
Maison >Tutoriel système >Linux >Explorer le changement de contexte sur les processeurs Linux
Explorer le changement de contexte sur les processeurs Linux

- WBOYavant
- 2024-02-05 13:06:10678parcourir
Comme nous le savons tous, Linux est un système d'exploitation qui prend en charge le multitâche. Le nombre de tâches qu'il peut exécuter en même temps dépasse de loin le nombre de processeurs. Bien entendu, ces tâches ne s'exécutent pas réellement en même temps (pour un seul processeur), mais parce que le système alloue le processeur à ces tâches à tour de rôle pendant une courte période de temps, créant l'illusion de plusieurs tâches exécutées en même temps. .
Contexte CPU
Avant l'exécution de chaque tâche, le processeur doit savoir où charger et démarrer cette tâche. Cela signifie que le système doit configurer à l'avance les registres et le compteur de programme du processeur.
Les registres CPU sont des mémoires petites mais très rapides intégrées au CPU. Le compteur de programme est utilisé pour stocker l'emplacement de l'instruction en cours d'exécution par le CPU ou l'emplacement de la prochaine instruction à exécuter.
Ces deux éléments constituent l'environnement nécessaire au processeur avant qu'il puisse effectuer une tâche, c'est pourquoi on l'appelle "contexte CPU". Veuillez vous référer à l'image ci-dessous :
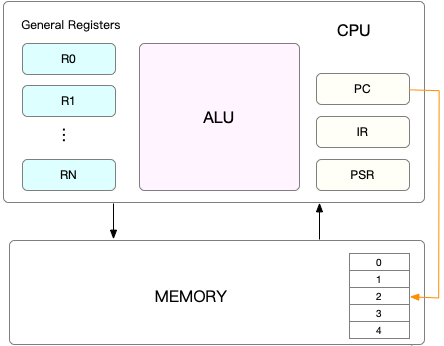
Maintenant que vous savez ce qu'est le contexte CPU, je pense qu'il vous sera facile de comprendre le Changement de contexte CPU. Le « changement de contexte CPU » fait référence à la sauvegarde du contexte CPU (registres CPU et compteur de programme) de la tâche précédente, puis au chargement du contexte de la nouvelle tâche dans ces registres et compteur de programme, et enfin au passage au compteur de programme.
Ces contextes enregistrés sont stockés dans le noyau du système et rechargés lorsque l'exécution de la tâche est reprogrammée. Cela garantit que l'état d'origine de la tâche n'est pas affecté et que la tâche semble s'exécuter en continu.
Types de changement de contexte CPU
Vous pourriez dire que la commutation de contexte du processeur n'est rien d'autre que la mise à jour des registres du processeur et des valeurs des compteurs de programme, et ces registres sont conçus pour exécuter des tâches rapidement, alors pourquoi cela affecte-t-il les performances du processeur ?
Avant de répondre à cette question, avez-vous déjà réfléchi à ce que sont ces « tâches » ? On pourrait dire qu'une tâche est un processus ou un thread. Oui, les processus et les threads sont les tâches les plus courantes, mais il existe d’autres types de tâches en plus.
N'oubliez pasL'interruption matérielle est également une tâche courante. Le signal de déclenchement matériel entraînera l'appel du gestionnaire d'interruption.
Par conséquent, il existe au moins trois types différents de commutateurs de contexte CPU :
- Changement de contexte de processus
- Changement de contexte du fil de discussion
- Interruption du changement de contexte
Jetons un coup d’œil un par un.
Changement de contexte de processus
Linux divise l'espace d'exécution du processus en espace noyau et espace utilisateur en fonction du niveau de privilège, qui correspond au niveau de privilège CPU de Ring 0 和 Ring 3 dans la figure ci-dessous.
-
Espace noyau(
Ring 0) dispose des autorisations les plus élevées et peut accéder directement à toutes les ressources -
L'espace utilisateur (
Ring 3) ne peut accéder qu'à des ressources restreintes et ne peut pas accéder directement aux périphériques matériels tels que la mémoire. Il doit être piégédans le noyau via des appels systèmeafin d'accéder à ces ressources privilégiées.
