
Maison >Tutoriel système >Linux >Mécanisme d'équilibrage de charge CPU du noyau Linux : principes, processus et optimisations
Mécanisme d'équilibrage de charge CPU du noyau Linux : principes, processus et optimisations

- 王林avant
- 2024-02-09 13:50:111362parcourir
L'équilibrage de charge du processeur fait référence à l'allocation de processus ou de tâches en cours d'exécution à différents processeurs dans un système multicœur ou multiprocesseur afin que la charge de chaque processeur soit équilibrée autant que possible, améliorant ainsi les performances et l'efficacité du système. L'équilibrage de charge du processeur est une fonction importante du noyau Linux. Elle permet au système Linux de tirer pleinement parti du multicœur ou du multiprocesseur pour s'adapter aux différents scénarios et besoins d'application. Mais comprenez-vous vraiment le mécanisme d’équilibrage de la charge CPU du noyau Linux ? Connaissez-vous son principe de fonctionnement, son processus et sa méthode d’optimisation ? Cet article vous présentera en détail les connaissances pertinentes du mécanisme d'équilibrage de charge CPU du noyau Linux, vous permettant de mieux utiliser et comprendre cette puissante fonction du noyau sous Linux.
Cela est toujours dû à un problème de planification de processus magique. Veuillez vous référer à l'analyse du mécanisme de planification de groupe de processus Linux. On constate que pendant le processus de redémarrage, de nombreuses piles d'appels du noyau sont bloquées sur le système. double_rq_lock et double_rq_lock est déclenché par load_balance. , je soupçonnais qu'il y avait un problème avec la planification inter-cœur à ce moment-là, et un verrouillage multicœur s'est produit dans un certain scénario responsable. Plus tard, j'ai examiné l'implémentation du code sous la charge du processeur. équilibrage et rédigé un résumé.
Version du code du noyau : kernel-3.0.13-0.27.
La fonction de code du noyau démarre à partir de la fonction Load_balance. À partir de la fonction Load_balance, vous pouvez trouver la fonction de planification ici en regardant les fonctions qui y font référence. Ensuite, commencez à regarder vers le bas. Il y a la phrase suivante dans __schedule.
if (unlikely(!rq->nr_running)) idle_balance(cpu, rq);
Ce qui précède montre quand le noyau tentera d'effectuer un équilibrage de charge du processeur : c'est-à-dire lorsque la file d'attente d'exécution actuelle du processeur est NULL.
Il existe deux méthodes d'équilibrage de charge du processeur : tirer et pousser, c'est-à-dire que le processeur inactif extrait un processus d'autres files d'attente de processeur occupées vers la file d'attente de processeur actuelle ou que la file d'attente de processeur occupée pousse un processus vers la file d'attente de processeur inactive ; Ce que fait ralenti_balance, c'est tirer. Le push spécifique sera mentionné ci-dessous.
Dans ralenti_balance, il y a une valve de procédure pour contrôler si le processeur actuel est tiré :
if (this_rq->avg_idle return;
Le fichier de contrôle proc correspondant à sysctl_sched_migration_cost est /proc/sys/kernel/sched_migration_cost. Le commutateur signifie que si la file d'attente du processeur est inactive pendant plus de 500us (valeur par défaut de sysctl_sched_migration_cost), l'extraction sera effectuée, sinon elle reviendra.
for_each_domain(this_cpu, sd) traverse le domaine de planification où se trouve le processeur actuel. Il peut être intuitivement compris comme un groupe de processeurs, similaire à l'équilibre inter-cœurs qui fait référence à l'équilibre au sein du groupe. Il existe une contradiction dans l'équilibrage de charge : la fréquence d'équilibrage de charge n'est pas cohérente avec le taux de réussite du cache du processeur. Le domaine de planification du processeur divise chaque processeur en groupes avec des niveaux différents. L'équilibre obtenu au niveau bas ne sera jamais mis à niveau vers le niveau bas. niveau élevé pour le traitement, ce qui évite d'affecter le taux de réussite du cache.
L'image est la suivante :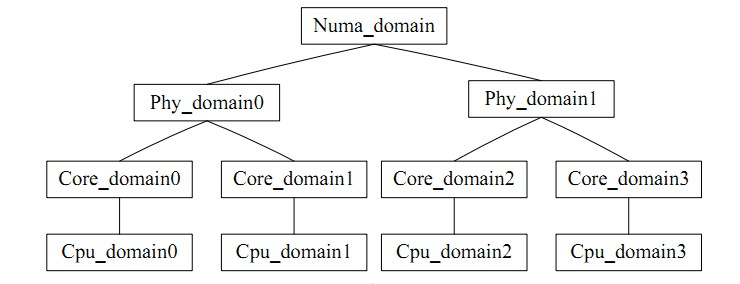
Enfin, entrons dans le vif du sujet via load_balance.
