
Maison >Tutoriel système >Linux >Explication détaillée des verrous de programmation multithread Linux : comment éviter les conflits et les blocages
Explication détaillée des verrous de programmation multithread Linux : comment éviter les conflits et les blocages

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-11 16:30:22745parcourir
Dans la programmation multithread Linux, les verrous sont un mécanisme très important qui peut éviter la concurrence et les blocages entre les threads. Cependant, si les verrous ne sont pas utilisés correctement, une dégradation des performances et un comportement erratique peuvent en résulter. Cet article présentera les types de verrous courants sous Linux, comment les utiliser correctement et comment éviter les problèmes tels que les conflits et les blocages.
En programmation, le concept de verrouillage mutex d'objet est introduit pour garantir l'intégrité des opérations de données partagées. Chaque objet correspond à une marque appelée « verrouillage mutex », qui permet de garantir qu'un seul thread peut accéder à l'objet à tout moment. Le mécanisme de verrouillage mutex implémenté par Linux comprend les verrous mutex POSIX et les verrous mutex du noyau. Cet article parle principalement des verrous mutex POSIX, c'est-à-dire des verrous mutex inter-thread.
Les sémaphores sont utilisés pour la synchronisation multi-thread et multi-tâches. Lorsqu'un thread termine une certaine action, il informe les autres threads via le sémaphore, et les autres threads effectuent ensuite certaines actions (lorsque tout le monde est en sem_wait, ils y sont bloqués). . Les verrous mutex sont utilisés pour l'exclusion mutuelle multithread et multitâche. Si un thread occupe une certaine ressource, les autres threads ne peuvent pas y accéder. Jusqu'à ce que ce thread soit déverrouillé, d'autres threads peuvent commencer à utiliser cette ressource. Par exemple, l'accès aux variables globales nécessite parfois un verrouillage et un déverrouillage une fois l'opération terminée. Parfois, les serrures et les sémaphores sont utilisés en même temps »
En d'autres termes, un sémaphore ne verrouille pas nécessairement une certaine ressource, mais un concept de processus. Par exemple : il y a deux threads A et B. Le thread B doit attendre que le thread A termine une certaine tâche avant de passer aux étapes suivantes. Cette tâche n'implique pas nécessairement le verrouillage d'une certaine ressource, mais peut également impliquer l'exécution de certains calculs ou traitements de données. Le thread mutex est le concept de « verrouillage d'une certaine ressource ». Pendant la période de verrouillage, les autres threads ne peuvent pas opérer sur les données protégées. Dans certains cas, les deux sont interchangeables.
La différence entre les deux :
Portée
Sémaphore : inter-processus ou inter-thread (linux uniquement inter-thread)
Verrouillage Mutex : entre les threads
Lorsque verrouillé
Sémaphore : tant que la valeur du sémaphore est supérieure à 0, les autres threads peuvent sem_wait avec succès. Après succès, la valeur du sémaphore est réduite de un. Si la valeur n'est pas supérieure à 0, sem_wait se bloque jusqu'à ce que la valeur soit augmentée de un après la libération de sem_post. En un mot, la valeur du sémaphore>=0.
Verrouillage Mutex : tant qu'il est verrouillé, aucun autre thread ne peut accéder à la ressource protégée. S'il n'y a pas de verrou, la ressource est obtenue avec succès, sinon elle se bloque et attend que la ressource soit disponible. En un mot, la valeur d'un thread mutex peut être négative.
Multi-threading
Un thread est la plus petite unité qui s'exécute indépendamment dans un ordinateur et consomme très peu de ressources système lors de son exécution. Par rapport au multi-processus, le multi-processus présente certains avantages que le multi-processus n'a pas. Le plus important est que pour le multi-threading, il peut économiser plus de ressources que le multi-processus.
Création de fil
Sous Linux, le thread nouvellement créé ne fait pas partie du processus d'origine, mais le système appelle clone() via un appel système. Le système copie un processus qui est exactement le même que le processus d'origine et exécute la fonction thread dans ce processus.
Sous Linux, la création de threads s'effectue via la fonction pthread_create() :
pthread_create()
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*st
Parmi eux :
thread représente un pointeur de type pthread_t;
attr est utilisé pour spécifier certains attributs du fil ;
start_routine représente un pointeur de fonction, qui est une fonction d'appel de thread ;
arg représente les paramètres transmis à la fonction appelante du thread.
