
Maison >Périphériques technologiques >IA >Le premier framework universel dans le domaine des graphes est là ! Sélectionné dans ICLR\'24 Spotlight, tout problème d'ensemble de données et de classification peut être résolu
Le premier framework universel dans le domaine des graphes est là ! Sélectionné dans ICLR\'24 Spotlight, tout problème d'ensemble de données et de classification peut être résolu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-04 10:45:221133parcourir
Peut-il exister un modèle graphique universel——
qui puisse prédire la toxicité en fonction de la structure moléculaire et recommander des amis sur les réseaux sociaux ?
Ou pouvez-vous non seulement prédire les citations des articles de différents auteurs, mais également découvrir le mécanisme du vieillissement humain dans le réseau génétique ?
Ne me dites pas, le cadre « One for All(OFA) » accepté comme Spotlight par ICLR 2024 a réalisé cette « essence ».
Cette recherche a été proposée conjointement par des chercheurs tels que l’équipe du professeur Chen Yixin de l’Université de Washington à Saint-Louis, Zhang Muhan de l’Université de Pékin et Tao Dacheng du JD Research Institute.
En tant que premier cadre général dans le domaine graphique, OFA permet de former un seul modèle GNN pour résoudre les tâches de classification de n'importe quel ensemble de données, n'importe quel type de tâche et n'importe quelle scène dans le champ graphique.

Comment le mettre en œuvre spécifiquement, ce qui suit est la contribution de l'auteur.
La conception de modèles universels dans le domaine des graphes se heurte à trois difficultés majeures
Concevoir un modèle de base universel pour résoudre une variété de tâches est un objectif à long terme dans le domaine de l'intelligence artificielle. Ces dernières années, les grands modèles de langage de base (LLM) ont bien fonctionné dans le traitement des tâches en langage naturel.
Cependant, dans le domaine des graphiques, bien que les réseaux de neurones graphiques (GNN) aient de bonnes performances dans différentes données graphiques, comment concevoir et former un modèle graphique de base capable de gérer plusieurs tâches graphiques en même temps reste un moyen en avant vaste.
Par rapport au domaine du langage naturel, la conception de modèles généraux dans le domaine des graphes se heurte à de nombreuses difficultés uniques.
Tout d'abord, à la différence du langage naturel, différentes données graphiques ont des attributs et des distributions complètement différents.
Par exemple, un diagramme moléculaire décrit comment plusieurs atomes forment différentes substances chimiques à travers différentes relations de force. Le diagramme des relations de citation décrit le réseau de citations mutuelles entre les articles.
Ces différentes données graphiques sont difficiles à unifier dans un cadre de formation.
Deuxièmement, contrairement à toutes les tâches des LLM, qui peuvent être converties en tâches de génération de contexte unifiée, les tâches de graphe incluent une variété de sous-tâches, telles que les tâches de nœuds, les tâches de liens, les tâches de graphe complet, etc.
Différentes sous-tâches nécessitent généralement différentes représentations de tâches et différents modèles graphiques.
Enfin, le succès des grands modèles de langage est indissociable de l'apprentissage contextuel (apprentissage en contexte) obtenu grâce à des paradigmes rapides.
Dans les grands modèles de langage, le paradigme d'invite est généralement une description textuelle lisible de la tâche en aval.
Mais pour les données graphiques non structurées et difficiles à décrire avec des mots, comment concevoir un paradigme d'invite graphique efficace pour réaliser un apprentissage en contexte reste un mystère non résolu.