Tout d'abord, obtenez le groupe de planification le plus occupé dans le domaine de planification actuel via find_busiest_group. Tout d'abord, update_sd_lb_stats met à jour le statut de sd, c'est-à-dire qu'il parcourt le sd correspondant et remplit les données de structure dans sds, comme suit :
struct sd_lb_stats {
struct sched_group *busiest; /* Busiest group in this sd */
struct sched_group *this; /* Local group in this sd */
unsigned long total_load; /* Total load of all groups in sd */
unsigned long total_pwr; /* Total power of all groups in sd */
unsigned long avg_load; /* Average load across all groups in sd */
/** Statistics of this group */
unsigned long this_load; //当前调度组的负载
unsigned long this_load_per_task; //当前调度组的平均负载
unsigned long this_nr_running; //当前调度组内运行队列中进程的总数
unsigned long this_has_capacity;
unsigned int this_idle_cpus;
/* Statistics of the busiest group */
unsigned int busiest_idle_cpus;
unsigned long max_load; //最忙的组的负载量
unsigned long busiest_load_per_task; //最忙的组中平均每个任务的负载量
unsigned long busiest_nr_running; //最忙的组中所有运行队列中进程的个数
unsigned long busiest_group_capacity;
unsigned long busiest_has_capacity;
unsigned int busiest_group_weight;
do
{
local_group = cpumask_test_cpu(this_cpu, sched_group_cpus(sg));
if (local_group) {
//如果是当前CPU上的group,则进行赋值
sds->this_load = sgs.avg_load;
sds->this = sg;
sds->this_nr_running = sgs.sum_nr_running;
sds->this_load_per_task = sgs.sum_weighted_load;
sds->this_has_capacity = sgs.group_has_capacity;
sds->this_idle_cpus = sgs.idle_cpus;
} else if (update_sd_pick_busiest(sd, sds, sg, &sgs, this_cpu)) {
//在update_sd_pick_busiest判断当前sgs的是否超过了之前的最大值,如果是
//则将sgs值赋给sds
sds->max_load = sgs.avg_load;
sds->busiest = sg;
sds->busiest_nr_running = sgs.sum_nr_running;
sds->busiest_idle_cpus = sgs.idle_cpus;
sds->busiest_group_capacity = sgs.group_capacity;
sds->busiest_load_per_task = sgs.sum_weighted_load;
sds->busiest_has_capacity = sgs.group_has_capacity;
sds->busiest_group_weight = sgs.group_weight;
sds->group_imb = sgs.group_imb;
}
sg = sg->next;
} while (sg != sd->groups);
Le critère de référence pour décider de sélectionner le groupe le plus occupé dans le domaine de planification est la somme des charges sur tous les processeurs du groupe. Le critère de référence pour trouver la file d'attente d'exécution occupée dans le groupe est la longueur de la file d'attente d'exécution du processeur, c'est-à-dire. c'est-à-dire la charge, et plus la valeur de charge est grande, plus elle est occupée. Pendant le processus d'équilibrage, en comparant l'état de charge de la file d'attente actuelle avec le plus occupé enregistré précédemment, ces variables sont mises à jour en temps opportun afin que le plus occupé pointe toujours vers le groupe le plus occupé du domaine pour une recherche facile.
Calcul de la charge moyenne du domaine de planification
sds.avg_load = (SCHED_POWER_SCALE * sds.total_load) / sds.total_pwr; if (sds.this_load >= sds.avg_load) goto out_balanced;
Dans le processus de comparaison de la taille de charge, lorsqu'il s'avère que le groupe le plus occupé du processeur en cours d'exécution est vide, ou que la file d'attente du processeur en cours d'exécution est la plus occupée, ou que la charge de la file d'attente du processeur actuelle n'est pas inférieure à la moyenne. dans ce groupe Lorsque la charge est sous charge, ou lorsque le montant déséquilibré n'est pas important, une valeur NULL sera renvoyée, c'est-à-dire que l'équilibrage entre les groupes n'est pas requis lorsque la charge du groupe le plus occupé est inférieure à la charge moyenne de ; Dans le domaine de la planification, seule une petite plage de charge doit être effectuée. Équilibre ; lorsque le nombre de tâches à transférer est inférieur à la charge moyenne de chaque processus, le groupe de planification le plus occupé est obtenu.
