
Maison >Tutoriel système >Linux >Faites le point sur 12 commandes de réglage des performances dans les systèmes Linux.
Faites le point sur 12 commandes de réglage des performances dans les systèmes Linux.

- 王林avant
- 2024-02-13 10:54:311285parcourir
Le réglage des performances a toujours été l'une des tâches les plus importantes des ingénieurs d'exploitation et de maintenance. Si vous êtes dans un environnement de production et rencontrez une réponse lente du système, un débit d'E/S du disque dur anormal, une vitesse de traitement des données inférieure à celle prévue, ou si le processeur, la mémoire. , le disque dur, le réseau et les autres ressources système sont épuisés depuis longtemps, alors cet article vous aidera vraiment. Sinon, veuillez d'abord le sauvegarder.

1, vitesse de lecture de la dureté du contrôle hdparm :
命令:hdparm -t /dev/sda5 打印:Timing buffered disk reads: 254 MB in 3.01 seconds = 84.34 MB/sec 说明:能够指定具体的哪块硬盘进行查询的哦!
2, iostat détecte l'état des E/S du disque :
格式:iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval ] 描述:iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况,同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析,每1秒检测统计一次(共5次)。

«
blk_read/s Nombre de blocs de données lus par seconde
blk_wrtn/s Nombre de blocs de données écrits par seconde
blk_read représente le nombre de tous les blocs de données lus
blk_wrtn représente le nombre de tous les blocs de données écrits
”
3, vmstat signale l'état de la mémoire et du processeur :
名称:报告虚拟内存的统计信息 格式:vmstat [-n] [延时[次数]]