Utilisez le concept de « diagramme de texte » pour le résoudre
La figure suivante donne le cadre général d'OFA :
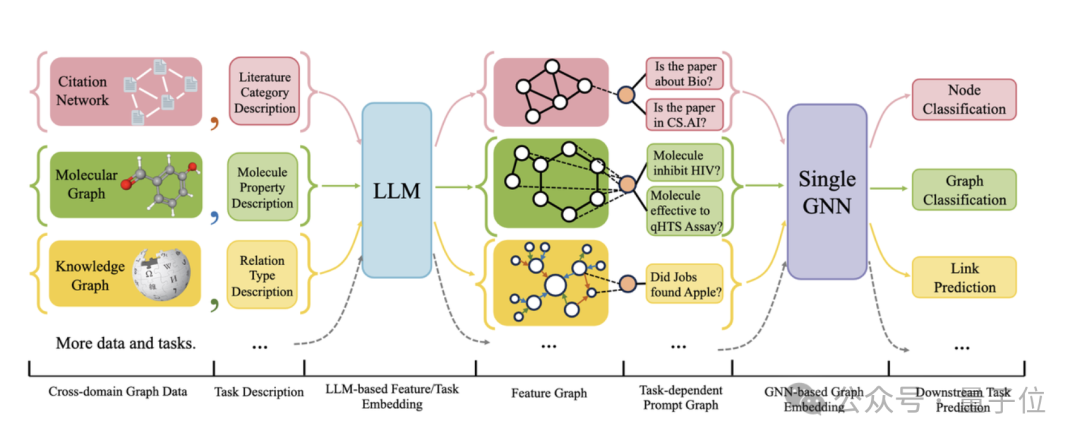
Plus précisément, l'équipe d'OFA résout les trois principaux problèmes mentionnés ci-dessus grâce à une conception intelligente .
Pour le problème des différents attributs et distributions de données graphiques, OFA unifie toutes les données graphiques en proposant le concept de Text-Attributed Graph (TAGs) . À l'aide de graphiques textuels, OFA décrit les informations de nœud et les informations de bord dans toutes les données graphiques à l'aide d'un cadre de langage naturel unifié, comme le montre la figure suivante :


(NOI) sous-graphique et nœud d'invite NOI (NOI Prompt Node) pour unifier différents types de sous-tâches dans le champ graphique. Ici, NOI représente un ensemble de nœuds cibles participant à la tâche correspondante.
Par exemple, dans la tâche de prédiction de nœuds, le NOI fait référence à un seul nœud qui doit être prédit tandis que dans la tâche de lien, le NOI comprend deux nœuds qui doivent prédire le lien ; Le sous-graphe NOI fait référence à un sous-graphe contenant des quartiers de sauts h étendus autour de ces nœuds NOI.
Ensuite, le nœud d'invite NOI est un type de nœud nouvellement introduit, directement connecté à tous les NOI.
L'important est que chaque nœud d'invite NOI contient des informations de description de la tâche en cours. Ces informations existent sous forme de langage naturel et sont représentées par le même LLM que le graphique de texte.
Étant donné que les informations contenues dans les nœuds du NOI seront collectées par le nœud d'invite NOI après avoir transmis le message des GNN, le modèle GNN n'a besoin que de faire des prédictions via le nœud d'invite NOI.
De cette façon, tous les différents types de tâches auront une représentation unifiée des tâches. L'exemple spécifique est présenté dans la figure ci-dessous :
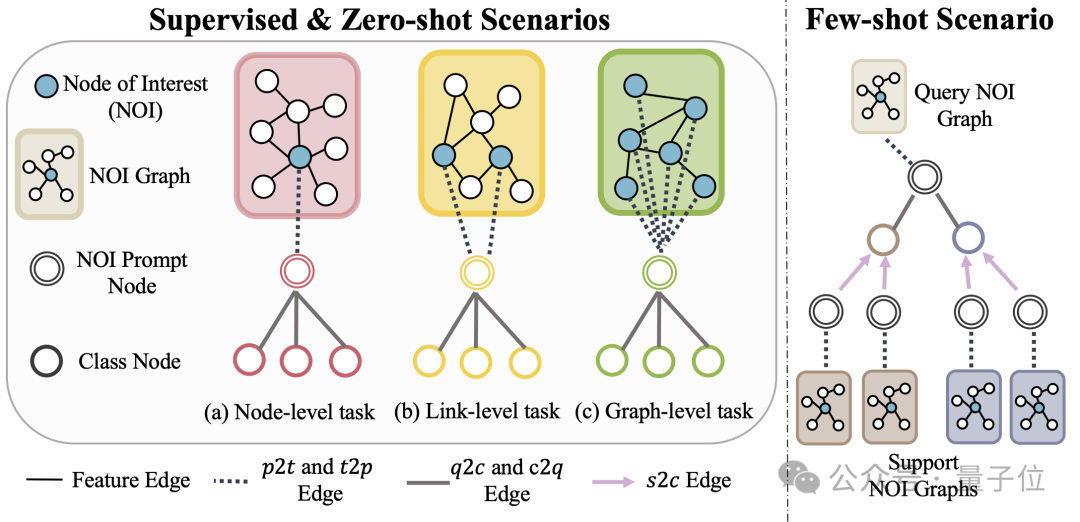
Enfin, afin de réaliser un apprentissage en contexte dans le champ du graphique, OFA introduit un sous-graphe d'invite unifié.
