
Maison >Périphériques technologiques >IA >Le modèle mathématique open source 7B bat des milliards de GPT-4, produit par une équipe chinoise
Le modèle mathématique open source 7B bat des milliards de GPT-4, produit par une équipe chinoise

- 王林avant
- 2024-02-07 17:03:28871parcourir
Modèle open source 7B, la puissance mathématique dépasse le GPT-4 à l'échelle de 100 milliards !
On peut dire que ses performances ont dépassé les limites du modèle open source. Même les chercheurs d'Alibaba Tongyi ont déploré l'échec de la loi de mise à l'échelle.

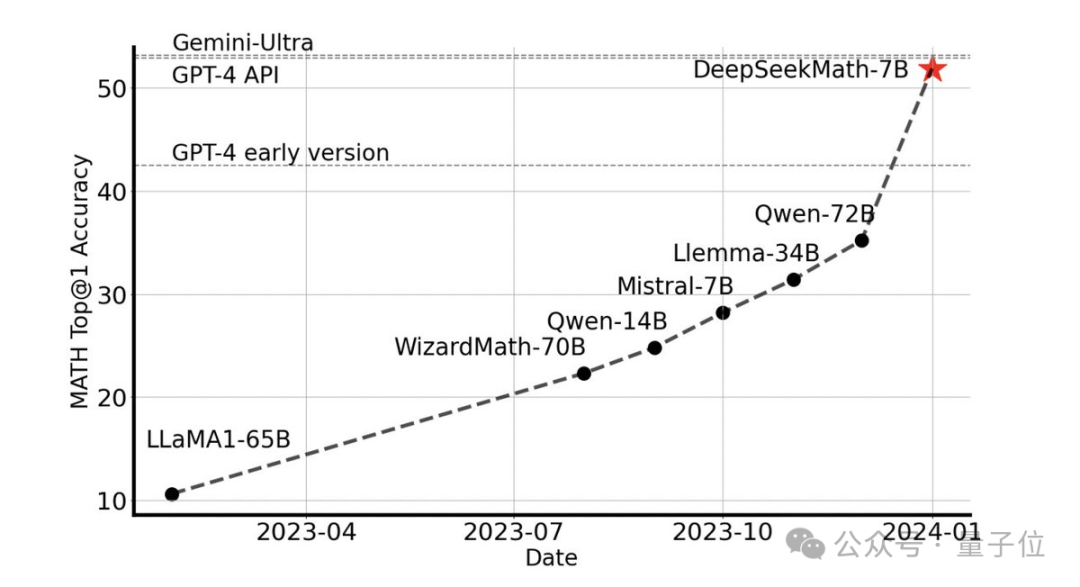
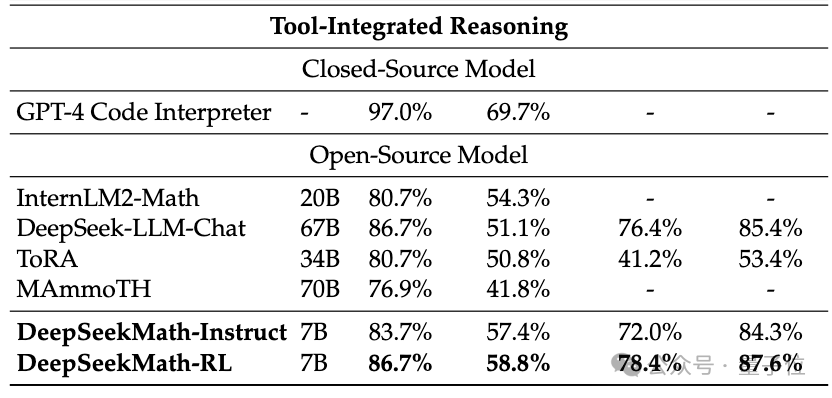
Sans aucun outil externe, il peut atteindre une précision de 51,7 % sur l'ensemble de données MATH de niveau compétition.
Parmi les modèles open source, il est le premier à atteindre la moitié de la précision sur cet ensemble de données, surpassant même les premières versions API de GPT-4.
