
Maison >Périphériques technologiques >IA >Apprenez et grandissez grâce aux critiques comme les humains, 1 317 commentaires ont multiplié par 30 le taux de victoire de LLaMA2
Apprenez et grandissez grâce aux critiques comme les humains, 1 317 commentaires ont multiplié par 30 le taux de victoire de LLaMA2

- PHPzavant
- 2024-02-04 09:20:38700parcourir
Les méthodes d'alignement de grands modèles existantes incluent le réglage fin supervisé basé sur des exemples (SFT) et l'apprentissage par renforcement basé sur les commentaires de score (RLHF). Cependant, le score ne peut que refléter la qualité de la réponse actuelle et ne peut pas indiquer clairement les lacunes du modèle. En revanche, nous, les humains, apprenons et ajustons généralement nos modèles de comportement à partir de commentaires verbaux. Tout comme les commentaires d'évaluation ne constituent pas seulement une note, mais incluent également de nombreuses raisons d'acceptation ou de rejet. Alors, les grands modèles linguistiques peuvent-ils utiliser le feedback linguistique pour s'améliorer comme les humains ?
Des chercheurs de l'Université chinoise de Hong Kong et du Tencent AI Lab ont récemment proposé une recherche innovante appelée Contrastive Improbable Learning (CUT). La recherche utilise le feedback linguistique pour ajuster les modèles linguistiques afin qu’ils puissent apprendre et s’améliorer grâce à différentes critiques, tout comme les humains. Cette recherche vise à améliorer la qualité et la précision des modèles de langage afin de les rendre plus cohérents avec la façon dont les humains pensent. En comparant l'entraînement par non-vraisemblance, les chercheurs espèrent permettre au modèle linguistique de mieux comprendre et de s'adapter à diverses situations d'utilisation du langage, améliorant ainsi ses performances dans les tâches de traitement du langage naturel. Cette recherche innovante promet d'être une méthode simple et efficace pour les modèles de langage
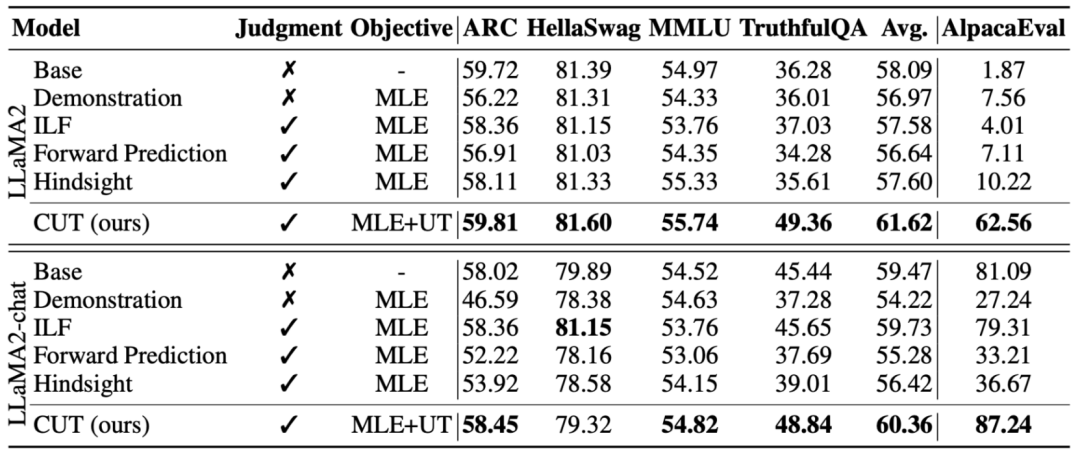
CUT est une méthode simple et efficace. En utilisant seulement 1 317 données de retour linguistique, CUT a pu améliorer considérablement le taux de victoire de LLaMA2-13b sur AlpacaEval, passant de 1,87 % à 62,56 %, et a vaincu avec succès 175B DaVinci003. Ce qui est passionnant, c'est que CUT peut également effectuer un cycle itératif d'exploration, de critique et d'amélioration, comme d'autres cadres d'apprentissage par renforcement et de retour d'apprentissage par renforcement (RLHF). Dans ce processus, l'étape de critique peut être complétée par le modèle d'évaluation automatique pour parvenir à l'auto-évaluation et à l'amélioration de l'ensemble du système.