Lorsque le thread est créé avec succès, la fonction pthread_create() renvoie 0. Si la valeur de retour n'est pas 0, cela signifie que la création du thread a échoué. Pour les attributs de thread, ils sont définis dans la structure pthread_attr_t.
Le processus de création du fil est le suivant :
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
printf("this is a new thread, thread ID is %u\n", newthid);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, NULL) != 0){
printf("thread create failed!\n");
return 1;
}
}
sleep(2);
free(pt);
return 0;
}
Dans le code ci-dessus, la fonction pthread_self() est utilisée. La fonction de cette fonction est d'obtenir l'ID de thread de ce thread. sleep() dans la fonction principale est utilisé pour mettre le processus principal dans un état d'attente afin de permettre à l'exécution du thread de se terminer. L'effet d'exécution final est le suivant :
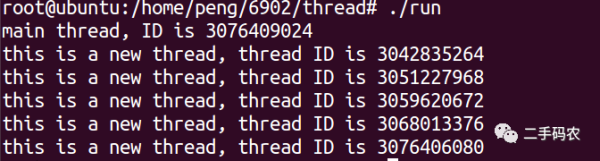
Alors, comment utiliser arg pour passer des paramètres aux sous-threads ? L'implémentation spécifique est la suivante :
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
return NULL;
}
int main(){
//pthread_t thid;
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
sleep(2);
free(pt);
free(id);
return 0;
}
L'effet d'exécution final est illustré dans la figure ci-dessous :
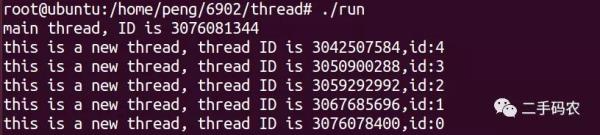
Que se passera-t-il si le processus principal se termine prématurément ? Comme indiqué dans le code suivant :
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
sleep(2);
printf("thread %u is done!\n", newthid);
return NULL;
}
int main(){
//pthread_t thid;
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
//sleep(2);
free(pt);
free(id);
return 0;
}
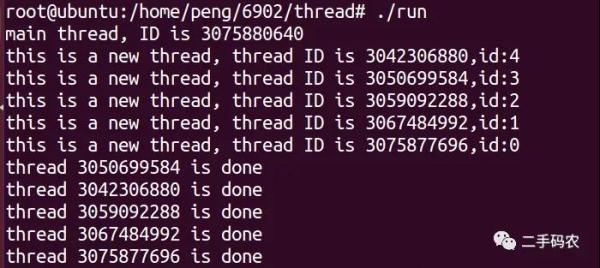
À ce stade, le processus principal se termine plus tôt et le processus recyclera les ressources. À ce moment-là, les threads quitteront l'exécution et les résultats en cours d'exécution sont les suivants :

Le fil pend
Dans le processus d'implémentation ci-dessus, afin de permettre au thread principal d'attendre la fin de chaque sous-thread avant de quitter, la fonction free() est utilisée dans le multithread Linux, la fonction pthread_join() peut également être utilisée pour. attendez d'autres discussions , la forme spécifique de la fonction est :
int pthread_join(pthread_t thread, void **retval);
La fonction pthread_join() permet d'attendre la fin d'un thread, et son appel sera suspendu.