Cette performance a choqué toute la communauté open source Emad Mostaque, le fondateur de Stability AI, a salué l'équipe R&D comme étant impressionnante et au potentiel sous-estimé.
Il s'agit du dernier grand modèle mathématique open source 7B de l'équipe Deep Search, DeepSeekMath.
Le modèle 7B bat les autres
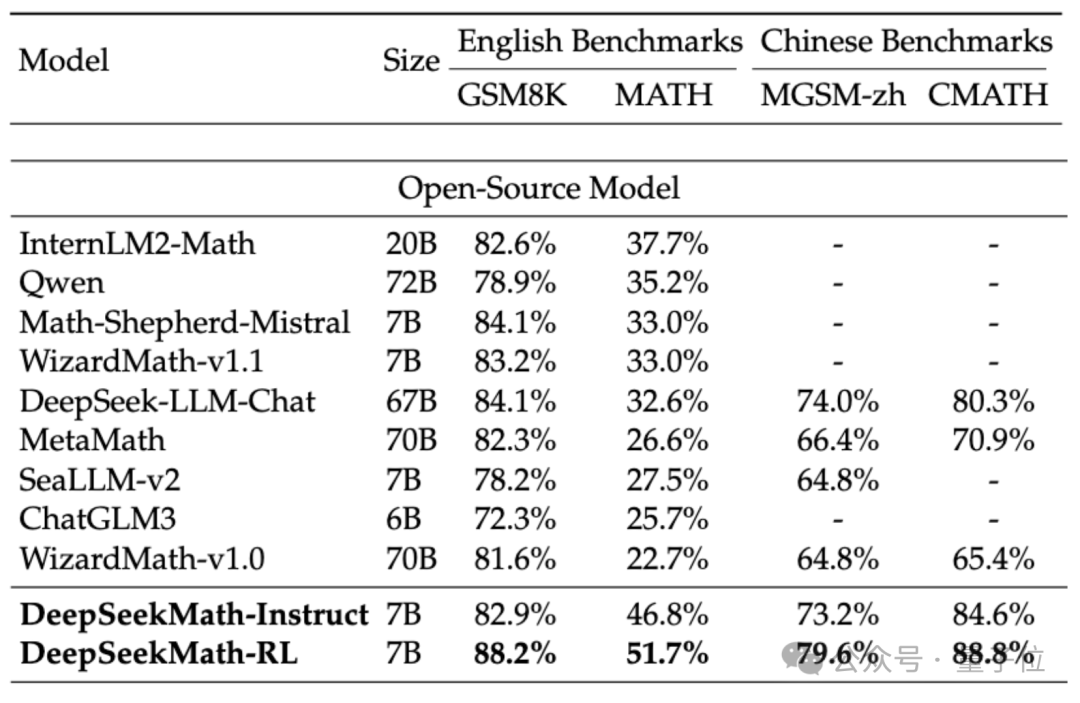
Afin d'évaluer la capacité mathématique de DeepSeekMath, l'équipe de recherche a utilisé des ensembles de données bilingues chinois (MGSM-zh, CMATH) anglais (GSM8K, MATH) pour les tests.
Sans utiliser d'outils auxiliaires et en s'appuyant uniquement sur les invites de la chaîne de pensée(CoT), DeepSeekMath a surpassé les autres modèles open source, y compris le grand modèle mathématique 70B MetaMATH.
Par rapport au grand modèle universel 67B auto-lancé, les résultats de DeepSeekMath ont également été considérablement améliorés.
