
Maison >Périphériques technologiques >IA >OccNeRF : aucune supervision des données lidar n'est requise
OccNeRF : aucune supervision des données lidar n'est requise

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-07 21:57:13532parcourir
Écrit ci-dessus et résumé personnel de l'auteur
Ces dernières années, la tâche de prédiction d'occupation en 3D dans le domaine de la conduite autonome a reçu une large attention de la part du monde universitaire et de l'industrie en raison de ses avantages uniques. Cette tâche fournit des informations détaillées pour la planification de la conduite autonome et la navigation en reconstruisant la structure 3D de l'environnement environnant. Cependant, la plupart des méthodes courantes actuelles s'appuient sur des étiquettes générées sur la base de nuages de points LiDAR pour superviser la formation du réseau. Dans une récente étude OccNeRF, les auteurs ont proposé une méthode de prédiction d’occupation multi-caméras auto-supervisée appelée Champs d’occupation paramétrés. Cette méthode résout le problème de l’absence de limites dans les scènes extérieures et réorganise la stratégie d’échantillonnage. Ensuite, grâce à la technologie de rendu de volume (Volume Rendering), le champ occupé est converti en une carte de profondeur multi-caméras et supervisé par une cohérence photométrique multi-images (Photometric Error). De plus, le procédé utilise également un modèle de segmentation sémantique à vocabulaire ouvert pré-entraîné pour générer des étiquettes sémantiques 2D afin de doter le domaine professionnel d'informations sémantiques. Ce modèle de segmentation sémantique à lexique ouvert est capable de segmenter différents objets dans une scène et d'attribuer des étiquettes sémantiques à chaque objet. En combinant ces étiquettes sémantiques avec des champs d'occupation, les modèles sont capables de mieux comprendre l'environnement et de faire des prédictions plus précises. En résumé, la méthode OccNeRF permet d'obtenir une prédiction d'occupation de haute précision dans des scénarios de conduite autonome grâce à l'utilisation combinée de champs d'occupation paramétrés, de rendu de volume et de cohérence photométrique multi-images, ainsi qu'avec un modèle de segmentation sémantique à vocabulaire ouvert. Cette méthode fournit au système de conduite autonome davantage d’informations environnementales et devrait améliorer la sécurité et la fiabilité de la conduite autonome.

- Lien papier : https://arxiv.org/pdf/2312.09243.pdf
- Lien code : https://github.com/LinShan-Bin/OccNeRF
Contexte du problème OccNeRF
Ces dernières années, avec le développement rapide de la technologie de l’intelligence artificielle, de grands progrès ont été réalisés dans le domaine de la conduite autonome. La perception 3D constitue la base de la conduite autonome et fournit les informations nécessaires à la planification et à la prise de décision ultérieures. Dans les méthodes traditionnelles, le lidar peut capturer directement des données 3D précises, mais le coût élevé du capteur et la rareté des points de numérisation limitent son application pratique. En revanche, les méthodes de détection 3D basées sur l’image sont peu coûteuses et efficaces et font l’objet d’une attention croissante. La détection d'objets 3D multi-caméras est la norme des tâches de compréhension de scènes 3D depuis un certain temps, mais elle ne peut pas faire face aux catégories illimitées dans le monde réel et souffre de la distribution à longue traîne des données . La prédiction d'occupation 3D peut bien compenser ces défauts en reconstruisant directement la géométrie de la scène environnante grâce à une entrée multi-vues. La plupart des méthodes existantes se concentrent sur la conception de modèles et l'optimisation des performances, en s'appuyant sur des étiquettes générées par des nuages de points LiDAR pour superviser la formation du réseau, ce qui n'est pas disponible dans les systèmes basés sur l'image. En d'autres termes, nous devons toujours utiliser des véhicules de collecte de données coûteux pour collecter des données de formation et gaspiller une grande quantité de données réelles sans annotation assistée par nuage de points LiDAR, ce qui limite dans une certaine mesure le développement de la prévision d'occupation 3D. Par conséquent, l’exploration de la prévision d’occupation 3D auto-supervisée est une direction très précieuse.
