
Maison >Tutoriel système >Linux >Une étude préliminaire sur le cadre d'élagage du noyau Linux
Une étude préliminaire sur le cadre d'élagage du noyau Linux

- 王林avant
- 2024-02-10 17:30:421349parcourir
En raison de l'instabilité du noyau du système d'exploitation, du manque de rapidité, des problèmes d'intégrité et de la nécessité d'une intervention manuelle, la technologie d'élagage du noyau Linux n'a pas été largement utilisée. Après avoir compris les limites de la technologie existante, nous essayons de proposer un cadre d'adaptation du noyau Linux, qui pourrait être en mesure de résoudre ces problèmes.
Vers 2000, le vieux codeur était encore très jeune, à cette époque, il espérait utiliser Linux comme système d'exploitation des téléphones mobiles, alors il a eu l'idée de personnaliser le noyau et a aidé à la pratique. L'effet était plutôt bon et il pouvait déjà exécuter le téléphone portable sur PDA Functional. Plus de 20 ans se sont écoulés et Linux a beaucoup changé, et la technologie et les méthodes d'élagage du noyau ont également été très différentes.
L'élagage du noyau Linux consiste à réduire le code noyau inutile dans les applications cibles, ce qui présente des avantages significatifs en termes de sécurité et de performances (temps de démarrage rapide et empreinte mémoire réduite). Cependant, la technologie d'élagage du noyau existante a ses limites. Existe-t-il une méthode cadre pour l'élagage du noyau ?
1. À propos de la taille des grains
Ces dernières années, les systèmes d'exploitation Linux sont devenus plus complexes et plus étendus. Cependant, une application ne nécessite généralement qu'une partie des fonctionnalités du système d'exploitation, et de nombreuses exigences applicatives conduisent à des noyaux Linux gonflés. La surcharge du noyau du système d'exploitation entraîne également des risques de sécurité, des temps de démarrage plus longs et une utilisation accrue de la mémoire.
Avec la popularité de la servitisation et des microservices, le besoin d’adaptation du noyau s’est encore accru. Dans ces scénarios, les machines virtuelles exécutent de petites applications. Chaque application est souvent « micro » et possède un faible encombrement de noyau. Certaines technologies de virtualisation fournissent le noyau Linux le plus simple pour l'application cible.
Compte tenu de la complexité des systèmes d'exploitation, adapter le noyau en sélectionnant manuellement ses fonctionnalités est quelque peu peu pratique. Par exemple, Linux propose plus de 14 000 options de configuration (à partir de la version 4.14), avec des centaines de nouvelles options introduites chaque année. Les configurateurs de noyau (tels que KConfig) fournissent uniquement une interface utilisateur pour sélectionner les options de configuration. Compte tenu de la mauvaise convivialité et de la documentation incomplète, il est difficile pour les utilisateurs de choisir une configuration de noyau minimale et pratique.
Les techniques existantes de taille des grains suivent généralement trois étapes :
- Exécutez la charge de travail de l'application cible et tracez le code du noyau exécuté pendant l'exécution de l'application ;
- Analysez la trace et déterminez le code noyau requis par l'application cible,
- Assemblez une coupe du noyau qui contient uniquement le code requis par votre application.
La configuration est une approche générale de l'élagage du noyau. La plupart des outils existants utilisent des techniques basées sur la configuration car ils sont l'une des rares technologies capables de produire des noyaux stables. Le rechargement du noyau basé sur la configuration réduit le code du noyau en fonction des caractéristiques fonctionnelles. Les options de configuration correspondent aux fonctionnalités du noyau. Le noyau élagué contient uniquement les fonctionnalités nécessaires pour prendre en charge la charge de travail de l'application cible.
Cependant, bien que la technique d’élagage du noyau soit très attractive en termes de sécurité et de performances, elle n’a pas été largement adoptée dans la pratique. Cela n'est pas dû à un manque de demande : en fait, de nombreux fournisseurs de cloud codent manuellement les noyaux Linux pour réduire le code, mais généralement pas aussi efficacement que les techniques d'élagage du noyau.
2. Limites de la technologie d'élagage du noyau existante
La technologie d'élagage du noyau existante présente cinq limites principales.