L'auteur a effectué quatre séries d'itérations sur LLaMA2-chat-13b, améliorant progressivement les performances du modèle sur AlpacaEval de 81,09 % à 91,36 %. Par rapport à la technologie d'alignement basée sur le retour de score (DPO), CUT fonctionne mieux avec la même taille de données. Les résultats révèlent que la rétroaction linguistique présente un grand potentiel de développement dans le domaine de l’alignement, ouvrant de nouvelles possibilités pour de futures recherches sur l’alignement. Cette découverte a des implications importantes pour améliorer la précision et l’efficacité des techniques d’alignement et fournit des conseils pour réaliser de meilleures tâches de traitement du langage naturel.

- Lien de l'article : https://arxiv.org/abs/2312.14591
- Lien Github : https://github.com/wwxu21/CUT
- Alignement de grands modèles
Sur la base de travaux existants, les chercheurs ont résumé deux manières courantes d'aligner de grands modèles : 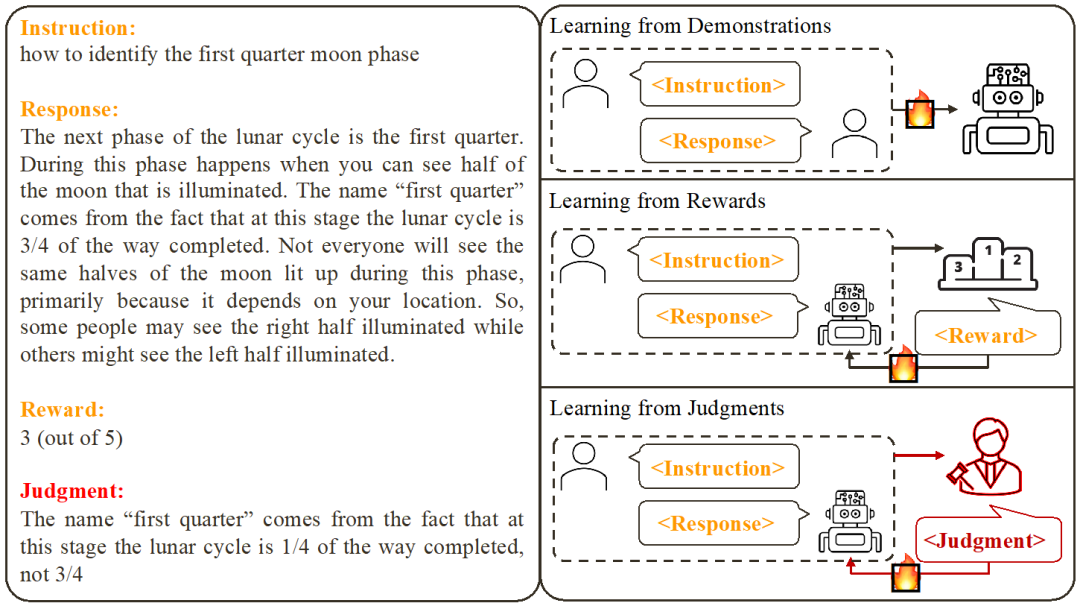
1. Apprendre de la démonstration : sur la base de paires instructions-réponses prêtes à l'emploi, utilisez des méthodes de formation supervisées pour aligner de grands modèles.
Avantages : formation stable ; mise en œuvre simple.
- Inconvénients : Il est coûteux de collecter des exemples de données diversifiés et de haute qualité ; les exemples de données ne sont souvent pas pertinents pour le modèle.
- 2. Apprendre à partir des récompenses : notez les paires commande-réponse et utilisez l'apprentissage par renforcement pour entraîner le modèle afin de maximiser le score de sa réponse.