Explication détaillée de l'algorithme OccNeRF
La figure suivante montre le processus de base de la méthode OccNeRF. Le modèle prend des images multi-caméras en entrée, utilise d'abord le squelette 2D pour extraire les caractéristiques
de N images, puis obtient directement les caractéristiques 3D par simple projection et interpolation bilinéaire (sous espace paramétré ), et enfin via la 3D. Le réseau CNN optimise les fonctionnalités 3D et génère des prédictions. Pour entraîner le modèle, la méthode OccNeRF génère une carte de profondeur de l'image actuelle via le rendu du volume et introduit les images précédentes et suivantes pour calculer la perte photométrique. Pour introduire plus d'informations temporelles, OccNeRF utilise un champ d'occupation pour restituer des cartes de profondeur multi-images et calculer la fonction de perte. Dans le même temps, OccNeRF restitue également simultanément des cartes sémantiques 2D et est supervisé par le Open Lexicon Semantic Segmentation Model.
Champs d'occupation paramétrés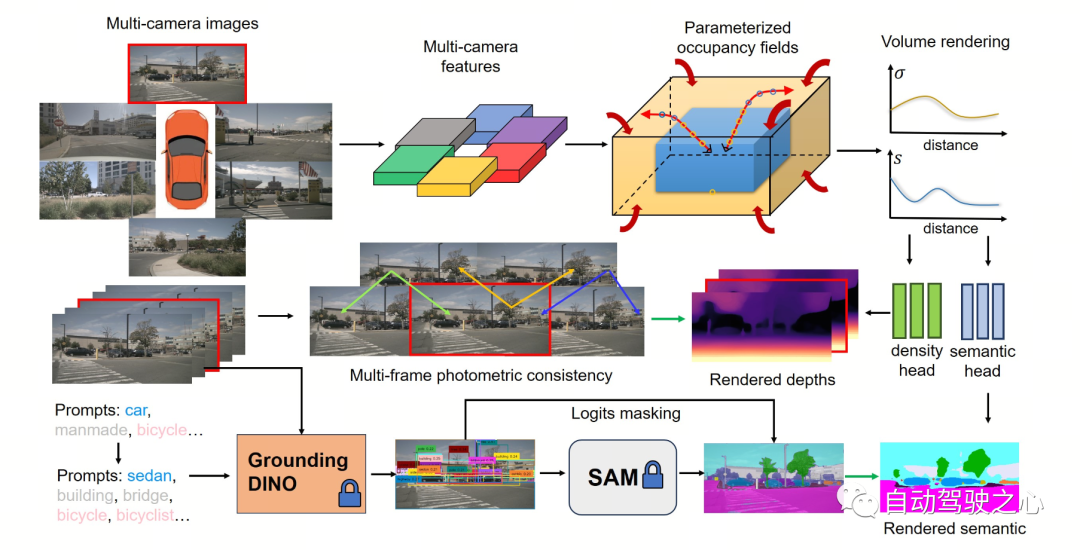 Des champs d'occupation paramétrés sont proposés pour résoudre le problème de
Des champs d'occupation paramétrés sont proposés pour résoudre le problème de
entre la caméra et la grille occupée. Théoriquement, les caméras peuvent capturer des objets à des distances infinies, alors que les modèles de prévision d'occupation précédents ne prennent en compte que les espaces plus proches (par exemple, dans un rayon de 40 m). Dans les méthodes supervisées, le modèle peut apprendre à ignorer les objets distants en fonction des signaux de supervision ; dans les méthodes non supervisées, si seul l'espace proche est toujours pris en compte, la présence d'un grand nombre d'objets hors de portée dans l'image aura un effet négatif. impact sur le processus d’optimisation. Sur cette base, OccNeRF adopte des champs d'occupation paramétrés pour modéliser une gamme illimitée de scènes extérieures.
L'espace de paramétrage dans OccNeRF est divisé en interne et externe. L'espace intérieur est une cartographie linéaire des coordonnées d'origine, conservant une haute résolution tandis que l'espace extérieur représente une plage infinie. Plus précisément, OccNeRF apporte les modifications suivantes aux coordonnées du point médian dans l'espace 3D :
où est la coordonnée , est un paramètre réglable, indiquant la valeur limite correspondante de l'espace interne, est également réglable. Le paramètre ajusté représente la proportion de l'espace interne occupé. Lors de la génération de champs d'occupation paramétrés, OccNeRF échantillonne d'abord dans l'espace paramétré, obtient les coordonnées d'origine par transformation inverse, puis projette les coordonnées d'origine sur le plan image et obtient enfin le champ d'occupation par échantillonnage et convolution tridimensionnelle.