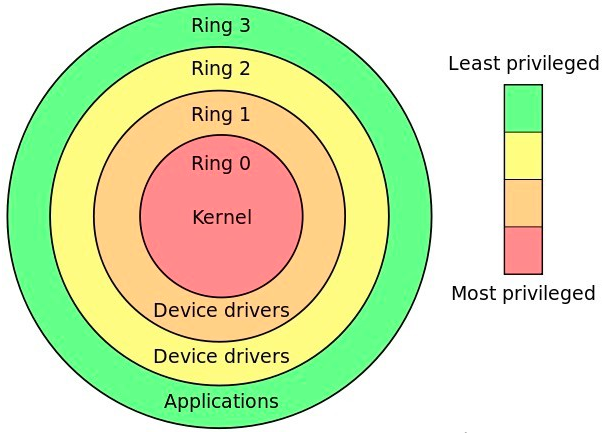
En regardant les choses sous un autre angle, un processus peut s'exécuter à la fois dans l'espace utilisateur et dans l'espace noyau. Lorsqu'un processus s'exécute dans espace utilisateur, on l'appelle état utilisateur du processus. Lorsqu'il tombe dans espace noyau, on l'appelle état noyau du processus.
La conversion du mode utilisateur au mode noyau doit être effectuée via appel système. Par exemple, lorsque nous visualisons le contenu d'un fichier, nous avons besoin de l'appel système suivant :
-
open(): Ouvrir le dossier -
read(): Lire le contenu du fichier -
write(): Écrivez le contenu du fichier dans le fichier de sortie (y compris la sortie standard) -
close(): Fermer le dossier
Alors, le changement de contexte du processeur se produira-t-il pendant l'appel système ci-dessus ? bien sûr.
Cela nécessite d'abord d'enregistrer l'emplacement de l'instruction du mode utilisateur d'origine dans le registre du processeur. Ensuite, afin d'exécuter du code en mode noyau, les registres du processeur doivent être mis à jour vers le nouvel emplacement des instructions en mode noyau. Enfin, passez à l'état du noyau pour exécuter la tâche du noyau.
Ensuite, une fois l'appel système terminé, les registres du processeur doivent restaurerl'état utilisateur enregistré d'origine, puis passer à l'espace utilisateur pour continuer à exécuter le processus.
Ainsi, lors d'un appel système, il y a en fait deux commutateurs de contexte CPU.
Mais il convient de souligner que le processus d'appel système n'impliquera pas de changement de processus, ni de changement de ressources système telles que la mémoire virtuelle. Ceci est différent de ce que nous appelons habituellement le « changement de contexte de processus ». Le changement de contexte de processus fait référence au passage d'un processus à un autre, alors que le même processus est toujours en cours d'exécution pendant l'appel système
Le processus d'appel système est souvent appelé commutateur de mode privilège, plutôt que commutateur de contexte. Mais en fait, pendant le processus d'appel système, le changement de contexte CPU est également inévitable.
Changement de contexte de processus vs appel système
Alors, quelle est la différence entre le changement de contexte de processus et les appels système ? Tout d'abord, les processus sont gérés par le noyau et la commutation de processus ne peut se produire qu'en mode noyau. Par conséquent, le contexte du processus inclut non seulement les ressources de l'espace utilisateur telles que la mémoire virtuelle, la pile et les variables globales, mais inclut également les états de l'espace du noyau tels que la pile du noyau et les registres.
Donc, le changement de contexte de processus comporte une étape de plus que l'appel système :
Avant de sauvegarder l'état du noyau et les registres du processeur du processus en cours, vous devez sauvegarder la mémoire virtuelle, la pile, etc. du processus et charger l'état du noyau du processus suivant ;
Selon le rapport de test de Tsuna, chaque changement de contexte nécessite des dizaines de nanosecondes à des microsecondes de temps CPU. Ce temps est considérable, en particulier dans le cas d'un grand nombre de changements de contexte de processus, ce qui peut facilement amener le processeur à consacrer beaucoup de temps à économiser et à restaurer des ressources telles que les registres, les piles de noyau et la mémoire virtuelle. C’est exactement ce dont nous avons parlé dans le dernier article, un facteur important qui fait augmenter la charge moyenne.