Dans un scénario de tâche de classification supervisée k-way, ce sous-graphe d'invite contient deux types de nœuds : l'un est le nœud d'invite NOI mentionné ci-dessus, et l'autre est constitué de nœuds de catégorie représentant k catégories différentes (nœud de classe).
Le texte de chaque nœud de catégorie décrira les informations pertinentes de cette catégorie.
Les nœuds d'invite NOI seront connectés à tous les nœuds de catégorie dans une direction. Le graphe construit de cette manière sera introduit dans le modèle de réseau neuronal graphique pour la transmission et l'apprentissage des messages.
Enfin, OFA effectuera une tâche de classification binaire sur chaque nœud de catégorie et prendra le nœud de catégorie avec la probabilité la plus élevée comme résultat de prédiction final.
Étant donné que les informations de catégorie existent dans le sous-graphe de repère, même si un problème de classification complètement nouveau est rencontré, OFA peut prédire directement sans aucun réglage fin en construisant le sous-graphe de repère correspondant, réalisant ainsi un apprentissage sans tir.
Pour les scénarios d'apprentissage en quelques étapes, une tâche de classification comprendra un graphique d'entrée de requête et plusieurs graphiques d'entrée de support. Le paradigme de graphique d'invite d'OFA connectera le nœud d'invite NOI de chaque graphique d'entrée de support à son nœud de catégorie correspondant, et en même temps. Le nœud d'invite NOI du graphique d'entrée de requête est connecté à tous les nœuds de catégorie.
Les étapes de prédiction suivantes sont cohérentes avec ce qui précède. De cette manière, chaque nœud de catégorie recevra des informations supplémentaires du graphique d'entrée de support, réalisant ainsi un apprentissage en quelques étapes sous un paradigme unifié.
Les principales contributions de l'OFA sont résumées comme suit :
Distribution unifiée des données graphiques : en proposant des graphiques textuels et en utilisant LLM pour transformer les informations textuelles, OFA réalise l'alignement de la distribution et l'unification des données graphiques.
Formulaire de tâche graphique uniforme : grâce aux sous-graphiques NOI et aux nœuds d'invite NOI, OFA obtient une représentation unifiée des sous-tâches dans divers champs graphiques.
Paradigme d'incitation graphique unifié : en proposant un nouveau paradigme d'incitation graphique, OFA réalise un apprentissage multi-scénarios en contexte dans le domaine des graphiques.
Super capacité de généralisation
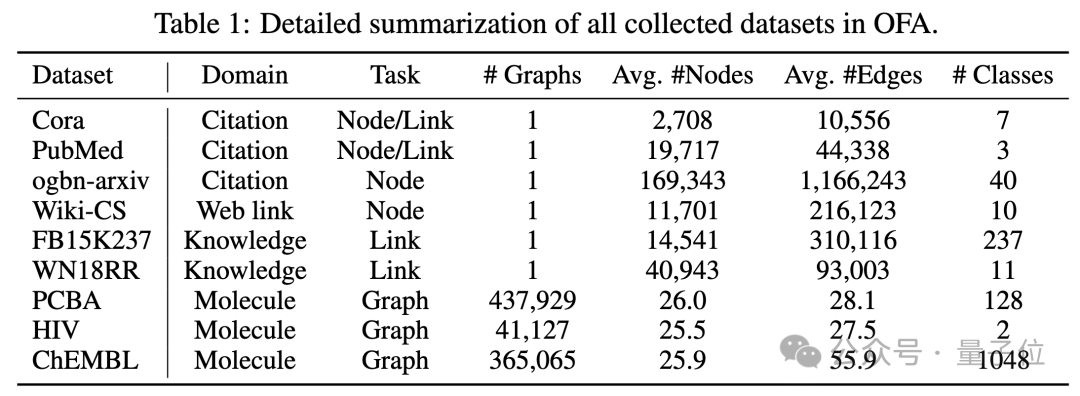
L'article a testé le cadre OFA sur 9 ensembles de données collectées. Ces tests ont couvert dix tâches différentes dans des scénarios d'apprentissage supervisé, y compris la prédiction de nœuds, la prédiction de liens et la classification de figures.
