances dans la logique du code.
※ Si le problème en ligne est plus urgent, vous pouvez omettre 2.1 et 2.2 et exécuter directement 2.3. L'analyse ici est sous plusieurs angles juste pour vous présenter une idée d'analyse complète.
3. Analyse des causes profondes
Après l'analyse et le dépannage précédents, nous avons finalement localisé un problème avec les outils de temps, qui entraînait une charge excessive du serveur et une utilisation excessive du processeur.
- Logique de la méthode d'exception : consiste à convertir l'horodatage dans le format de date et d'heure spécifique correspondant ; Appel de la couche supérieure :
- Calculez toutes les secondes depuis le petit matin jusqu'à l'heure actuelle, convertissez-les dans le format correspondant et mettez-les dans l'ensemble pour renvoyer le résultat ; Couche logique : Correspond à la logique de requête du rapport en temps réel de la plateforme de données. Le rapport en temps réel arrivera à un intervalle de temps fixe et il y aura plusieurs (n) appels de méthode dans une requête.
- Ensuite, on peut conclure que si l'heure actuelle est 10 heures du matin, le nombre de calculs pour une requête est de 1060 60
n calculs, et à mesure que le temps augmente, le nombre Le nombre de requêtes uniques se rapproche de minuit et augmentera de manière linéaire. Étant donné qu'un grand nombre de requêtes de requêtes provenant de modules tels que les requêtes en temps réel et les alarmes en temps réel nécessitent d'appeler cette méthode plusieurs fois, une grande quantité de ressources CPU est occupée et gaspillée. 4.Solution
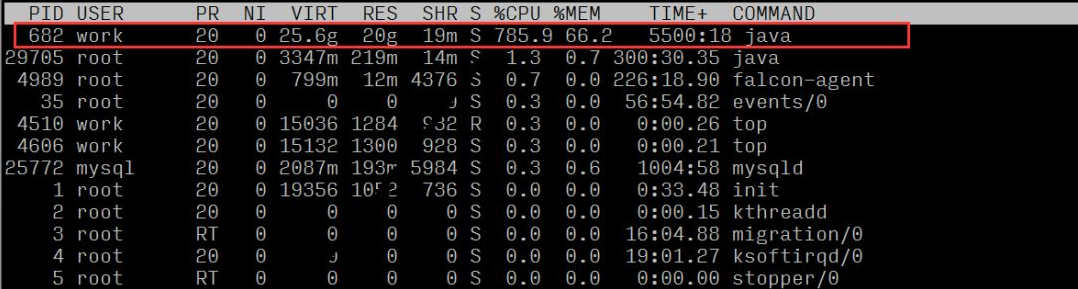
Après avoir localisé le problème, la première considération est de réduire le nombre de calculs et d'optimiser la méthode des exceptions. Après enquête, il a été constaté que lorsqu'il était utilisé au niveau de la couche logique, le contenu de la collection d'ensembles renvoyé par cette méthode n'était pas utilisé, mais la valeur de taille de l'ensemble était simplement utilisée. Après avoir confirmé la logique, simplifiez le calcul grâce à une nouvelle méthode (secondes actuelles - secondes tôt le matin), remplacez la méthode appelée et résolvez le problème des calculs excessifs. Après la mise en ligne, nous avons observé la charge du serveur et l'utilisation du processeur. Par rapport à la période anormale, la charge du serveur et l'utilisation du processeur ont diminué de 30 fois et sont revenues à la normale.  En observant l'utilisation des ressources de chaque processus, nous pouvons voir que le processus portant l'ID de processus 682 a un ratio CPU plus élevé
En observant l'utilisation des ressources de chaque processus, nous pouvons voir que le processus portant l'ID de processus 682 a un ratio CPU plus élevé
2.2 Localiser une activité anormale spécifique
Ici, nous pouvons utiliser la commande pwdx pour trouver le chemin du processus métier en fonction du pid, puis localiser le responsable et le projet :
On peut conclure que ce processus correspond au service web de la plateforme de données.

2.3 Localisez le fil anormal et les lignes de code spécifiques
La solution traditionnelle se déroule généralement en 4 étapes :
1. premier trieur par avec P : 1040 // Triez d'abord par charge de processus pour trouver maxLoad(pid)
2. top -Hp process PID : 1073 // Trouvez le PID du thread de chargement approprié
3. printf « 0x%x » PID du fil : 0x431 // Convertissez le PID du fil en hexadécimal pour préparer la recherche ultérieure dans le journal jstack
4. Processus jstack PID | vim +/fil hexadécimal PID – // Par exemple : jstack 1040|vim +/0x431 –
Mais pour la localisation des problèmes en ligne, chaque seconde compte, et les 4 étapes ci-dessus sont encore trop lourdes et prennent beaucoup de temps. Oldratlee, qui a déjà présenté Taobao, a encapsulé le processus ci-dessus dans un outil : show-busy-java-threads.sh. Vous pouvez facilement localiser ce type de problème en ligne :
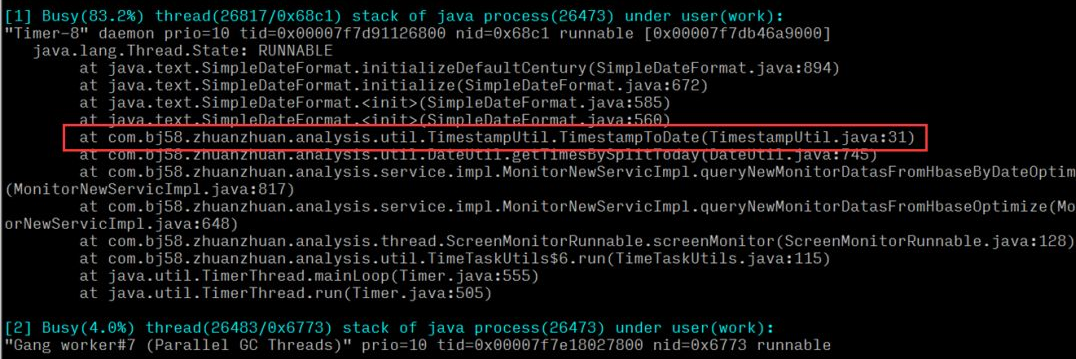
On peut conclure que le processeur d'exécution d'une méthode d'outil temporel dans le système est relativement élevé. Après avoir localisé la méthode spécifique, vérifiez s'il existe des problèmes de performances dans la logique du code.