一个线程仅允许一个线程使用pthread_join()等待它的终止。
如需要在主线程中等待每一个子线程的结束,如下述代码所示:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
printf("thread %u is done\n", newthid);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
最终的执行效果如下所示:
注:在编译的时候需要链接libpthread.a:
g++ xx.c -lpthread -o xx
互斥锁mutex
多线程的问题引入
多线程的最大的特点是资源的共享,但是,当多个线程同时去操作(同时去改变)一个临界资源时,会破坏临界资源。如利用多线程同时写一个文件:
#include
#include
const char filename[] = "hello";
void* thread(void *id){
int num = *(int *)id;
// 写文件的操作
FILE *fp = fopen(filename, "a+");
int start = *((int *)id);
int end = start + 1;
setbuf(fp, NULL);// 设置缓冲区的大小
fprintf(stdout, "%d\n", start);
for (int i = (start * 10); i "%d\t", i);
}
fprintf(fp, "\n");
fclose(fp);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
执行以上的代码,我们会发现,得到的结果是混乱的,出现上述的最主要的原因是,我们在编写多线程代码的过程中,每一个线程都尝试去写同一个文件,这样便出现了上述的问题,这便是共享资源的同步问题,在Linux编程中,线程同步的处理方法包括:信号量,互斥锁和条件变量。
互斥锁
互斥锁是通过锁的机制来实现线程间的同步问题。互斥锁的基本流程为:
初始化一个互斥锁:pthread_mutex_init()函数
加锁:pthread_mutex_lock()函数或者pthread_mutex_trylock()函数
对共享资源的操作
解锁:pthread_mutex_unlock()函数
注销互斥锁:pthread_mutex_destory()函数
其中,在加锁过程中,pthread_mutex_lock()函数和pthread_mutex_trylock()函数的过程略有不同:
当使用pthread_mutex_lock()函数进行加锁时,若此时已经被锁,则尝试加锁的线程会被阻塞,直到互斥锁被其他线程释放,当pthread_mutex_lock()函数有返回值时,说明加锁成功;
而使用pthread_mutex_trylock()函数进行加锁时,若此时已经被锁,则会返回EBUSY的错误码。
同时,解锁的过程中,也需要满足两个条件:
解锁前,互斥锁必须处于锁定状态;
必须由加锁的线程进行解锁。
当互斥锁使用完成后,必须进行清除。
有了以上的准备,我们重新实现上述的多线程写操作,其实现代码如下所示:
#include
#include
pthread_mutex_t mutex;
const char filename[] = "hello";
void* thread(void *id){
int num = *(int *)id;
// 加锁
if (pthread_mutex_lock(&mutex) != 0){
fprintf(stdout, "lock error!\n");
}
// 写文件的操作
FILE *fp = fopen(filename, "a+");
int start = *((int *)id);
int end = start + 1;
setbuf(fp, NULL);// 设置缓冲区的大小
fprintf(stdout, "%d\n", start);
for (int i = (start * 10); i "%d\t", i);
}
fprintf(fp, "\n");
fclose(fp);
// 解锁
pthread_mutex_unlock(&mutex);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
// 初始化互斥锁
if (pthread_mutex_init(&mutex, NULL) != 0){
// 互斥锁初始化失败
free(pt);
free(id);
return 1;
}
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
最终的结果为:
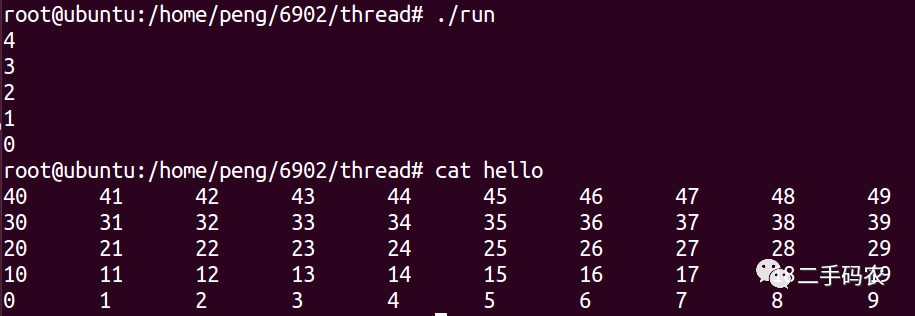
通过本文的介绍,您应该已经了解了Linux多线程编程中的常见锁类型、正确使用锁的方法以及如何避免竞争和死锁等问题。锁机制是多线程编程中必不可少的一部分,掌握它们可以使您的代码更加健壮和可靠。在实际应用中,应该根据具体情况选择合适的锁类型,并遵循最佳实践,以确保程序的高性能和可靠性。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- [Apprentissage Linux] Langage de script Shell
- Résumé des points de connaissances sur les autorisations de fichiers dans l'apprentissage Linux
- Comment installer le fichier iso sous système Linux ?
- Comment vérifier la mémoire système et la taille du disque dur sous Linux
- Analyse de la portée des fermetures et des lambdas en Python