Recherchez ensuite la file d'attente de planification la plus chargée dans find_busiest_queue, parcourez toutes les files d'attente CPU du groupe et recherchez la file d'attente la plus chargée en comparant tour à tour les charges de chaque file d'attente.
or_each_cpu(i, sched_group_cpus(group)) {
/*rq->cpu_power表示所在处理器的计算能力,在函式sched_init初始化时,会把这值设定为SCHED_LOAD_SCALE (=Nice 0的Load Weight=1024).并可透过函式update_cpu_power (in kernel/sched_fair.c)更新这个值.*/
unsigned long power = power_of(i);
unsigned long capacity = DIV_ROUND_CLOSEST(power,SCHED_POWER_SCALE);
unsigned long wl;
if (!cpumask_test_cpu(i, cpus))
continue;
rq = cpu_rq(i);
/*获取队列负载cpu_rq(cpu)->load.weight;*/
wl = weighted_cpuload(i);
/*
* When comparing with imbalance, use weighted_cpuload()
* which is not scaled with the cpu power.
*/
if (capacity && rq->nr_running == 1 && wl > imbalance)
continue;
/*
* For the load comparisons with the other cpu's, consider
* the weighted_cpuload() scaled with the cpu power, so that
* the load can be moved away from the cpu that is potentially
* running at a lower capacity.
*/
wl = (wl * SCHED_POWER_SCALE) / power;
if (wl > max_load) {
max_load = wl;
busiest = rq;
}
Grâce au calcul ci-dessus, nous obtenons la file d'attente la plus chargée.
Lorsque le nombre le plus occupé->nr_running est supérieur à 1, l'opération d'extraction est effectuée avant l'extraction, les move_tasks sont verrouillées par double_rq_lock.
double_rq_lock(this_rq, busiest); ld_moved = move_tasks(this_rq, this_cpu, busiest, imbalance, sd, idle, &all_pinned); double_rq_unlock(this_rq, busiest);
La tâche d'extraction de processus move_tasks est autorisée à échouer, c'est-à-dire move_tasks->balance_tasks. Ici, il y a le commutateur sysctl_sched_nr_migrate pour contrôler le nombre de migrations de processus.
Vous trouverez ci-dessous la fonction can_migrate_task pour vérifier si le processus sélectionné peut être migré. Il existe trois raisons d'échec de la migration : 1. Le processus migré est en cours d'exécution. 2. Le processus est lié au noyau et ne peut pas être migré vers la cible. CPU ; 3. Le processus Le cache est encore chaud, et cela permet également de garantir le taux de réussite du cache.
/*关于cache cold的情况下,如果迁移失败的个数太多,仍然进行迁移
* Aggressive migration if:
* 1) task is cache cold, or
* 2) too many balance attempts have failed.
*/
tsk_cache_hot = task_hot(p, rq->clock_task, sd);
if (!tsk_cache_hot ||
sd->nr_balance_failed > sd->cache_nice_tries) {
#ifdef CONFIG_SCHEDSTATS
if (tsk_cache_hot) {
schedstat_inc(sd, lb_hot_gained[idle]);
schedstat_inc(p, se.statistics.nr_forced_migrations);
}
#endif
return 1;
}
Déterminez si le cache du processus est valide et déterminez les conditions. Le temps d'exécution du processus est supérieur au commutateur de contrôle proc sysctl_sched_migration_cost, correspondant au répertoire /proc/sys/kernel/sched_migration_cost_ns
static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的”too many balance attempts have failed”,然后busiest->active_balance = 1设置,active_balance = 1。
if (active_balance) //如果pull失败了,开始触发push操作 stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work);
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
通过本文,你应该对 Linux 内核的 CPU 负载均衡机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了 CPU 负载均衡机制的作用和影响,以及如何在 Linux 下正确地使用和配置它。我们建议你在使用多核或多处理器的 Linux 系统时,使用 CPU 负载均衡机制来提高系统的性能和效率。同时,我们也提醒你在使用 CPU 负载均衡机制时要注意一些潜在的问题和挑战,如负载均衡策略、能耗、调度延迟等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受 CPU 负载均衡机制的优势和便利。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!