
Maison >Périphériques technologiques >IA >Faisant un pas de plus vers une autonomie complète, l'Université Tsinghua et la nouvelle stratégie d'auto-évolution multi-tâches de HKU permettent aux agents d'apprendre à « apprendre de l'expérience »
Faisant un pas de plus vers une autonomie complète, l'Université Tsinghua et la nouvelle stratégie d'auto-évolution multi-tâches de HKU permettent aux agents d'apprendre à « apprendre de l'expérience »

- PHPzavant
- 2024-02-07 09:31:141511parcourir
"Apprendre de l'histoire peut nous aider à comprendre les hauts et les bas." L'histoire du progrès humain est un processus d'auto-évolution qui s'appuie constamment sur l'expérience passée et repousse les limites des capacités. Nous apprenons des échecs passés et corrigeons les erreurs ; nous apprenons des expériences réussies pour améliorer l’efficience et l’efficacité. Cette auto-évolution traverse tous les aspects de la vie : en résumant nos expériences pour résoudre des problèmes de travail, en utilisant des modèles pour prédire la météo, nous continuons à apprendre et à évoluer à partir du passé.
Réussir à extraire les connaissances de l'expérience passée et à les appliquer aux défis futurs est une étape importante sur la route de l'évolution humaine. Alors, à l’ère de l’intelligence artificielle, les agents IA peuvent-ils faire la même chose ?
Ces dernières années, des modèles de langage tels que GPT et LLaMA ont démontré des capacités étonnantes dans la résolution de tâches complexes. Cependant, même s’ils peuvent utiliser des outils pour résoudre des tâches spécifiques, ils manquent intrinsèquement de connaissances et d’apprentissages tirés des succès et des échecs passés. C'est comme un robot qui ne peut effectuer qu'une tâche spécifique. Bien qu'il accomplisse bien la tâche en cours, il ne peut pas faire appel à son expérience passée pour l'aider face à de nouveaux défis. Nous devons donc développer davantage ces modèles afin qu’ils puissent accumuler des connaissances et des expériences et les appliquer dans de nouvelles situations. En introduisant des mécanismes de mémoire et d'apprentissage, nous pouvons rendre ces modèles plus complets en matière d'intelligence, capables de réagir avec flexibilité à différentes tâches et situations, et de nous inspirer des expériences passées. Cela rendra les modèles linguistiques plus puissants et plus fiables et contribuera à faire progresser le développement de l’intelligence artificielle.
En réponse à ce problème, une équipe conjointe de l'Université Tsinghua, de l'Université de Hong Kong, de l'Université Renmin et de Wall-Facing Intelligence a récemment proposé une nouvelle stratégie d'auto-évolution des agents intelligents : Investigate-Consolidate-Exploit, ICE). Il vise à améliorer l’adaptabilité et la flexibilité des agents d’IA grâce à l’auto-évolution entre les tâches. Cela peut non seulement améliorer l'efficience et l'efficacité de l'agent dans la gestion de nouvelles tâches, mais également réduire considérablement la demande pour les capacités du modèle de base d'agent.
L'émergence de cette stratégie a en effet ouvert un nouveau chapitre dans l'auto-évolution des agents intelligents, et marque également une nouvelle étape vers l'obtention d'agents pleinement autonomes.