| R: | 运行和等待CPU时间片的进程数。Si le nombre est supérieur au CPU pendant une longue période, cela signifie que le CPU est insuffisant |
|---|---|
| B: | Le nombre de processus en attente de ressources. Si le nombre d'attentes est important, le problème peut être lié aux E/S ou à la mémoire | .
| Swpd : | Passer à la taille de la mémoire de la zone d'échange de mémoire [en Ko] |
| gratuit : | La quantité actuelle de mémoire physique libre [en Ko] |
| si: | Transfert du disque vers la mémoire |
| donc : | Transfert de la mémoire vers le disque |
| bi: | La quantité totale de données lues à partir du périphérique de blocage |
| bo: | La quantité totale de données écrites sur le périphérique de blocage |
| bi+bo | 1000 S'il dépasse 1000, cela signifie qu'il y a un problème avec la vitesse de lecture et d'écriture du disque dur |
| dans : | Le nombre d'interruptions de périphérique par seconde observées dans un certain intervalle de temps [trop d'interruptions nuisent aux performances] |
| cs: | La colonnereprésente le nombre de changements de contexte générés par seconde |
| nous+sy > 80% | Représente des ressources CPU insuffisantes |
| nous : | Pourcentage de temps CPU consommé par les processus utilisateur |
| sy: | Pourcentage de temps CPU consommé par les processus du noyau |
| identifiant : | Pourcentage de temps pendant lequel le processeur est inactif |
| wa: | Pourcentage de temps passé à attendre l'IO |
| runq-sz : | Nombre de processus pouvant s'exécuter en mémoire |
| plist-sz : | Nombre de tâches actives dans le système |
显示详细信息
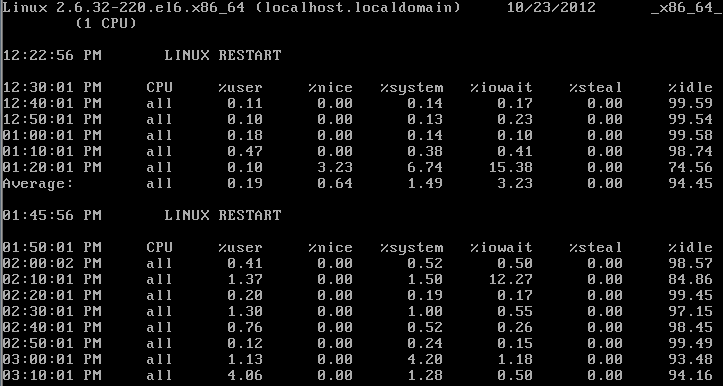
4,sar检测CPU资源:
任务计划 /etc/cron.d/sysstat 日志目录 /var/log/sa 查看方法 Sar –q –f /var/log/sa/sa10
5,lscpu显示CPU信息:
dmesg 显示出开机启动的信息 lscpu 显示CPU信息 lscpu -p 显示CPU对应的节点数 getconf LONG_BIT 获知主机的位数 getconf -a 查看全部的参数 /sys/class/dmi/id 可以查看Bios的信息 bios_*
6,strace显示程序的调用:
strace –fc elinks –dump http://localhost
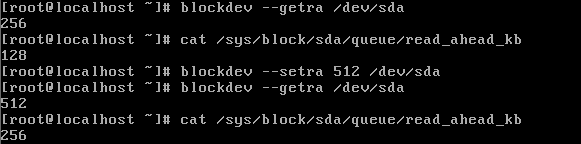
7,调优硬盘优先写入/读取数据用:
“
预先读取需要写入的量,然后再处理写请求,↑读到的值将会是设置值的一半↑。
设置读取到缓存中的数值越大.写入时就会因为数据量大而速度变慢。/sys/block/sda/queue/nr_requests 队列长度越大,硬盘IO速度会提升,但占用内存
/sys/block/sda/queue/scheduler 调度算法Noop、anticipatory、deadline、[cfq]”
8,将Ext3文件系统的日志功能独立:
“
1、创建200M的/dev/sdb1 格式化为ext3 2、dumpe2fs /dev/sdb1查看文件系统功能中包含的has_journal 3、Tune2fs –O ^has_journal /dev/sdb1 去掉默认原有的日志功能 4、再分一个200M的分区./dev/sdb2. 日志卷的block必须等于 /dev/sdb1 Mke2fs –O journal_dev –b 1024 /dev/sdb2 5、将/dev/sdb2作为/dev/sdb1的日志卷. Tune2fs –j –J device=/dev/sdb2 /dev/sdb1”
9,关闭记录文件系统atime:
对于网站文件,频繁的修改atime是没有意义的,会影响性能 mount –o remount,noatime DEVICE 即可
10、修改文件日志的提交时间:
默认是5秒提交一次日志,修改更长时间可以提高性能,但容易丢失数据。 mount –o remount,commit=15 DEVICE
11,RAID轮循写入调优,适用于0/5/6:
“
chunk size.轮循一次写入的字节.默认是64K,只要没有写满,就不会移动到下一个设备
设置在每个硬盘都只写一个文件就切换到下一块硬盘,那么如果都是1K的小文件,就会将系统资源浪费在切换硬盘上
如果将chunk size的值设置很大,比如100M,那么也就没有了意义,还不如用一块硬盘。
Stripe size.条带大小,并不是有数据就写入,而是设置每次写入的数据量,一般是16K写一次。
所以.Chunk size(64K)/stripe size(16K),也就是说每块硬盘写四次。
————————————算当前应该把chunk size调成多少————————————
使用iostat –x查看自开机以来每秒的平均请求数avgrq-sz
chunk size = 每秒请求数*512/1024/磁盘数,取一个最紧接2倍数的整数
stride = chunk size /block(默认是4k)创建raid并设置chunk sinze
mdadm –C /dev/md0 –l 0 –n3 –chunk=8 /dev/sdb[123] 修改raid
mke2fs –j –b 4096 –E stride=2 /dev/md0”
12,硬盘的block保留数:
dumpe2fs /dev/sda1 tune2fs –m 10 /dev/sda1 保留block百分比 tune2fs –r 保留block数 保留的block过少,影响性能,保留的过多又浪费硬盘,默认是5%
学习了上面的性能调优命令和方法后,再总结几条调优的金句:
独立设备性能速度比集成的强,因为不占用主机整体资源
工程师一般不会远程管理计算机,需要提供日志等信息
硬盘空间越大,读取的速度越慢,可以考虑用多块硬盘组成一块较大空间
分区只是在硬盘上做标识,而不像格式化在做文件系统特性,所以速度快
硬盘越靠外侧速度越快[分区号越小越靠外区,所以将数据量大的首先分区].
程序开发者注重雇主的功能要求,系统管理员注重程序的资源开销
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!