Estimation de la profondeur multi-trames
Afin d'entraîner le réseau d'occupation, OccNeRF choisit d'utiliser le rendu volumique pour convertir l'occupation en carte de profondeur et la superviser via une fonction de perte photométrique. La stratégie d'échantillonnage est importante lors du rendu des cartes de profondeur. Dans l'espace paramétré, si vous échantillonnez directement uniformément en fonction de la profondeur ou de la parallaxe, les points d'échantillonnage seront inégalement répartis dans l'espace interne ou externe, ce qui affectera le processus d'optimisation. Par conséquent, OccNeRF propose d'échantillonner directement et uniformément dans l'espace paramétré en partant du principe que le centre de la caméra est proche de l'origine. De plus, OccNeRF restitue et supervise des cartes de profondeur multi-images pendant la formation.
La figure ci-dessous démontre visuellement les avantages de l'utilisation de la représentation spatiale paramétrique. (La troisième ligne utilise l'espace paramétré, pas la deuxième ligne.)

Génération d'étiquettes sémantiques
OccNeRF utilise GroundedSAM pré-entraîné (Grounding DINO + SAM) pour générer des étiquettes sémantiques 2D. Afin de générer des étiquettes de haute qualité, OccNeRF adopte deux stratégies. L'une est l'optimisation des mots rapides, qui remplace les catégories vagues dans nuScenes par des descriptions précises. Trois stratégies sont utilisées dans OccNeRF pour optimiser les mots d'invite : remplacement de mots ambigus (la voiture est remplacée par une berline), mot à mot multi-mots (l'ouvrage artificiel est remplacé par un bâtiment, un panneau d'affichage et un pont) et introduction d'informations supplémentaires (le vélo est remplacé à vélo, cycliste). La seconde consiste à déterminer la catégorie en fonction de la confiance de la trame de détection dans Grounding DINO au lieu de la confiance pixel par pixel donnée par SAM. L'effet d'étiquette sémantique généré par OccNeRF est le suivant :
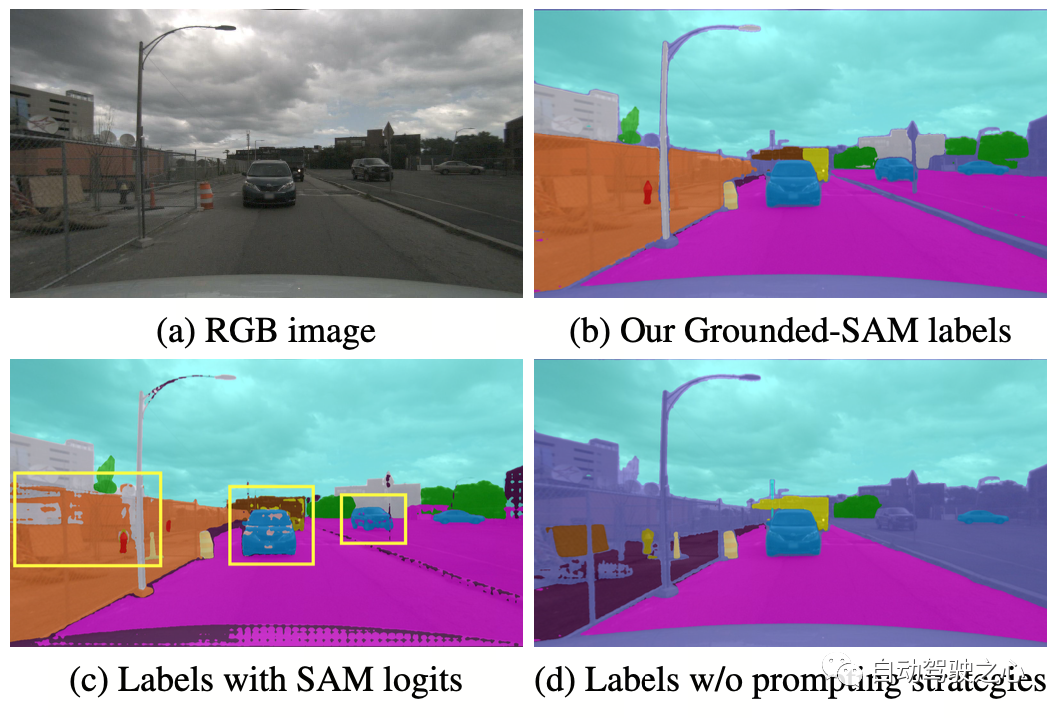
OccNeRF a mené des expériences sur nuScenes et a principalement réalisé des tâches d'estimation de profondeur auto-supervisées multi-vues et de prédiction d'occupation 3D.