※ Si le problème en ligne est plus urgent, vous pouvez omettre 2.1 et 2.2 et exécuter directement 2.3. L'analyse ici est sous plusieurs angles juste pour vous présenter une idée d'analyse complète.
3. Analyse des causes profondes
Après l'analyse et le dépannage précédents, nous avons finalement localisé un problème d'outil de temps, qui entraînait une charge excessive du serveur et une utilisation excessive du processeur.
- Logique de la méthode d'exception : consiste à convertir l'horodatage dans le format de date et d'heure spécifique correspondant ; Appel de la couche supérieure :
- Calculez toutes les secondes depuis le petit matin jusqu'à l'heure actuelle, convertissez-les dans le format correspondant et mettez-les dans l'ensemble pour renvoyer le résultat ; Couche logique : Correspond à la logique de requête du rapport en temps réel de la plateforme de données. Le rapport en temps réel arrivera à un intervalle de temps fixe et il y aura plusieurs (n) appels de méthode dans une requête.
- Ensuite, on peut conclure que si l'heure actuelle est 10 heures du matin, le nombre de calculs pour une requête est de 1060 60
n calculs, et à mesure que le temps augmente, le nombre Le nombre de requêtes uniques se rapproche de minuit et augmentera de manière linéaire. Étant donné qu'un grand nombre de requêtes de requêtes provenant de modules tels que les requêtes en temps réel et les alarmes en temps réel nécessitent d'appeler cette méthode plusieurs fois, une grande quantité de ressources CPU est occupée et gaspillée. 4.Solution
Après avoir localisé le problème, la première considération est de réduire le nombre de calculs et d'optimiser la méthode des exceptions. Après enquête, il a été constaté que lorsqu'il était utilisé au niveau de la couche logique, le contenu de la collection d'ensembles renvoyé par cette méthode n'était pas utilisé, mais la valeur de taille de l'ensemble était simplement utilisée. Après avoir confirmé la logique, simplifiez le calcul grâce à une nouvelle méthode (secondes actuelles - secondes tôt le matin), remplacez la méthode appelée et résolvez le problème des calculs excessifs. Après la mise en ligne, nous avons observé la charge du serveur et l'utilisation du processeur. Par rapport à la période anormale, la charge du serveur et l'utilisation du processeur ont diminué de 30 fois et sont revenues à la normale.
5.Résumé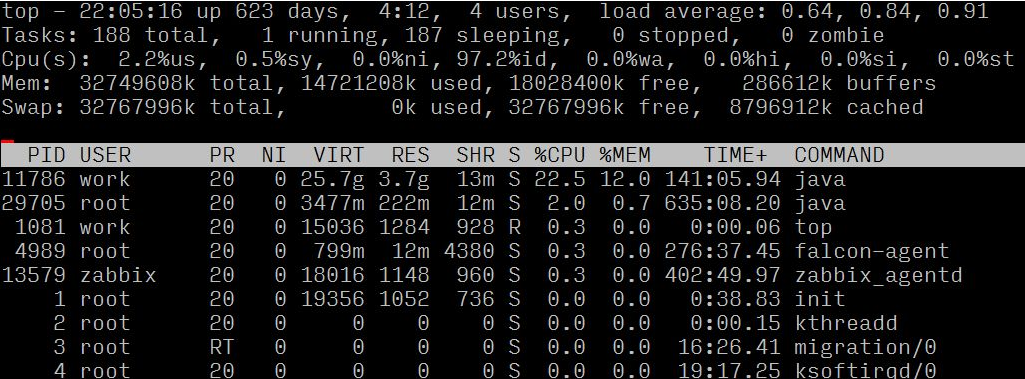
Pendant le processus de codage, en plus de mettre en œuvre la logique métier, nous devons également nous concentrer sur l’optimisation des performances du code. La capacité à répondre à une exigence commerciale et la capacité à y parvenir de manière plus efficace et plus élégante sont en fait deux manifestations complètement différentes des capacités et des domaines des ingénieurs, et cette dernière constitue également le cœur de la compétitivité des ingénieurs.
-
Une fois le code écrit, effectuez davantage de révisions et réfléchissez davantage à la question de savoir s'il peut être mieux implémenté.
- Ne manquez aucun petit détail dans les questions en ligne ! Les détails sont le diable. Les étudiants techniques doivent avoir la soif de connaissances et l'esprit de recherche de l'excellence. Ce n'est qu'ainsi qu'ils pourront continuer à grandir et à s'améliorer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!