Avantages : peut utiliser à la fois des réponses correctes et des réponses d'erreur. Les signaux de retour sont liés au modèle. Inconvénients : les signaux de rétroaction sont rares ; le processus de formation est souvent complexe.
- Cette recherche se concentre sur l'apprentissage à partir du Retour linguistique
- (Learning from Judgments) : donner des instructions - répondre pour rédiger des commentaires, sur la base du retour linguistique pour améliorer les défauts du modèle, maintenir les avantages du modèle, et améliorant ainsi les performances du modèle.
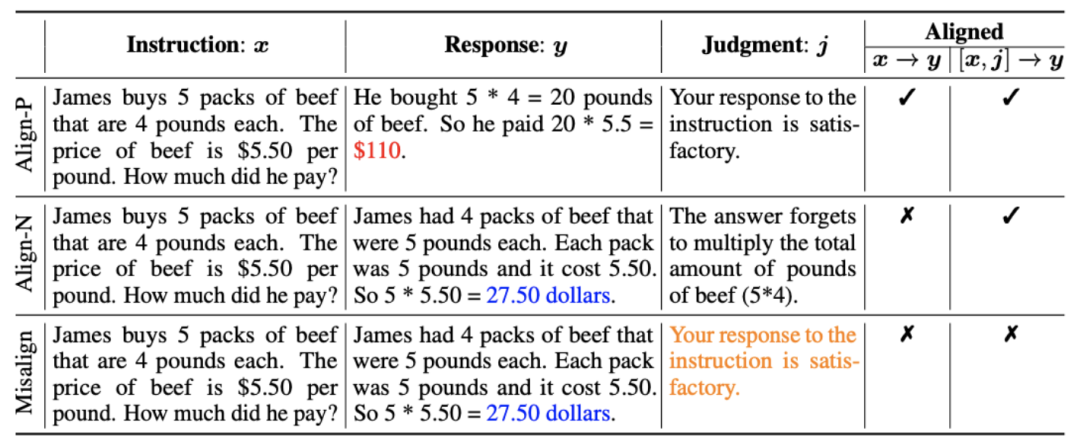
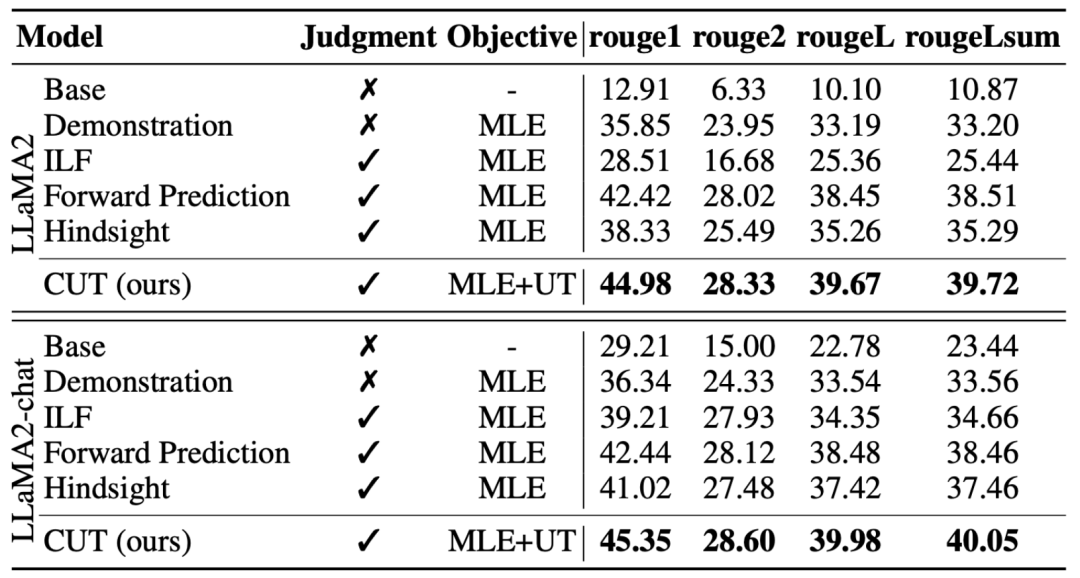
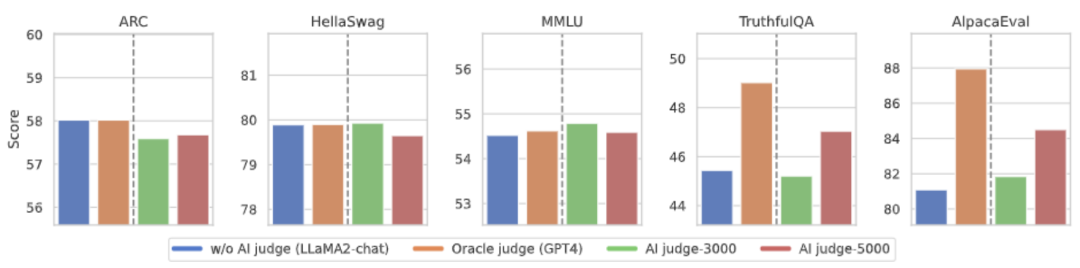
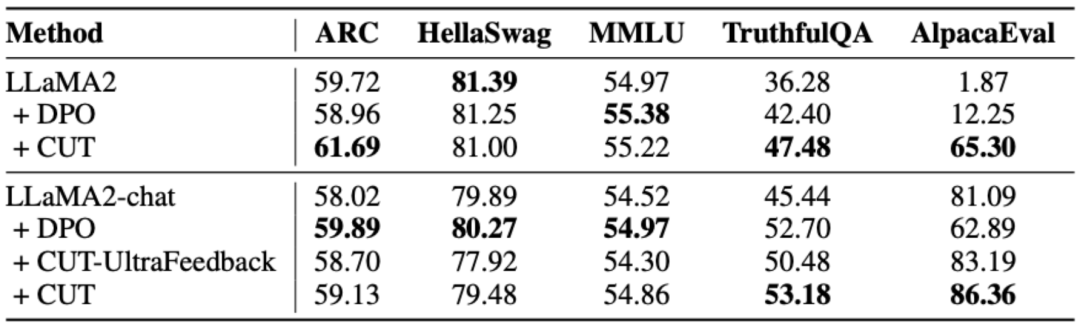
L'idée principale de CUT est d'apprendre du contraste. Les chercheurs comparent les réponses de grands modèles dans différentes conditions pour déterminer quelles pièces sont satisfaisantes et doivent être entretenues, et quelles pièces sont défectueuses et doivent être modifiées. Sur cette base, les chercheurs utilisent l'estimation du maximum de vraisemblance (MLE) pour former la partie satisfaisante, et utilisent la formation par improbabilité (UT) pour modifier les défauts de la réponse. 1. Scénario d'alignement : Comme le montre la figure ci-dessus, les chercheurs ont envisagé deux scénarios d'alignement : a) b) 2. Données d'alignement : Comme le montre la figure ci-dessus, sur la base des deux scénarios d'alignement ci-dessus, les chercheurs ont construit trois types de données d'alignement : a) Align-P : Le grand modèle généré C'est incroyable Satisfait réponse, d'où les retours positifs. De toute évidence, Align-P satisfait l'alignement dans les scénarios b) Align-N : Le grand modèle génère des réponses erronées (en gras bleu) et reçoit donc des commentaires négatifs. Pour Align-N, l'alignement n'est pas satisfait en c) Misalign : les vrais commentaires négatifs dans Align-N sont remplacés par un faux retour positif. De toute évidence, Misalign ne satisfait pas l’alignement dans les deux scénarios 3. Apprendre de la comparaison : a) Align-N vs Misalign : La différence entre les deux réside principalement dans le degré d'alignement sous Afin de tirer les leçons de cette comparaison, les chercheurs ont saisi simultanément les données Align-N et Misalign dans le grand modèle pour obtenir les probabilités de génération des mots de sortie dans les deux conditions où Les chercheurs ont utilisé un entraînement par improbabilité (UT) sur ces mots inappropriés identifiés, obligeant ainsi le grand modèle à explorer des réponses plus satisfaisantes. Pour