Invisible pendant la phase de démarrage. Les techniques existantes ne peuvent démarrer qu'après le démarrage du noyau et s'appuient sur ftrace, il n'y a donc aucun moyen d'observer quel code du noyau est chargé pendant la phase de démarrage. Si des modules critiques sont absents du noyau, celui-ci ne parvient souvent pas à démarrer et un grand nombre de fonctionnalités fonctionnelles du noyau ne peuvent être capturées qu'en observant la phase de démarrage. De plus, les problèmes de performances et de sécurité ne sont également chargés qu'au moment du démarrage (par exemple, CONFIGSCHEDMC et CONFIGSECURITYNETWORK pour la prise en charge multicœur), ce qui entraîne une réduction des performances et de la sécurité.
Manque de prise en charge rapide pour le déploiement d'applications. À l'aide des outils existants, le déploiement d'une nouvelle application adaptée au noyau nécessite de suivre les trois étapes de traçage, d'analyse et d'assemblage. Ce processus prend du temps et peut prendre des heures, voire des jours, ce qui entrave l'agilité du déploiement des applications.
La taille des particules est plus grossière. L'utilisation de ftrace ne peut tracer le code du noyau qu'au niveau de la fonction, et la granularité est trop grossière pour suivre les options de configuration qui affectent le code au sein de la fonction.
Couverture incomplète. Étant donné que le traçage dynamique est utilisé, la charge de travail de l'application est nécessaire pour piloter l'exécution du code du noyau afin d'optimiser la couverture. Cependant, la couverture des tests de référence est difficile, et si l'application possède du code noyau qui n'est pas observé lors de la trace, le noyau découpé peut planter au moment de l'exécution.
Il n'y a aucune distinction entre les dépendances d'exécution et il peut y avoir une redondance. Même le code qui n'a pas réellement besoin d'être exécuté peut être inclus dans les fonctionnalités du noyau, par exemple, il peut initialiser un deuxième système de fichiers.
Les trois premières limitations sont surmontables et peuvent être résolues grâce à une conception et un outillage améliorés, tandis que les deux dernières limitations sont inévitables et nécessitent des efforts au-delà de la technologie spécifique.
3. Configuration du noyau Linux
3.1 Options de configuration
La configuration du noyau consiste en un ensemble d'options de configuration. Un module de noyau peut avoir plusieurs options, chacune contrôlant quel code sera inclus dans le binaire final du noyau.
Les options de configuration contrôlent différentes granularités du code du noyau, telles que les instructions et fonctions implémentées par le préprocesseur C et les fichiers objets implémentés sur la base des Makefiles. Le préprocesseur C sélectionne les blocs de code en fonction de #ifdef/#ifndef, et les options de configuration sont utilisées comme définitions de macro pour déterminer si ces blocs de code conditionnels sont inclus dans le noyau compilé, soit au niveau de la granularité des instructions, soit au niveau de la granularité des fonctions. Makefile est utilisé pour déterminer si certains fichiers objets sont inclus dans le noyau compilé. Par exemple, CONFIG_CACHEFILES est l'option de configuration dans Makefile.
Les options de configuration au niveau des instructions ne peuvent pas être identifiées via le traçage au niveau des fonctions utilisé par les outils de personnalisation du noyau existants. En fait, environ 30 % du préprocesseur C de Linux 4.14 sont des options au niveau des instructions.
Avec la croissance rapide du code du noyau et des fonctionnalités fonctionnelles, le nombre d'options de configuration dans le noyau augmente également rapidement, le noyau Linux 3.0 et supérieur ayant plus de 10 000 options de configuration.
3.2. Langage de configuration
Le noyau Linux utilise le langage de configuration KConfig pour indiquer au compilateur quel code inclure dans le noyau compilé, permettant de définir les options de configuration et les dépendances entre eux.
La valeur d'une option de configuration dans KConfig peut être booléenne, tristate ou constante. bool signifie que le code est soit compilé statiquement dans un binaire du noyau, soit exclu, tandis que tristate permet au code d'être compilé dans un module principal chargeable, c'est-à-dire un objet autonome qui peut être chargé au moment de l'exécution. constant peut fournir une chaîne ou une valeur numérique pour une variable de code du noyau. Une option peut dépendre d'une autre option, et KConfig utilise un processus récursif en sélectionnant et en annulant de manière récursive les dépendances. La configuration finale du noyau a des dépendances valides, mais peut différer des entrées utilisateur.
