
Maison >Tutoriel système >Linux >Comment fonctionne l'allocation de mémoire sous Linux
Comment fonctionne l'allocation de mémoire sous Linux

- WBOYavant
- 2024-02-10 16:00:26612parcourir
Il est important de comprendre les détails de l'allocation de mémoire Linux, en particulier dans l'architecture du noyau et du système. Examinons en profondeur l'allocation de mémoire Linux et comprenons ce qui se passe dans les coulisses.
Dans un ordinateur, pour qu'un processus soit exécutable, il doit être placé en mémoire. Pour ce faire, le champ doit être alloué au processus en mémoire. L'allocation de mémoire est une question importante à laquelle il faut prêter attention, en particulier dans l'architecture du noyau et du système.
Examinons de plus près l’allocation de mémoire Linux et comprenons ce qui se passe dans les coulisses.
Comment se fait l’allocation de mémoire ?
La plupart des ingénieurs logiciels ne connaissent pas les détails de ce processus. Mais si vous êtes un candidat programmeur système, vous devriez en savoir plus. En regardant le processus d'allocation, il est nécessaire de faire un petit détail sur Linux et la bibliothèque glibc.
Lorsque les applications ont besoin de mémoire, elles doivent la demander au système d'exploitation. Cette requête du noyau nécessite naturellement un appel système. Vous ne pouvez pas allouer de mémoire vous-même en mode utilisateur.
La série de fonctions**malloc()** est responsable de l'allocation de mémoire en langage C. La question à se poser ici est de savoir si malloc(), en tant que fonction glibc, effectue un appel système direct.
Il n'y a pas d'appel système appelé malloc dans le noyau Linux. Cependant, il existe deux appels système pour les besoins en mémoire des applications, à savoir brk et mmap.
Puisque vous demanderez de la mémoire dans votre application via les fonctions de la glibc, vous souhaiterez peut-être savoir quels appels système la glibc utilise actuellement. La réponse est les deux.
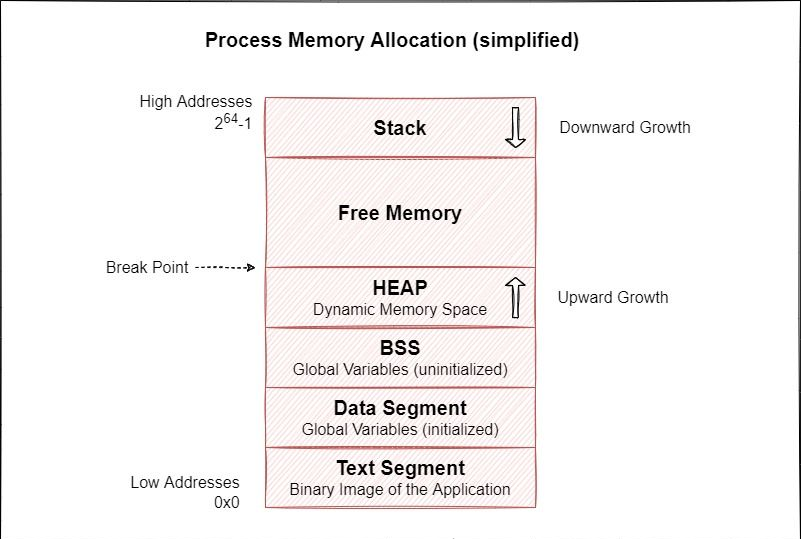
Premier appel système : brk
Chaque processus possède un champ de données continu. Grâce à l'appel système brk, la valeur d'interruption du programme qui détermine la limite du champ de données est augmentée et le processus d'allocation est effectué.
Bien que l'allocation de mémoire à l'aide de cette méthode soit très rapide, il n'est pas toujours possible de restituer l'espace inutilisé au système.
Par exemple, supposons que vous allouiez cinq champs avec chaque taille de champ de 16 Ko via la fonction malloc() pour l'appel système brk. Lorsque vous remplissez le deuxième de ces champs, la ressource associée ne peut pas être restituée (libérée) afin que le système puisse l'utiliser. Parce que si vous réduisez la valeur de l'adresse pour indiquer où commence le deuxième champ et appelez brk, vous terminerez la libération des troisième, quatrième et cinquième champs.
Pour éviter la perte de mémoire dans ce cas, l'implémentation de malloc dans la glibc surveille l'emplacement alloué dans le champ de données de processus, puis le renvoie au système comme spécifié par la fonction free() afin que le système puisse utiliser l'espace libre pour plus de mémoire. distribuer.
En d'autres termes, après avoir alloué 5 zones de 16 Ko, si vous utilisez la fonction free() pour renvoyer la deuxième zone, puis demandez une autre zone de 16 Ko après un certain temps, au lieu d'étendre la zone de données via l'appel système brk, la précédente l'adresse est de retour.
Cependant, si la région nouvellement demandée est supérieure à 16 Ko, la région de données sera agrandie en allouant une nouvelle région via l'appel système brk car la région 2 ne peut pas être utilisée. Bien que la zone numéro deux ne soit pas utilisée, l'application ne peut pas l'utiliser en raison de sa taille différente. En raison de scénarios comme celui-ci, il existe ce qu'on appelle la fragmentation interne, dans laquelle vous pouvez rarement utiliser pleinement toutes les parties de la mémoire.