les autres mots de réponse, les chercheurs utilisent toujours l'estimation du maximum de vraisemblance (MLE) pour optimiser : où b) Align-P vs. Align-N : La différence entre les deux réside principalement dans le degré d'alignement sous où CUT L'objectif final d'entraînement combine les deux ensembles de comparaisons ci-dessus : 1. Alignement hors ligne Afin d'économiser de l'argent, les chercheurs ont d'abord essayé d'utiliser des données de retour linguistique prêtes à l'emploi pour aligner de grands modèles. Cette expérience a été utilisée pour démontrer la capacité de CUT à utiliser le feedback linguistique. a) Modèle universel Comme le montre le tableau ci-dessus, pour l'alignement général du modèle, les chercheurs ont utilisé 1317 données d'alignement fournies par Shepherd pour comparer CUT avec des modèles esclaves existants dans des conditions de démarrage à froid (LLaMA2) et de démarrage à chaud (LLaMA2-chat). . Dans le cadre de l'expérience de démarrage à froid basée sur LLaMA2, CUT a largement dépassé les méthodes d'alignement existantes sur la plateforme de test AlpacaEval, prouvant pleinement ses avantages dans l'utilisation du retour linguistique. De plus, CUT a également réalisé des améliorations significatives dans TruthfulQA par rapport au modèle de base, ce qui révèle que CUT a un grand potentiel pour atténuer le problème d'hallucination des grands modèles. Dans le scénario de démarrage à chaud basé sur LLaMA2-chat, les méthodes existantes ne parviennent pas à améliorer LLaMA2-chat et ont même des effets négatifs. Cependant, CUT peut encore améliorer les performances du modèle de base sur cette base, vérifiant une fois de plus le grand potentiel de CUT dans l'utilisation du feedback linguistique. b) Modèle expert Les chercheurs ont également testé l'effet d'alignement de CUT sur une tâche experte spécifique (résumé de texte). Comme le montre le tableau ci-dessus, CUT réalise également des améliorations significatives par rapport aux méthodes d'alignement existantes sur les tâches expertes. 2. Alignement en ligne La recherche sur l'alignement hors ligne a démontré avec succès la puissante performance d'alignement de CUT. Aujourd’hui, les chercheurs explorent davantage des scénarios d’alignement en ligne qui se rapprochent davantage des applications pratiques. Dans ce scénario, les chercheurs annotent de manière itérative les réponses du grand modèle cible avec un retour linguistique afin que le modèle cible puisse être aligné plus précisément en fonction du retour linguistique qui lui est associé. Le processus spécifique est le suivant : Comme le montre