- Titre de l'article : Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution
- Lien de l'article : https://arxiv.org/abs/2401.13996
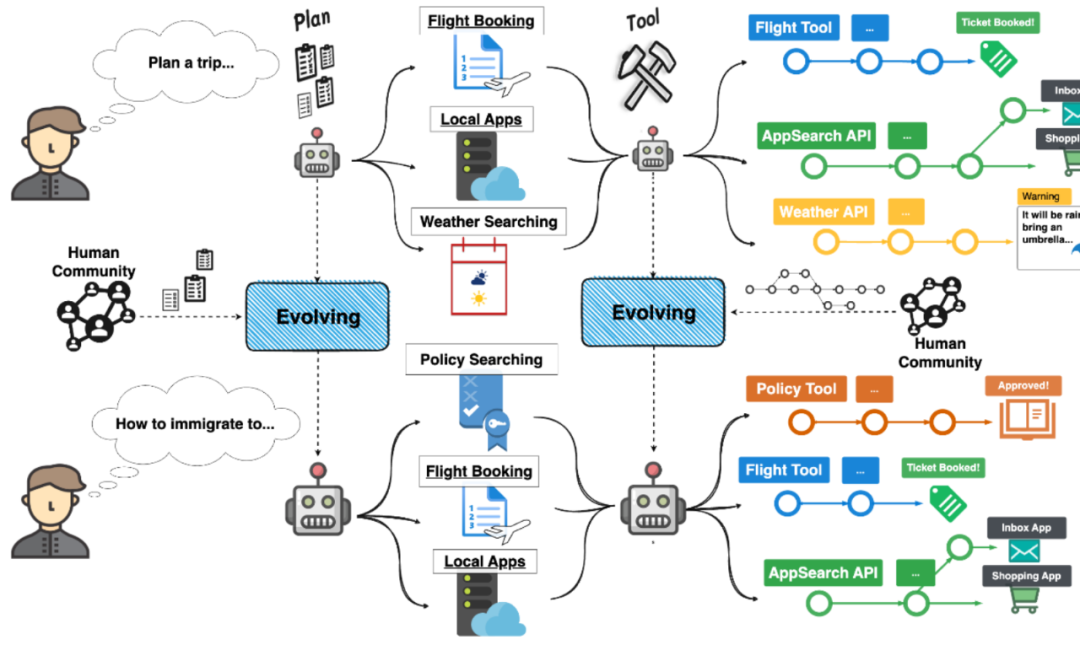 Aperçu du transfert d'expérience entre les tâches des agents pour parvenir à l'auto-évolution
Aperçu du transfert d'expérience entre les tâches des agents pour parvenir à l'auto-évolution
Deux aspects de l'auto-évolution des agents : la planification et l'exécution
Les agents complexes actuels peuvent être principalement divisés en tâches. et les aspects d’exécution des tâches. En termes de planification des tâches, l'agent décompose les besoins des utilisateurs et développe des stratégies cibles détaillées grâce à un raisonnement logique. En termes d'exécution des tâches, l'agent utilise divers outils pour interagir avec l'environnement afin d'atteindre les sous-objectifs correspondants.
Afin de mieux promouvoir la réutilisation de l'expérience passée, l'auteur découple d'abord la stratégie évolutive en deux aspects dans cet article. Plus précisément, l'auteur prend comme exemples la structure arborescente de planification des tâches et l'exécution de l'outil de chaîne ReACT dans l'architecture d'agent XAgent pour présenter en détail la méthode de mise en œuvre de la stratégie ICE.
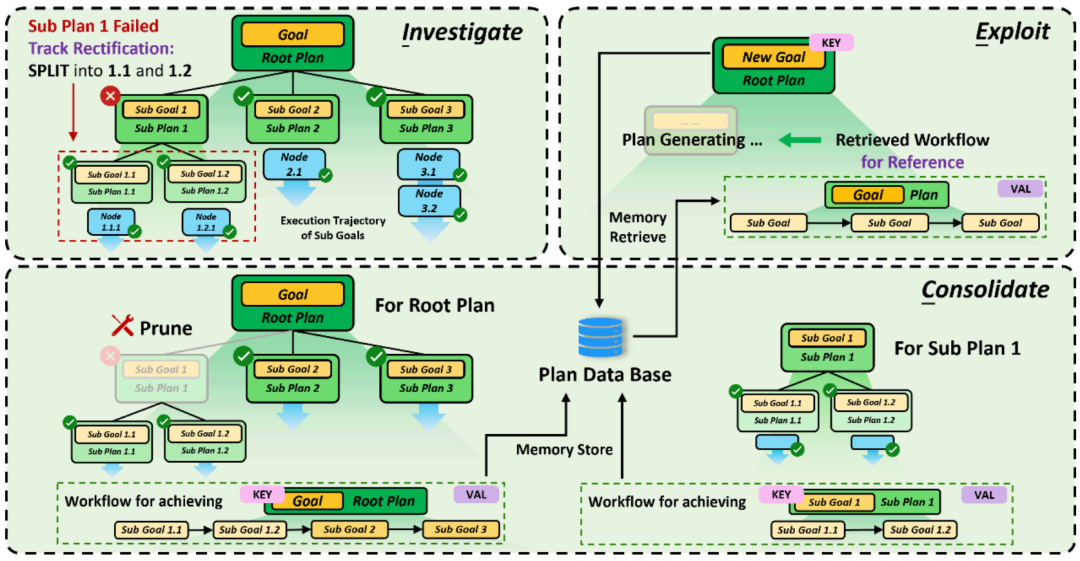 Stratégie d'auto-évolution ICE pour la planification de mission d'agent
Stratégie d'auto-évolution ICE pour la planification de mission d'agent
Pour la planification de mission, l'auto-évolution est divisée en trois étapes suivantes selon ICE :
