
Maison >Tutoriel système >Linux >N'oubliez pas de marcher sur le 'puits' de MySQL dans la sous-requête
N'oubliez pas de marcher sur le 'puits' de MySQL dans la sous-requête

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-13 18:12:27864parcourir
MySQL est une base de données couramment utilisée dans les projets, et dans les requêtes est également très couramment utilisée. Lors du récent débogage du projet, j'ai rencontré une requête de sélection inattendue, qui a en fait pris 33 secondes !
1. tableau d'informations utilisateur

2. tableau des articles
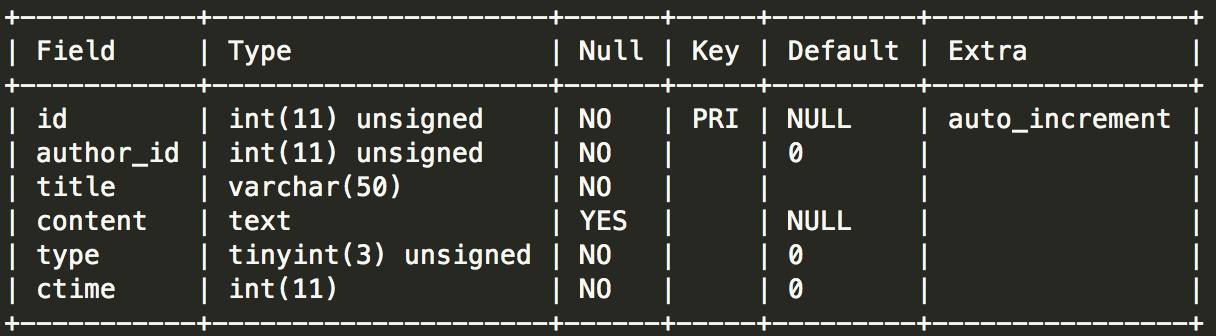
select*fromuserinfowhereidin(selectauthor_idfromartilcewheretype=1);
Lorsque vous voyez pour la première fois le SQL ci-dessus, vous pensez peut-être qu'il s'agit d'une sous-requête très simple. Recherchez d’abord le author_id, puis utilisez-le pour l’interroger.
S'il existe un index pertinent, ce sera très rapide En terme de démontage, il est le suivant :
1.selectauthor_idfromartilcewheretype=1; 2.select*fromuserinfowhereidin(1,2,3);
Mais le fait est le suivant :
mysql> select count(*) from userinfo;
mysql> select count(*) from article;

mysql> select id,username from userinfo where id in (select author_id from article where type = 1);

33 secondes ! Pourquoi est-ce si lent ?
Explication du document officiel : La clause in est parfois convertie en exist lors de l'interrogation, et est parcourue enregistrement par enregistrement (existant en version 5.5, optimisé en 5.6).

Référence :
https://dev.mysql.com/doc/refman/5.5/en/subquery-optimization.html
1. Utiliser une table temporaire
select id,username from userinfo where id in (select author_id from (select author_id from article where type = 1) as tb);
2. Utilisez rejoindre
select a.id,a.username from userinfo a, article b where a.id = b.author_id and b.type = 1;
La version 5.6 a été optimisée pour les sous-requêtes. La méthode est la même que la méthode des tables temporaires dans [4].
Si la matérialisation n'est pas utilisée, l'optimiseur réécrit parfois une sous-requête non corrélée en sous-requête corrélée.
Par exemple, la sous-requête IN suivante n'est pas corrélée (where_condition implique uniquement les colonnes de t2 et non de t1) :sélectionner * à partir de t1
where t1.a in (sélectionnez t2.b à partir de t2wherewhere_condition);
L'optimiseur
pourrait réécrire ceci sous la forme d'une sous-requête corrélée EXISTS :
sélectionner * à partir de t1where existe (sélectionnez t2.b à partir de t2 oùwhere_condition et t1.a=t2.b);
Matérialisation de sous-requête
l'utilisation d'une table temporaire évite de telles réécritures et permet d'exécuter la sous-requête une seule fois plutôt qu'une fois par ligne de la requête externe.
https://dev.mysql.com/doc/refman/5.6/en/subquery-materialization.htmlL'article provient du compte public WeChat : entretiens techniques de première ligne avec HULK
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Commande Linux pour décompresser le package RPM et introduction à l'utilisation de la commande RPM
- Comment vérifier l'utilisation du processeur sous Linux
- Quelle est la commande pour afficher les processus sous Linux ?
- Que faire si les caractères chinois Linux Red Hat sont tronqués
- Comment vérifier la taille d'un dossier sous Linux