la figure ci-dessus, après quatre séries d'itérations d'alignement en ligne, CUT peut toujours obtenir des résultats impressionnants avec seulement 4 000 données d'entraînement et une petite taille de modèle de 13B, 91,36 points. Cette réalisation démontre une fois de plus l’excellente performance et l’énorme potentiel de CUT. 3. Modèle de commentaire AI Considérant le coût de l'étiquetage des commentaires linguistiques, les chercheurs tentent de former un modèle de jugement pour étiqueter automatiquement les commentaires linguistiques pour le grand modèle cible. Comme le montre la figure ci-dessus, les chercheurs ont utilisé 5 000 éléments (AI Judge-5000) et 3 000 éléments (AI Judge-3000) de données de retour linguistique pour former deux modèles d'évaluation. Les deux modèles d'examen ont obtenu des résultats remarquables dans l'optimisation du modèle cible à grande échelle, en particulier l'effet de l'IA Judge-5000. Cela prouve la faisabilité de l'utilisation de modèles de révision par l'IA pour aligner les grands modèles cibles, et souligne également l'importance de la qualité du modèle de révision dans l'ensemble du processus d'alignement. Cet ensemble d’expériences fournit également un soutien solide pour réduire les coûts d’annotation à l’avenir. 4. Commentaires sur la langue et commentaires sur les scores Pour explorer en profondeur l'énorme potentiel du feedback linguistique dans l'alignement de grands modèles, les chercheurs ont comparé CUT basé sur le feedback linguistique avec la méthode basée sur le feedback de score (DPO). Afin de garantir une comparaison équitable, les chercheurs ont sélectionné 4 000 ensembles des mêmes paires instruction-réponse comme échantillons expérimentaux, permettant à CUT et DPO d’apprendre respectivement du retour de score et du retour de langage correspondant à ces données. Comme le montre le tableau ci-dessus, dans l'expérience de démarrage à froid (LLaMA2), CUT a obtenu des résultats nettement meilleurs que DPO. Dans l'expérience de démarrage à chaud (LLaMA2-chat), CUT peut obtenir des résultats comparables à DPO sur des tâches telles que ARC, HellaSwag, MMLU et TruthfulQA, et est nettement en avance sur DPO sur la tâche AlpacaEval. Cette expérience a confirmé le plus grand potentiel et les avantages du feedback linguistique par rapport au feedback fractionnaire lors de l'alignement d'un grand modèle. Dans ce travail, les chercheurs ont systématiquement exploré la situation actuelle du feedback linguistique dans l'alignement de grands modèles et ont proposé de manière innovante un cadre d'alignement CUT basé sur le feedback