3.3. Modèle de configuration
Le noyau Linux est livré avec de nombreux modèles de configuration fabriqués à la main. Cependant, en raison de la nature codée en dur des modèles de configuration et de la nécessité d'une intervention manuelle, ils ne sont pas adaptables aux différentes plates-formes matérielles et ne comprennent pas les besoins de l'application. Par exemple, les noyaux construits avec tinyconfig ne peuvent pas démarrer sur du matériel standard, et encore moins prendre en charge d'autres applications. Certains outils traitent localmodconfig comme une configuration minimale, cependant, localmodconfig a les mêmes limitations que les modèles de configuration statiques, il n'active pas les options de configuration du préprocesseur C au niveau des instructions de contrôle ou des fonctions, et il ne gère pas les modules de noyau chargeables.
Les modèles kvmconfig et xenconfig sont personnalisés pour les noyaux exécutés sur KVM et Xen. Ils fournissent des connaissances dans un domaine tel que la virtualisation sous-jacente et l'environnement matériel.
3.4. Configuration du noyau Linux dans le cloud
Linux est le noyau de système d'exploitation dominant dans les services cloud, et les fournisseurs de cloud ont dans une certaine mesure abandonné le noyau Linux ordinaire. La personnalisation par les fournisseurs de cloud est souvent réalisée en supprimant directement les modules de noyau chargeables. Le problème avec l'élagage manuel des binaires des modules de noyau est que les dépendances peuvent être violées. Il est important de noter que les cœurs peuvent être davantage adaptés en fonction des exigences de l'application. Par exemple, le noyau Amazon FireCracker est une petite machine virtuelle conçue pour fonctionner en tant que service, utilisant HTTPD comme application cible, permettant une plus grande minimisation de la personnalisation du noyau tout en garantissant des fonctionnalités et des performances accrues.
4. Réflexions sur la taille des grains
Pour la limitation 1, est-il possible d'utiliser le traçage au niveau des instructions de QEMU pour obtenir une visibilité sur la phase de démarrage ? De cette façon, le code du noyau peut être tracé et mappé aux options de configuration du noyau. Étant donné que la phase de démarrage est essentielle pour générer un noyau amorçable, utilisez les fonctionnalités de traçage fournies par l'hyperviseur pour obtenir une observabilité de bout en bout et générer des noyaux stables.
Pour la deuxième limitation, basée sur l'expérience de l'apprentissage profond PNL, une méthode de combinaison hors ligne et en ligne peut être utilisée. Étant donné un ensemble d'applications cibles, la configuration de l'application peut être directement générée hors ligne, puis combinée avec la configuration de base pour former une configuration de base. configuration complète du noyau. Cela entraîne un noyau tronqué. Cette composabilité permet de construire de nouveaux noyaux de manière incrémentielle en réutilisant les configurations d'application et les fichiers précédemment construits (tels que les modules du noyau). Si la configuration de l'application cible est connue, l'élagage du noyau peut être effectué en quelques dizaines de secondes.
Pour la troisième limitation, l'utilisation du traçage au niveau des instructions peut résoudre les options de configuration du noyau qui contrôlent les caractéristiques fonctionnelles internes des fonctions. La surcharge du traçage au niveau des instructions est acceptable pour l'exécution de suites de tests et de tests de performances.
En ce qui concerne la quatrième limitation, une limitation fondamentale de l'utilisation du traçage dynamique est l'imperfection des suites de tests et des benchmarks. De nombreuses suites de tests d'applications open source ont une faible couverture de code. La combinaison de différentes charges de travail pour piloter des applications peut atténuer cette limitation dans une certaine mesure.
Pour la cinquième limitation, les informations spécifiques au domaine peuvent être utilisées pour charger davantage le noyau en supprimant les modules du noyau qui s'exécutent dans le noyau de base mais qui ne sont pas nécessaires lors de l'exécution du déploiement réel. En prenant Xen et KVM comme exemples, la taille du noyau peut être encore réduite en fonction des modèles de configuration xenconfig et kvmconfig. L'élagage du noyau orienté application peut réduire davantage la taille du noyau et même personnaliser considérablement le code du noyau.