Alors, quand le processus sera-t-il planifié/commuté pour s'exécuter sur le CPU ? En fait, il existe de nombreux scénarios, laissez-moi vous les résumer ci-dessous :
- Lorsque la tranche de temps CPU d'un processus est épuisée, elle est suspendue par le système et basculée vers d'autres processus en attente de l'exécution du CPU. Lorsque les ressources système sont insuffisantes (par exemple, mémoire insuffisante), le processus ne peut pas s'exécuter tant que les ressources ne sont pas suffisantes. À ce moment-là, le processus sera également suspendu
- et le système planifiera l'exécution d'autres processus. Lorsqu'un processus se suspend automatiquement
- via la fonction
sleep, il sera naturellement reprogrammé. Lorsqu'un processus avec une priorité plus élevée est en cours d'exécution, afin d'assurer le fonctionnement du processus à haute priorité, le processus en cours sera suspendu par le processus à haute priorité . - Lorsqu'une interruption matérielle se produit, le processus sur le processeur sera interruption-suspendu et exécutera à la place la routine de service d'interruption dans le noyau.
- Il est très nécessaire de comprendre ces scénarios, car ils tuent en coulisses lorsque des problèmes de performances surviennent avec le changement de contexte.
Changement de contexte de fil de discussion
La plus grande différence entre les threads et les processus est que les threads sont l'unité de base de la planification des tâches
, tandis que les processus sont l'unité de base del'acquisition des ressources. Pour parler franchement, la soi-disant planification des tâches dans le noyau planifie en fait les threads ; et les processus ne fournissent que des ressources telles que la mémoire virtuelle et les variables globales pour les threads. Ainsi, pour les threads et les processus, nous pouvons le comprendre de cette façon :
Lorsqu'un processus n'a qu'un seul thread, on peut considérer qu'un processus est égal à un thread
- Lorsqu'un processus comporte plusieurs threads, ces threads partagent les mêmes ressources, telles que la mémoire virtuelle et les variables globales.
- De plus, les threads disposent également de leurs propres données privées, telles que des piles et des registres, qui doivent également être enregistrées lors des changements de contexte.
- De cette façon, le changement de contexte de fil de discussion peut en fait être divisé en deux situations :
Tout d’abord, les deux threads avant et après appartiennent à des processus différents. À l'heure actuelle, puisque les ressources ne sont pas partagées, le processus de commutation est le même que le changement de contexte de processus.
- Deuxièmement, les deux threads avant et après appartiennent au même processus. À ce stade, puisque la mémoire virtuelle est partagée, les ressources de mémoire virtuelle restent inchangées pendant la commutation, et seules les données privées, registres et autres données non partagées du thread doivent être commutées.
- Évidemment, le changement de thread au sein d'un même processus consomme moins de ressources que le changement de plusieurs processus. C'est aussi l'avantage du multi-threading au lieu du multi-processus.
Changement de contexte d'interruption
En plus des deux changements de contexte précédents, il existe un autre scénario qui génère également un changement de contexte CPU, à savoir interruption
.Afin de répondre rapidement aux événements, les interruptions matérielles interrompront le processus normal de planification et d'exécution, puis appelleront le gestionnaire d'interruption
.Lors de l'interruption d'autres processus, l'état actuel du processus doit être enregistré afin que le processus puisse toujours être restauré à partir de son état d'origine après l'interruption.
Contrairement au contexte de processus, le changement de contexte d'interruption n'implique pas l'état utilisateur du processus. Par conséquent, même si le processus d'interruption interrompt le processus en mode utilisateur, il n'est pas nécessaire de sauvegarder et de restaurer les ressources du mode utilisateur telles que la mémoire virtuelle et les variables globales du processus.De plus, comme la commutation de contexte de processus, la commutation de contexte d'interruption consomme également du CPU. Des temps de commutation excessifs consommeront beaucoup de ressources CPU et réduiront même considérablement les performances globales du système. Par conséquent, lorsque vous constatez qu'il y a trop d'interruptions, vous devez faire attention à vérifier si cela entraînera de graves problèmes de performances pour votre système.
Conclusion
En résumé, quel que soit le scénario qui conduit à un changement de contexte, vous devez savoir :
La commutation de contexte CPU est l'une des fonctions essentielles pour assurer le fonctionnement normal du système Linux et ne nécessite généralement pas notre attention particulière.Cependant, un changement de contexte excessif consommera du temps CPU pour sauvegarder et restaurer des données telles que les registres, les piles de noyau, la mémoire virtuelle, etc., raccourcissant ainsi le temps d'exécution réel du processus et entraînant une diminution significative des performances globales du système.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!