Estimation de profondeur auto-supervisée multi-vues
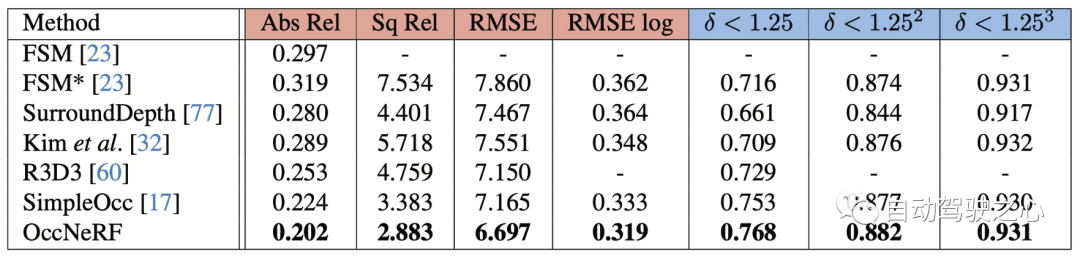
Les performances d'estimation de profondeur auto-supervisée multi-vues d'OccNeRF sur nuScenes sont présentées dans le tableau ci-dessous. On peut voir qu'OccNeRF basé sur la modélisation 3D surpasse considérablement la méthode 2D et surpasse également SimpleOcc, en grande partie en raison de la plage spatiale illimitée qu'OccNeRF modélise pour les scènes extérieures.
 Certaines visualisations dans l'article sont les suivantes :
Certaines visualisations dans l'article sont les suivantes :
 Prédiction d'occupation 3D
Prédiction d'occupation 3D
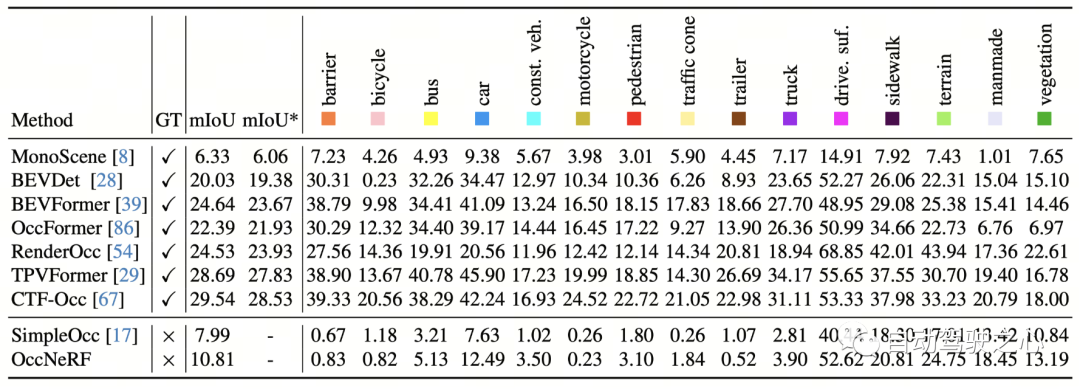
Les performances de prédiction d'occupation 3D d'OccNeRF sur nuScenes sont présentées dans le tableau ci-dessous. Étant donné qu’OccNeRF n’utilise pas du tout de données annotées, ses performances sont toujours en retard par rapport aux méthodes supervisées. Cependant, certaines catégories, telles que les surfaces carrossables et artificielles, ont atteint des performances comparables à celles des méthodes supervisées.
 Certaines des visualisations de l'article sont les suivantes :
Certaines des visualisations de l'article sont les suivantes :

À l'heure où de nombreux constructeurs automobiles tentent de supprimer les capteurs LiDAR, comment faire bon usage de milliers d'images non étiquetées les données constituent un sujet important. Et OccNeRF nous a apporté une tentative précieuse.
 Lien original : https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
Lien original : https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Code CSS pur pour réaliser la 3D (cube, album photo dynamique en trois dimensions, ciel étoilé plat)
- Implémentation de polices 3D dans PS (super simple)
- De la science-fiction à la réalité, quels sont les problèmes encore rencontrés dans le développement de la conduite autonome ?
- Discutez de l'état actuel et des tendances de développement de la technologie de prédiction de trajectoire de conduite autonome
- Le projet de la « décennie dorée » de la conduite autonome se déroule, avec diverses régions accélérant leur aménagement pour saisir l'opportunité.