5 Étude préliminaire sur le cadre de découpage du noyau
Le principe du cadre d'adaptation du noyau n'a pas changé, il suit toujours l'utilisation du noyau par la charge de travail de l'application cible pour déterminer les options de noyau requises.
5.1 Fonctionnalités de base du framework de découpage du noyau
Le framework de découpage du noyau peut probablement avoir les caractéristiques suivantes :
Visibilité de bout en bout. Tirez parti de la visibilité de l'hyperviseur pour obtenir une observation de bout en bout, vous pouvez suivre la phase de démarrage du noyau et la charge de travail des applications, vous pouvez essayer de créer un cadre sur mesure pour le noyau Linux basé sur QEMU.
Composabilité. Une idée centrale est de permettre à la configuration du noyau d'être combinée en la divisant en plusieurs ensembles de configuration, à la fois pour démarrer le noyau sur un environnement de déploiement donné et pour les options de configuration requises par l'application cible. Les ensembles de configuration sont divisés en deux types : la configuration de base et la configuration d'application. Une configuration de base n'est pas nécessairement l'ensemble minimum de configurations requis pour démarrer sur un matériel spécifique, mais plutôt un ensemble d'options de configuration suivies pendant la phase de démarrage. La configuration de base peut être combinée avec une ou plusieurs configurations d'application pour produire la configuration finale du noyau.
Réutilisabilité. Les configurations de base et d'application peuvent être stockées dans la base de données et réutilisées tant que l'environnement de déploiement et les binaires de l'application restent inchangés. Cette réutilisabilité évite les exécutions répétées de la charge de travail de traçage et fait de la création d'ensembles de configuration une tâche unique.
Prise en charge du déploiement rapide des applications. Compte tenu d'un environnement de déploiement et d'une application cible, le cadre d'adaptation du noyau peut récupérer efficacement les configurations de base et les configurations d'application, les combiner dans la configuration de noyau requise, puis utiliser la configuration résultante pour créer le noyau obsolète.
Traçage de configuration à granularité fine, traçage basé sur des compteurs de programmes pour identifier les options de configuration basées sur des modèles de code de bas niveau.
5.2 Architecture du cadre de découpage du noyau
Le framework de découpage du noyau doit avoir à la fois des systèmes hors ligne et en ligne. L'architecture est celle illustrée dans la figure ci-dessous : 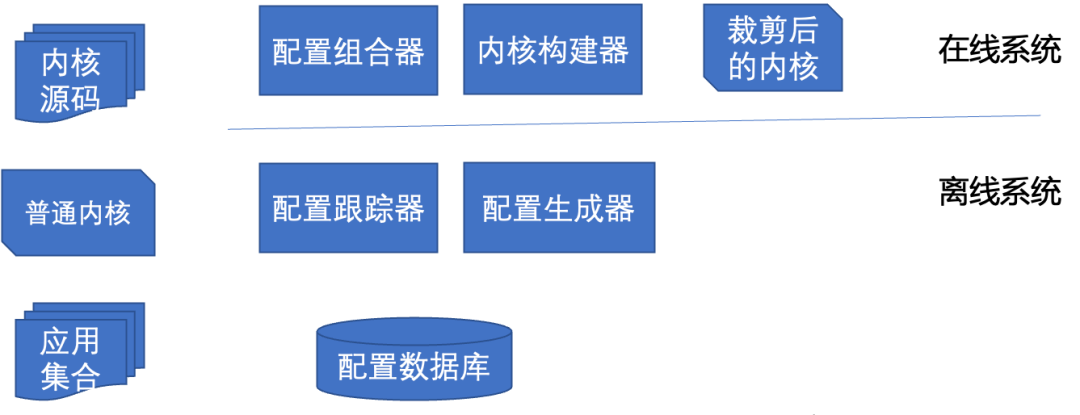
.
Grâce au système hors ligne, le suivi de configuration est utilisé pour suivre et enregistrer les options de configuration requises par l'environnement de déploiement et l'application. Le générateur de configuration traite ces options en options de configuration de base et de configuration d'application et les stocke dans la base de données de configuration.