- Dans la phase d'exploration, l'agent enregistre toute la structure arborescente de planification des tâches et détecte dynamiquement l'état d'exécution de chaque sous-objectif en même temps
- Dans la phase de solidification, l'agent élimine d'abord tous les échecs ; nœuds cibles, puis pour chaque objectif atteint avec succès, l'agent organisera tous les nœuds feuilles du sous-arbre avec l'objectif afin de former une chaîne de planification (Workflow) Dans la phase d'utilisation, ces chaînes de planification serviront de base de référence pour décomposer et affiner les nouveaux objectifs de mission afin de tirer parti des expériences réussies passées.
Stratégie d'auto-évolution ICE pour l'exécution des tâches des agents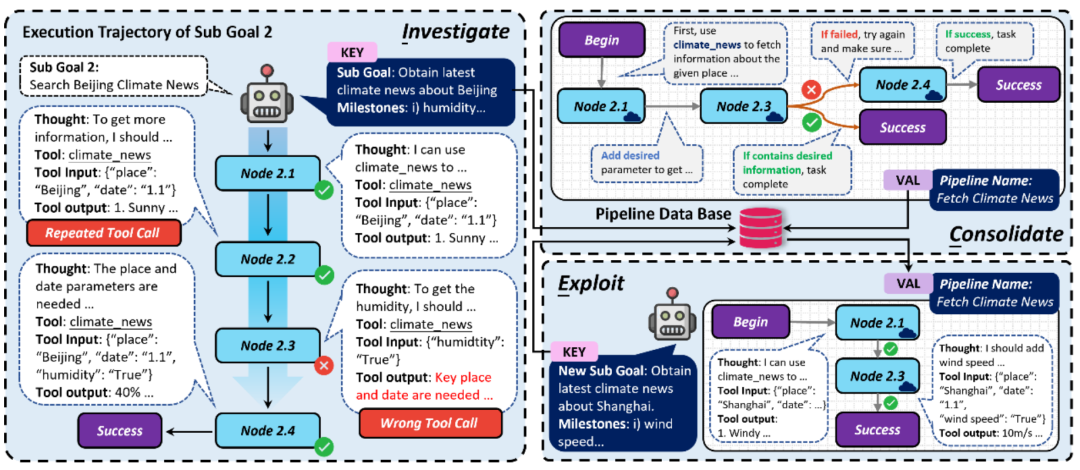
- Dans la phase d'exploration, le l'agent enregistre dynamiquement chaque chaîne d'appels d'outils d'exécution cible, ainsi qu'une détection et une classification simples des problèmes possibles survenant dans les appels d'outils
- Dans la phase de solidification, la chaîne d'appels d'outils sera transformée en un
- Pipeline de type automate ; structure , la séquence d'appel de l'outil et la relation de transfert entre les appels seront corrigées, et les appels répétés seront supprimés, une logique de branche sera ajoutée, etc. pour rendre le processus d'exécution automatisé de l'automate plus robuste Dans ; la phase d'utilisation, pour des objectifs similaires, l'agent automatisera directement l'exécution du pipeline, améliorant ainsi l'efficacité de l'exécution des tâches.