linguistique, révélant que le feedback linguistique a un grand potentiel et des avantages. dans le domaine de l'alignement de grands modèles. De plus, il existe de nouvelles orientations et de nouveaux défis dans la recherche sur le feedback linguistique, tels que : 1 Qualité du modèle de commentaire : Bien que les chercheurs aient confirmé avec succès la faisabilité de la formation d'un modèle de commentaire, en. l'observation Lors de la sortie du modèle, ils ont encore constaté que le modèle d'évaluation donnait souvent des notes inexactes. Par conséquent, l’amélioration de la qualité du modèle de révision revêt une importance cruciale pour l’utilisation à grande échelle du feedback linguistique à des fins d’alignement à l’avenir. 2. Introduction de nouvelles connaissances : Lorsque le feedback linguistique implique des connaissances qui manquent au grand modèle, même si le grand modèle peut identifier avec précision les erreurs, il n'y a pas de direction claire pour la modification. Par conséquent, il est très important de compléter les connaissances qui manquent au grand modèle lors de l’alignement. 3. Alignement multimodal : Le succès des modèles de langage a favorisé la recherche de grands modèles multimodaux, tels que la combinaison du langage, de la parole, des images et des vidéos. Dans ces scénarios multimodaux, l’étude du feedback linguistique et du feedback des modalités correspondantes a ouvert la voie à de nouvelles définitions et à de nouveaux défis. Formation sur la non-vraisemblance contrastée
 : Il s'agit du scénario d'alignement communément compris dans ce scénario. , les réponses doivent suivre fidèlement les instructions et être cohérentes avec les attentes et les valeurs humaines.
: Il s'agit du scénario d'alignement communément compris dans ce scénario. , les réponses doivent suivre fidèlement les instructions et être cohérentes avec les attentes et les valeurs humaines.  : Ce scénario introduit la rétroaction verbale comme condition supplémentaire. Dans ce scénario, la réponse doit satisfaire à la fois aux instructions et aux commentaires verbaux. Par exemple, lorsqu'il reçoit un retour négatif, le grand modèle doit commettre des erreurs en fonction des problèmes mentionnés dans le retour correspondant.
: Ce scénario introduit la rétroaction verbale comme condition supplémentaire. Dans ce scénario, la réponse doit satisfaire à la fois aux instructions et aux commentaires verbaux. Par exemple, lorsqu'il reçoit un retour négatif, le grand modèle doit commettre des erreurs en fonction des problèmes mentionnés dans le retour correspondant.  et
et  .