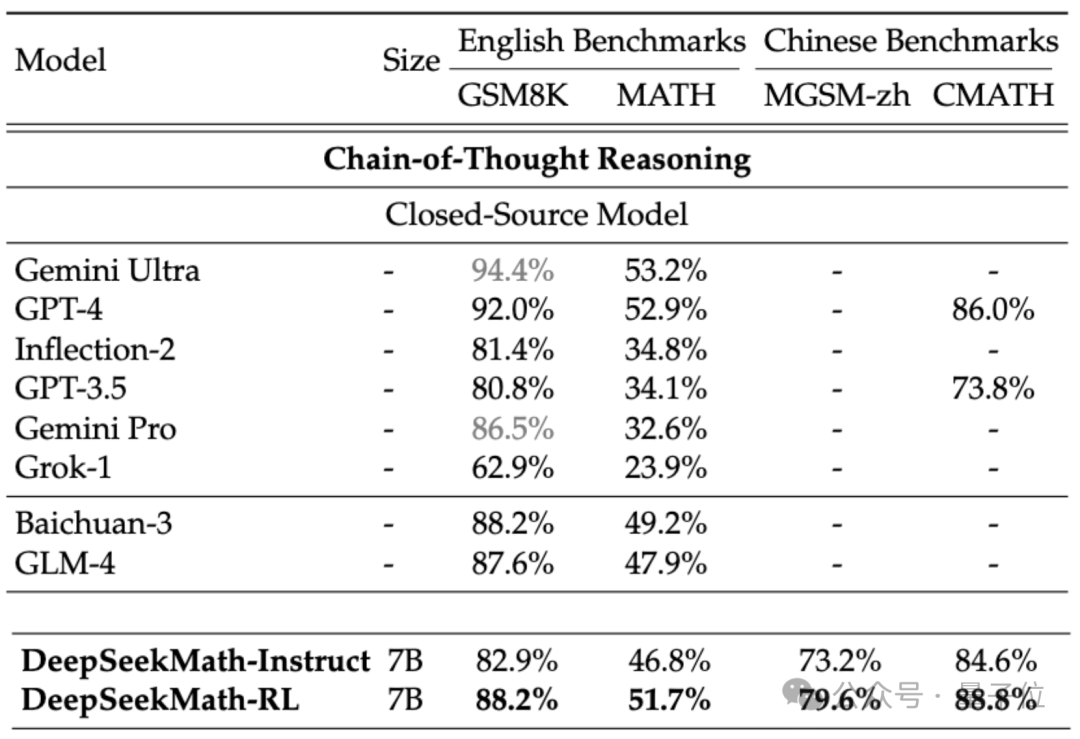
Si l'on considère le modèle source fermée, DeepSeekMath surpasse également Gemini Pro et GPT-3.5 sur plusieurs ensembles de données, dépasse GPT-4 sur CMATH chinois, et ses performances sur MATH en sont également proches.
Mais il convient de noter que GPT-4 est un monstre avec des centaines de milliards de paramètres selon les spécifications divulguées, alors que DeepSeekMath n'a que 7B de paramètres.
Si l'outil (Python) est autorisé à être utilisé à des fins d'assistance, les performances de DeepSeekMath sur l'ensemble de données de difficulté compétition (MATH) peuvent être améliorées de 7 points de pourcentage supplémentaires.
Alors, quelles technologies sont appliquées derrière les excellentes performances de DeepSeekMath ?
Construit sur la base d'un modèle de code
Afin d'obtenir de meilleures capacités mathématiques que celles du modèle général, l'équipe de recherche a utilisé le modèle de code DeepSeek-Coder-v1.5 pour l'initialiser.
Parce que l'équipe a découvert que la formation au code peut améliorer les capacités mathématiques du modèle par rapport à la formation générale sur les données, que ce soit dans une formation en deux étapes ou en une seule étape.