Le but de l'expérience est de vérifier la capacité d'un seul modèle OFA à gérer plusieurs tâches, dans laquelle l'auteur compare l'utilisation de différents LLM (OFA-{LLM}) et la formation de modèles distincts pour chaque tâche (OFA-ind-{LLM}) Effet.
Les résultats de la comparaison sont présentés dans le tableau suivant :
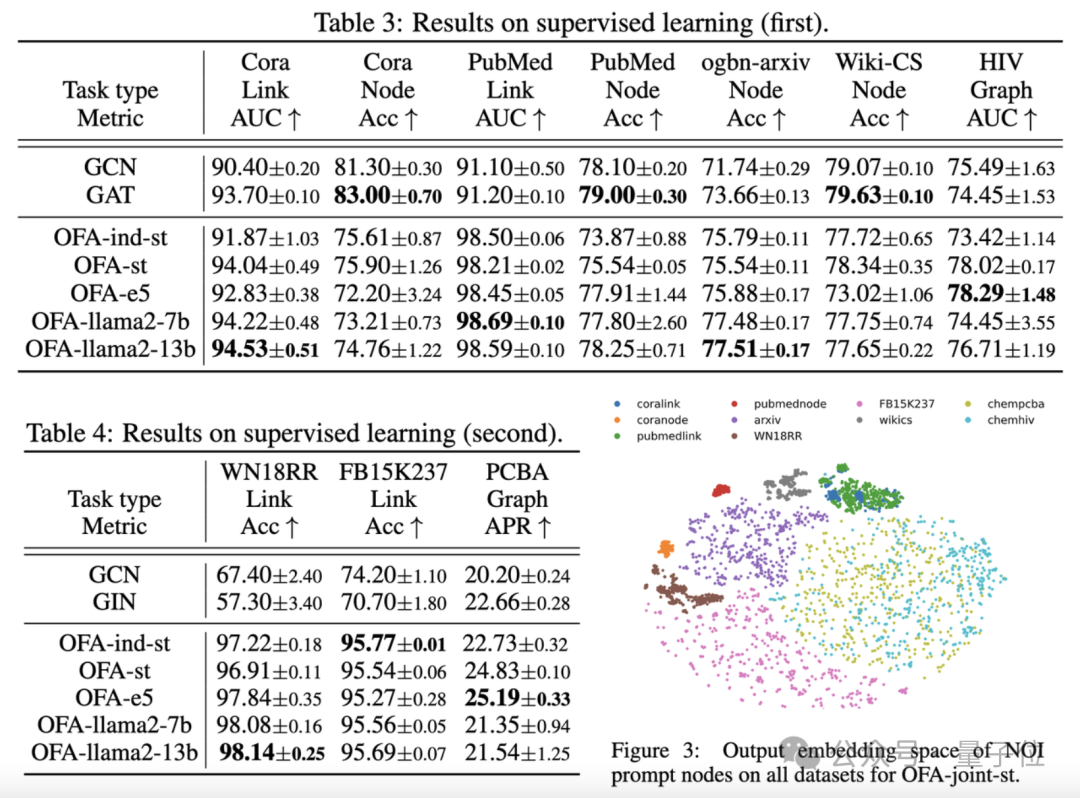
On peut voir que, sur la base de la puissante capacité de généralisation d'OFA, un modèle de graphique distinct (OFA-st, OFA-e5, OFA-llama2-7b, OFA -llama2 -13b)C'est-à-dire qu'il peut avoir des performances similaires ou meilleures que le modèle de formation séparé traditionnel(GCN, GAT, OFA-ind-st) sur toutes les tâches.