.  . Mais après avoir pris en compte ces retours négatifs, Align-N est toujours aligné dans le scénario
. Mais après avoir pris en compte ces retours négatifs, Align-N est toujours aligné dans le scénario 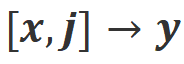 .
.  et
et 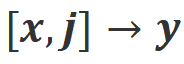 .
. 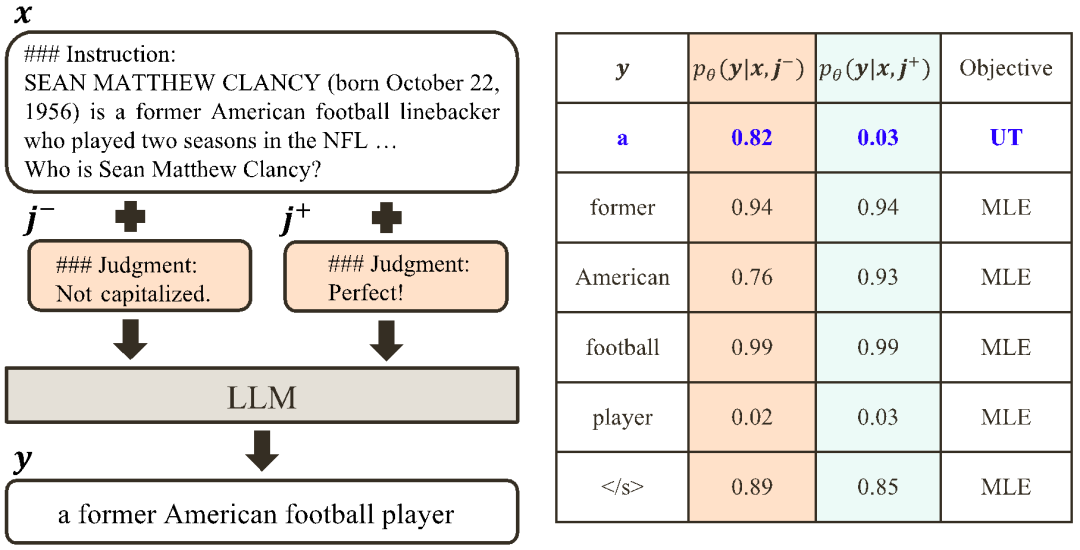
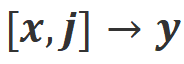 . Compte tenu des puissantes capacités d'apprentissage en contexte des grands modèles, le changement de polarité d'alignement d'Align-N à Misalign s'accompagne généralement d'un changement significatif dans la probabilité de génération de mots spécifiques, en particulier les mots qui sont étroitement liés à de véritables commentaires négatifs. Comme le montre la figure ci-dessus, sous la condition Align-N (canal gauche), la probabilité qu'un grand modèle génère « a » est nettement plus élevée que Misalign (canal droit). Et c’est là où la probabilité change de manière significative que le grand modèle commet une erreur.
. Compte tenu des puissantes capacités d'apprentissage en contexte des grands modèles, le changement de polarité d'alignement d'Align-N à Misalign s'accompagne généralement d'un changement significatif dans la probabilité de génération de mots spécifiques, en particulier les mots qui sont étroitement liés à de véritables commentaires négatifs. Comme le montre la figure ci-dessus, sous la condition Align-N (canal gauche), la probabilité qu'un grand modèle génère « a » est nettement plus élevée que Misalign (canal droit). Et c’est là où la probabilité change de manière significative que le grand modèle commet une erreur. 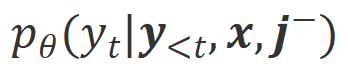 et
et 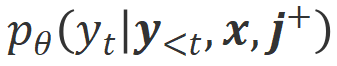 respectivement. Les mots qui ont une probabilité de génération significativement plus élevée dans la condition
respectivement. Les mots qui ont une probabilité de génération significativement plus élevée dans la condition 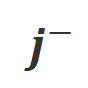 que dans la condition
que dans la condition  sont marqués comme mots inappropriés. Plus précisément, les chercheurs ont utilisé les normes suivantes pour quantifier la définition des mots inappropriés :
sont marqués comme mots inappropriés. Plus précisément, les chercheurs ont utilisé les normes suivantes pour quantifier la définition des mots inappropriés : 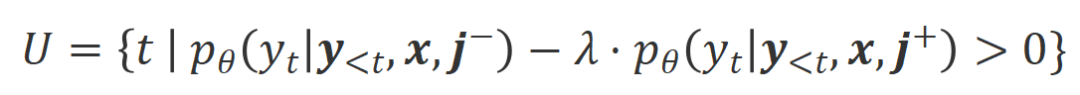
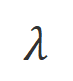 est un hyperparamètre qui pèse la précision et le rappel dans le processus de reconnaissance des mots inappropriés.