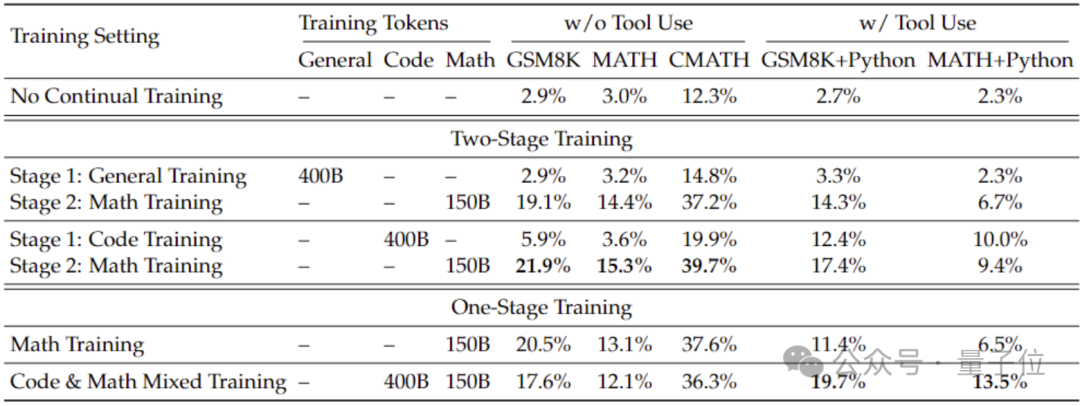
Sur la base de Coder, l'équipe de recherche a continué à former 500 milliards de jetons. La répartition des données est la suivante :
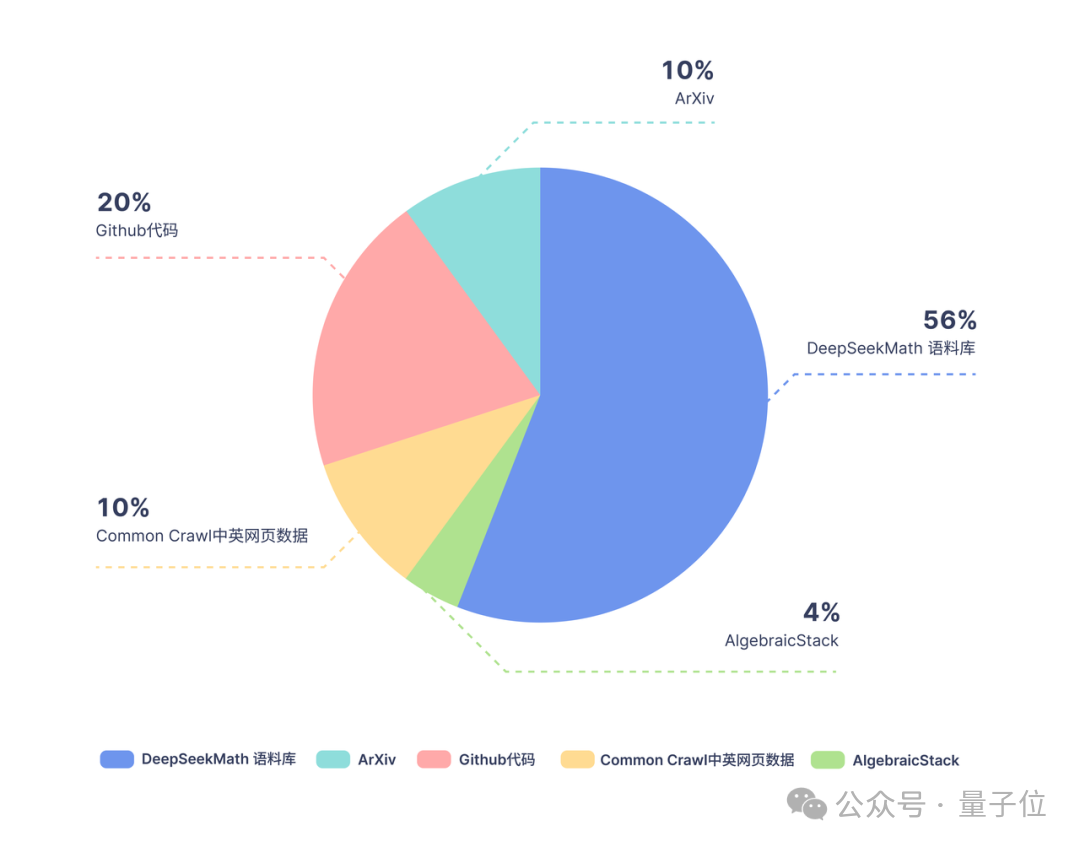
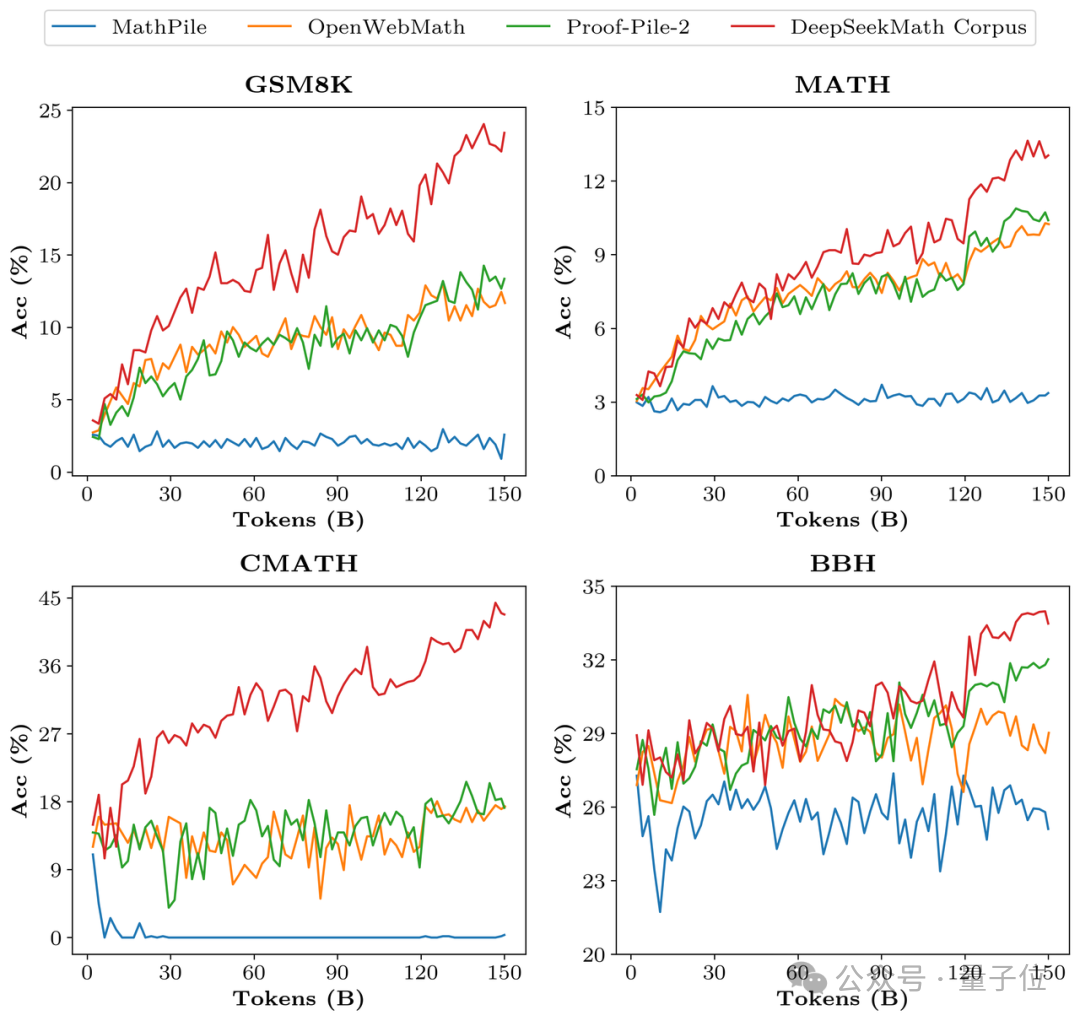
En termes de données de formation, DeepSeekMath utilise 120 milliards de données de pages Web mathématiques de haute qualité extraites de Common Crawl. Le corpus DeepSeekMath a été obtenu et le volume total de données est 9 fois supérieur à celui de l'ensemble de données open source OpenWebMath.
Le processus de collecte de données est effectué de manière itérative. Après quatre itérations, l'équipe de recherche a collecté plus de 35 millions de pages Web mathématiques et le nombre de jetons a atteint 120 milliards.