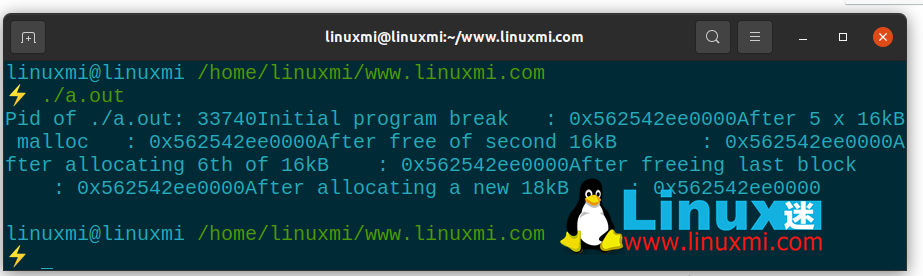
Pour une meilleure compréhension, essayez de compiler et d'exécuter l'exemple d'application suivant :
#include
#include
#include
int main(int argc, char* argv[])
{
char *ptr[7];
int n;
printf("Pid of %s: %d", argv[0], getpid());
printf("Initial program break : %p", sbrk(0));
for(n=0; nprintf("After 5 x 16kB malloc : %p", sbrk(0));
free(ptr[1]);
printf("After free of second 16kB : %p", sbrk(0));
ptr[5] = malloc(16 * 1024);
printf("After allocating 6th of 16kB : %p", sbrk(0));
free(ptr[5]);
printf("After freeing last block : %p", sbrk(0));
ptr[6] = malloc(18 * 1024);
printf("After allocating a new 18kB : %p", sbrk(0));
getchar();
return 0;
}
Lorsque vous exécutez l'application, vous obtiendrez un résultat similaire à celui-ci :
Pid of ./a.out: 31990 Initial program break : 0x55ebcadf4000 After 5 x 16kB malloc : 0x55ebcadf4000 After free of second 16kB : 0x55ebcadf4000 After allocating 6th of 16kB : 0x55ebcadf4000 After freeing last block : 0x55ebcadf4000 After allocating a new 18kB : 0x55ebcadf4000
Le résultat de brk avec strace est le suivant :
brk(NULL) = 0x5608595b6000 brk(0x5608595d7000) = 0x5608595d7000
Comme vous pouvez le voir, 0x21000 a été ajouté à l'adresse de fin du champ de données. Vous pouvez comprendre cela à partir de la valeur 0x5608595d7000. Ainsi, environ 0x21000 ou 132 Ko de mémoire sont alloués.
Il y a deux points à considérer ici. La première consiste à allouer plus que ce qui est spécifié dans l’exemple de code. L'autre est la ligne de code qui provoque l'appel brk qui fournit l'allocation.
Randomisation de la disposition de l'espace d'adresse : ASLR
Lorsque vous exécutez les exemples d'applications ci-dessus l'un après l'autre, vous verrez à chaque fois des valeurs d'adresse différentes. Changer aléatoirement l'espace d'adressage de cette manière complique considérablement le travail des attaques de sécurité et augmente la sécurité du logiciel.
但是,在 32 位架构中,通常使用 8 位来随机化地址空间。增加位数将不合适,因为剩余位上的可寻址区域将非常低。此外,仅使用 8 位组合不会使攻击者的事情变得足够困难。
另一方面,在 64 位体系结构中,由于可以为 ASLR 操作分配的位太多,因此提供了更大的随机性,并且提高了安全程度。
Linux 内核还支持基于 Android 的设备,并且 ASLR 功能在 Android 4.0.3 及更高版本上完全激活。即使仅出于这个原因,也可以说 64 位智能手机比 32 位版本具有显着的安全优势。
通过使用以下命令暂时禁用 ASLR 功能,之前的测试应用程序每次运行时都会返回相同的地址值:
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
要将其恢复到以前的状态,在同一个文件中写入 2 而不是 0 就足够了。
第二个系统调用:mmap
mmap 是 Linux 上用于内存分配的第二个系统调用。通过 mmap 调用,内存中任何区域的空闲空间都映射到调用进程的地址空间。
在以这种方式完成的内存分配中,当您想使用前面 brk 示例中的 free() 函数返回第二个 16KB 分区时,没有机制可以阻止此操作。从进程的地址空间中删除相关的内存段。它被标记为不再使用并返回系统。
因为与使用 brk 相比,使用 mmap 的内存分配非常慢,所以需要分配 brk。
使用 mmap,内存的任何空闲区域都映射到进程的地址空间,因此在该进程完成之前,已分配空间的内容被重置。如果没有以这种方式进行重置,则属于先前使用相关内存区域的进程的数据也可以被下一个不相关的进程访问。这样就不可能谈论系统中的安全性。
Linux 中内存分配的重要性
内存分配非常重要,尤其是在优化和安全问题上。如上面的示例所示,不完全理解此问题可能意味着破坏系统的安全性。
甚至许多编程语言中存在的类似于 push 和 pop 的概念也是基于内存分配操作的。能够很好地使用和掌握系统内存对于嵌入式系统编程和开发安全和优化的系统架构都是至关重要的。
如果您还想涉足 Linux 内核开发,请考虑首先掌握 C 编程语言。
综上所述,Linux 中的内存分配是一个需要注意和理解的重要问题,特别是对于程序员、内核开发人员和系统架构师而言。熟练掌握内存分配可以提高软件性能和安全性,并在嵌入式系统编程和系统架构方面提供更好的支持。同时,C 编程语言的掌握也是涉足 Linux 内核开发的关键。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!