Dans le même temps, l'utilisation d'un LLM plus puissant peut apporter certaines améliorations de performances. L'article trace en outre la représentation des nœuds d'invite NOI pour différentes tâches par le modèle OFA formé.
Vous pouvez voir que différentes tâches sont intégrées dans différents sous-espaces par le modèle, de sorte qu'OFA puisse apprendre différentes tâches séparément sans s'affecter les unes les autres.
Dans le scénario de quelques échantillons et de zéro échantillon, OFA utilise un modèle unique sur ogbn-arxiv(graphe de référence), FB15K237(graphe de connaissances) et Chemble(graphe moléculaire) pour la pré-formation et les tests. performances sur différentes tâches et ensembles de données en aval. Les résultats sont les suivants :
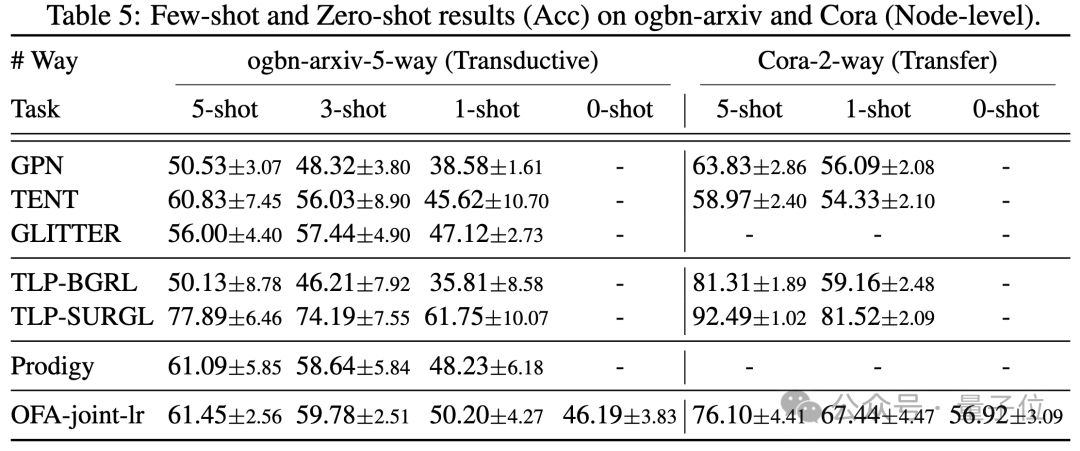
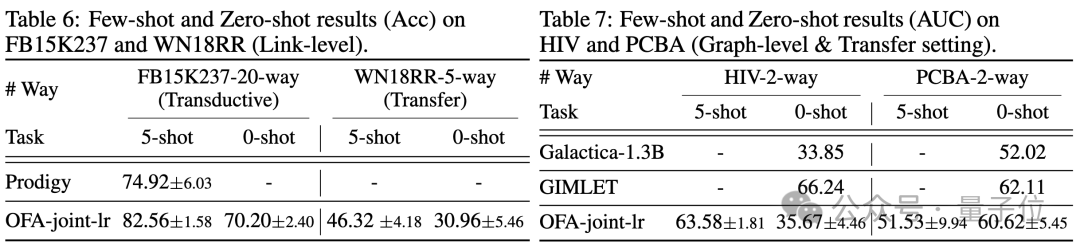
On peut voir que même dans le scénario sans échantillon, OFA peut toujours obtenir de bons résultats. Pris ensemble, les résultats expérimentaux vérifient bien les puissantes performances générales de l’OFA et son potentiel en tant que modèle de base dans le domaine des graphes.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Adresse : https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/LechengKong/OneForAll
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tutoriel vidéo de formation pratique sur la conception fonctionnelle du système logiciel Java
- Comment importer la mise en page du modèle CAO
- Quels sont les modèles courants de développement de logiciels ?
- Comment utiliser PHP et swoole pour créer une plateforme de réseau social hautement disponible ?
- Nouvelle avancée dans l'habillage par l'IA : après un entraînement avec 1 million de photos, la précision de la déconstruction et de la reconstruction des vêtements est de 95,7 %