est un hyperparamètre qui pèse la précision et le rappel dans le processus de reconnaissance des mots inappropriés. 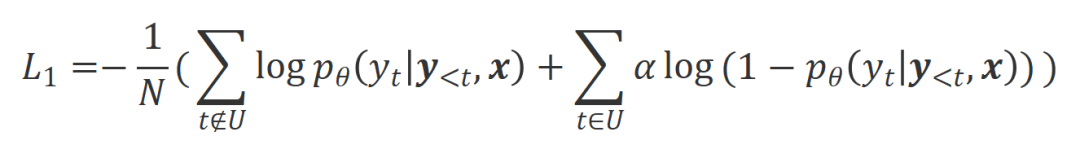
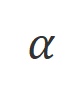 est un hyperparamètre qui contrôle la proportion d'entraînement de non-vraisemblance,
est un hyperparamètre qui contrôle la proportion d'entraînement de non-vraisemblance,  est le nombre de mots de réponse .
est le nombre de mots de réponse .  . Essentiellement, le grand modèle contrôle la qualité de la réponse de sortie en introduisant un retour de langue de différentes polarités. Par conséquent, la comparaison entre les deux peut inspirer de grands modèles pour distinguer les réponses satisfaisantes des réponses défectueuses. Plus précisément, les chercheurs ont appris de cet ensemble de comparaisons grâce à la perte d'estimation du maximum de vraisemblance (MLE) suivante :
. Essentiellement, le grand modèle contrôle la qualité de la réponse de sortie en introduisant un retour de langue de différentes polarités. Par conséquent, la comparaison entre les deux peut inspirer de grands modèles pour distinguer les réponses satisfaisantes des réponses défectueuses. Plus précisément, les chercheurs ont appris de cet ensemble de comparaisons grâce à la perte d'estimation du maximum de vraisemblance (MLE) suivante : 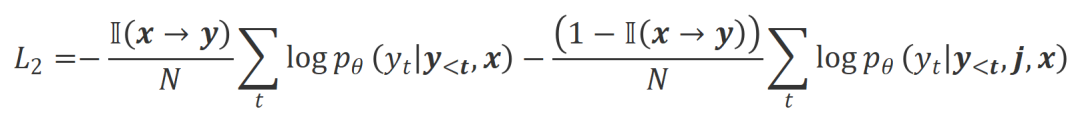
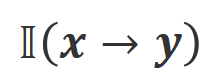 est la fonction indicatrice, renvoyant 1 si les données satisfont à l'alignement
est la fonction indicatrice, renvoyant 1 si les données satisfont à l'alignement 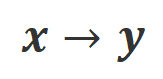 , sinon renvoie 0.
, sinon renvoie 0. 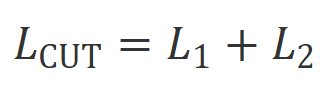 .
. Évaluation expérimentale
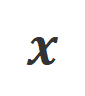 et obtenez la réponse
et obtenez la réponse  du grand modèle cible.
du grand modèle cible.
 .
.
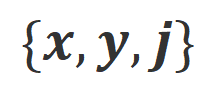 .
.

Résumé et défis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!