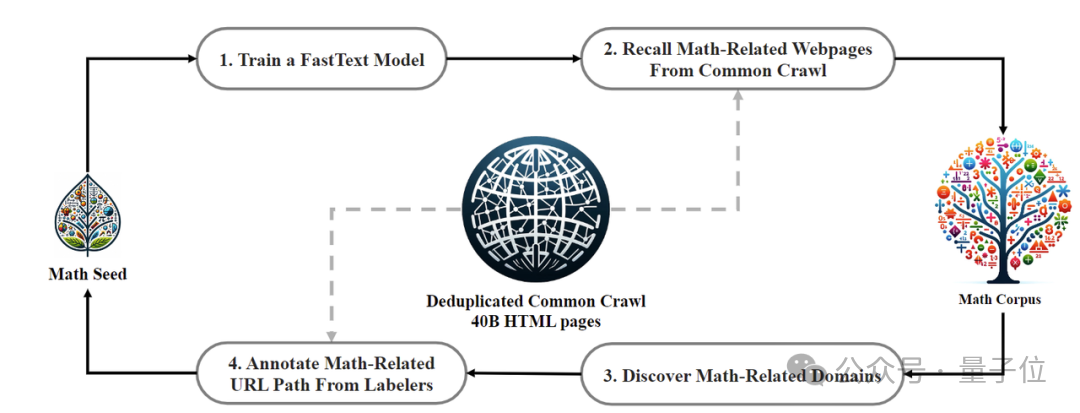
Afin de s'assurer que les données d'entraînement ne contiennent pas le contenu de l'ensemble de test (car le contenu en GSM8K et MATH existe en grande quantité sur Internet), l'équipe de recherche a également effectué un filtrage spécial.
Afin de vérifier la qualité des données de DeepSeekMath Corpus, l'équipe de recherche a formé 150 milliards de jetons à l'aide de plusieurs ensembles de données tels que MathPile. En conséquence, Corpus était nettement en avance dans plusieurs benchmarks mathématiques.
Au cours de la phase d'alignement, l'équipe de recherche a d'abord construit un échantillon de 776 000 données mathématiques chinoises et anglaises à réglage fin supervisé guidé (SFT) , qui comprend trois formats : CoT, PoT et inférence intégrée aux outils.
Au stade de l'apprentissage par renforcement (RL) , l'équipe de recherche a utilisé un algorithme efficace appelé « Group Relative Policy Optimization (GRPO) ».
GRPO est une variante de Proximal Policy Optimization(PPO) , dans laquelle la fonction de valeur traditionnelle est remplacée par une estimation de récompense relative basée sur le groupe, ce qui peut réduire les besoins en calcul et en mémoire pendant l'entraînement.
Dans le même temps, GRPO est formé selon un processus itératif et le modèle de récompense est continuellement mis à jour en fonction des résultats du modèle de politique pour garantir une amélioration continue de la politique.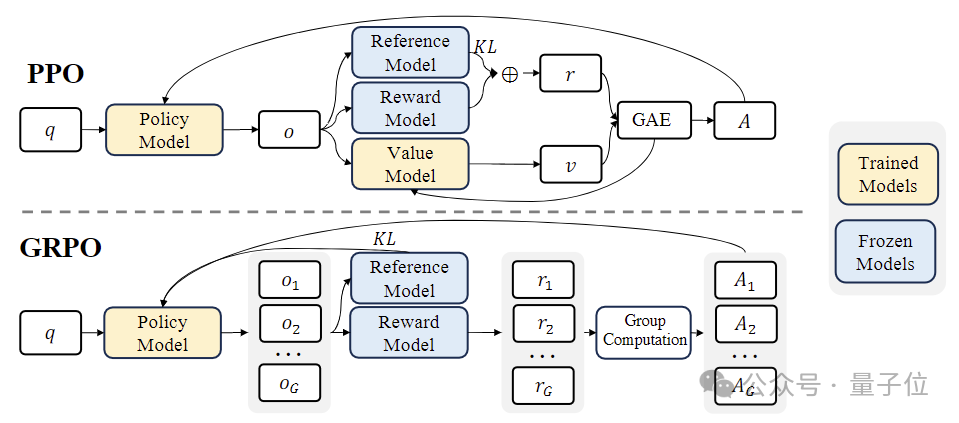

Adresse papier : https://arxiv.org/abs/2402.03300
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!