Grâce au système en ligne, le combinateur de configuration utilise la configuration de base et la configuration de l'application pour générer la configuration du noyau cible, puis le constructeur de noyau génère le noyau Linux sur mesure
5.3 Faisabilité de la mise en œuvre du cadre de personnalisation du noyau
Suivi de la configuration
Le système de suivi de configuration du cadre de personnalisation du noyau suit les options de configuration pendant l'exécution du noyau pilotée par une application cible, en utilisant le registre PC pour capturer l'adresse de l'instruction en cours d'exécution. Afin de garantir que le PC suivi appartient à l'application cible et non à d'autres processus (par exemple, des services en arrière-plan), un script d'initialisation personnalisé peut être utilisé, qui ne démarre aucune autre application et monte uniquement le système de fichiers /tmp, / proc et /sys, activez les interfaces réseau (lo et eth0), et enfin démarrez l'application directement après le démarrage du noyau.
Dans le même temps, il peut être nécessaire de désactiver le chargement aléatoire de la configuration de l'espace d'adressage du noyau afin que les adresses puissent être correctement mappées au code source tout en restant disponibles dans le noyau découpé. Ensuite, mappez les PC aux instructions du code source. Les modules de noyau chargeables nécessitent un traitement supplémentaire. Vous pouvez utiliser /proc/module pour obtenir l'adresse de départ de chaque module de noyau chargé et mapper ces PC aux instructions du binaire du module de noyau. Une alternative consiste à utiliser localmodconfig, cependant, localmodconfig ne fournit des informations qu'au niveau de la granularité du module.
Enfin, attribuez l'instruction à la configuration. Pour le mode basé sur le préprocesseur C, le fichier source C est analysé pour extraire les directives du préprocesseur, puis vérifie si les instructions de ces directives sont exécutées. Pour le mode basé sur Makefile, détermine si les options de configuration doivent être sélectionnées selon la granularité du fichier objet. Par exemple, si l'un des fichiers correspondants (bind.o, achefiles.o ou daemon.o) est utilisé, CONFIG_CACHEFILES doit être sélectionné.
Génération de configuration
La configuration de base et la configuration d'application sont générées dans le système hors ligne. Comment juger de la fin de la phase de démarrage ? Une fonction stub vide peut être mappée à un segment d'adresse prédéfini à l'aide de mmap. Le script d'initialisation décrit ci-dessus appelle la fonction stub avant d'exécuter l'application cible, il est donc possible d'identifier la fin de la phase de démarrage en fonction de l'adresse prédéfinie dans le PC. tracer.
L'infrastructure de personnalisation du noyau obtient les options de configuration de l'application et filtre les options liées au matériel observées pendant la phase de démarrage. Ces fonctionnalités matérielles sont définies en fonction de leur emplacement dans le code source du noyau. Il ne peut être exclu que les options liées au matériel ne soient visibles que pendant l'exécution de l'application, par exemple lors du chargement de nouveaux pilotes de périphérique si nécessaire.
Configuration et assemblage
La combinaison de la configuration de base avec une ou plusieurs configurations d'application produit la configuration finale utilisée pour construire le noyau. Tout d'abord, toutes les options de configuration sont fusionnées dans une configuration initiale, puis les dépendances entre elles sont résolues à l'aide du solveur SAT. Essayez de modéliser les dépendances de configuration comme un problème de satisfiabilité booléenne, où une configuration valide est celle qui satisfait toutes les dépendances spécifiées entre les options de configuration. La modélisation de la configuration du noyau est basée sur un solveur SAT car KConfig ne garantit pas que toutes les options sélectionnées sont incluses, mais désélectionne à la place les dépendances non satisfaites.
Construction du noyau
KBuild pour Linux construit un noyau sur mesure basé sur des options de configuration assemblées. Les constructions incrémentielles utilisant une création moderne peuvent optimiser les temps de construction et peuvent également mettre en cache les résultats de construction précédents (par exemple, les fichiers objets et les modules du noyau) pour éviter les compilations et les liens redondants. Lorsqu'un changement de configuration se produit, seuls les modules qui ont modifié les options de configuration sont reconstruits, tandis que les autres fichiers peuvent être réutilisés.
6.Résumé
En raison de l'instabilité du noyau du système d'exploitation, du manque de rapidité, des problèmes d'intégrité et de la nécessité d'une intervention manuelle, la technologie d'élagage du noyau Linux n'a pas été largement utilisée. Après avoir compris les limites de la technologie existante, nous essayons de proposer un cadre d'adaptation du noyau Linux, qui pourrait être en mesure de résoudre ces problèmes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!