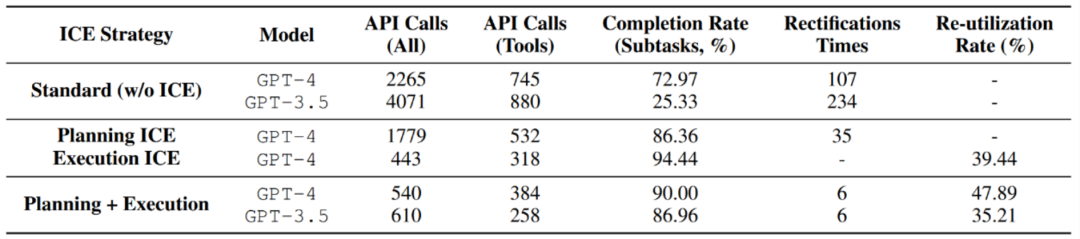
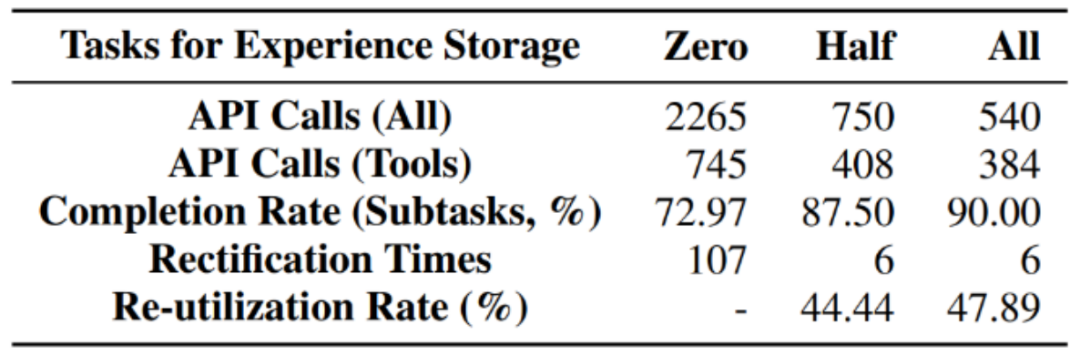
L'auteur a testé la stratégie d'auto-évolution ICE proposée dans le nombre d'appels de modèle, améliorant ainsi l'efficacité et réduisant les frais généraux.
L'expérience stockée a un taux de réutilisation élevé dans le cadre de la stratégie ICE, ce qui prouve l'efficacité d'ICE.
- La stratégie ICE peut améliorer le taux d'achèvement des sous-tâches tout en réduisant le nombre de réparations planifiées.
- Grâce à l'expérience passée, les exigences en matière de capacités de modèle pour l'exécution des tâches ont été considérablement réduites. Plus précisément, en utilisant GPT-3.5 combiné à une expérience antérieure en matière de planification et d'exécution de tâches, l'effet peut être directement comparable à GPT-4.
- Après avoir exploré et solidifié le stockage d'expérience, l'exécution de la tâche d'ensemble de test sous différentes stratégies ICE d'agent
Conclusion
 Imaginez que dans un monde où chacun peut déployer des agents, le nombre d'expériences réussies sera celui de l'individu Les tâches de l'agent continuent de s'accumuler, les utilisateurs peuvent également partager ces expériences dans le cloud et dans la communauté. Ces expériences inciteront l’agent intelligent à acquérir continuellement des capacités, à évoluer et à atteindre progressivement une complète autonomie. Nous nous rapprochons d’une telle époque.
Imaginez que dans un monde où chacun peut déployer des agents, le nombre d'expériences réussies sera celui de l'individu Les tâches de l'agent continuent de s'accumuler, les utilisateurs peuvent également partager ces expériences dans le cloud et dans la communauté. Ces expériences inciteront l’agent intelligent à acquérir continuellement des capacités, à évoluer et à atteindre progressivement une complète autonomie. Nous nous rapprochons d’une telle époque.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les trois modèles de données de la base de données ?
- Quelles sont les couches du modèle de référence TCP/IP ?
- Comment supprimer des modèles redondants dans ZBrush
- Quelles sont les cinq méthodes d'analyse des données spss ?
- À quelle couche du modèle osi la fonction de sélection de chemin est-elle terminée ?