
Maison >Périphériques technologiques >IA >Le modèle Transformer apprend avec succès le monde physique à l'aide de 2 milliards de points de données lors de la génération de vidéos de défi
Le modèle Transformer apprend avec succès le monde physique à l'aide de 2 milliards de points de données lors de la génération de vidéos de défi

- 王林avant
- 2024-01-29 09:09:261308parcourir
Construire un modèle mondial capable de créer des vidéos peut également être réalisé grâce à Transformer !
Des chercheurs de l'Université Tsinghua et de Jiji Technology ont uni leurs forces pour lancer un nouveau modèle mondial universel de génération vidéo : WorldDreamer.
Il peut effectuer une variété de tâches de génération vidéo, y compris des scènes naturelles et des scènes de conduite autonome, telles que des vidéos Vincent, des vidéos Tu, du montage vidéo, des vidéos de séquences d'action, etc.

Selon l'équipe, WorldDreamer est le premier du secteur à construire un modèle mondial de scénario universel en prédisant les jetons.
Il convertit la génération vidéo en une tâche de prédiction de séquence, qui peut pleinement apprendre les changements et les modèles de mouvement du monde physique.
Les expériences visuelles ont prouvé que WorldDreamer a une compréhension profonde des changements dynamiques du monde en général.
Alors, quelles tâches vidéo peut-il accomplir et quelle est son efficacité ?
Prend en charge plusieurs tâches vidéo
Image vers vidéo (image vers vidéo)
WorldDreamer peut prédire les images futures en fonction d'une seule image.
Seule la première image est saisie, WorldDreamer traite les images vidéo restantes comme des jetons visuels masqués et prédit ces jetons.
Comme le montre l'image ci-dessous, WorldDreamer a la capacité de générer des vidéos de haute qualité au niveau du film.
Les vidéos résultantes présentent un mouvement image par image fluide, similaire aux mouvements fluides de la caméra dans de vrais films.
De plus, ces vidéos respectent strictement les contraintes de l'image originale, assurant une cohérence remarquable dans la composition des images.

Text to Video
WorldDreamer peut également générer des vidéos basées sur du texte.
En fonction de la saisie de texte dans la langue, WorldDreamer considère toutes les images vidéo comme des jetons visuels masqués et prédit ces jetons.
L'image ci-dessous démontre la capacité de WorldDreamer à générer des vidéos à partir de texte selon différents paradigmes de style.
La vidéo générée s'adapte parfaitement à la langue d'entrée, où la langue saisie par l'utilisateur peut façonner le contenu vidéo, le style et le mouvement de la caméra.

Video Inpainting
WorldDreamer peut implémenter davantage de tâches d'inpainting vidéo.
Plus précisément, étant donné une vidéo, l'utilisateur peut spécifier la zone de masque, puis le contenu vidéo de la zone masquée peut être modifié en fonction de la langue saisie.
Comme le montre l'image ci-dessous, WorldDreamer peut remplacer la méduse par un ours ou le lézard par un singe, et la vidéo remplacée est tout à fait cohérente avec la description linguistique de l'utilisateur.

Stylisation vidéo
De plus, WorldDreamer peut styliser les vidéos.
Comme le montre l'image ci-dessous, saisissez un segment vidéo dans lequel certains pixels sont masqués de manière aléatoire, et WorldDreamer peut modifier le style de la vidéo, par exemple en créant un effet de thème d'automne basé sur la langue d'entrée.

Basé sur une vidéo de synthèse d'action (Action to Video)
WorldDreamer peut également générer une action de conduite en vidéo dans des scénarios de conduite autonome.
Comme le montre la figure ci-dessous, étant donné la même image initiale et différentes stratégies de conduite (telles que virage à gauche, virage à droite), WorldDreamer peut générer des vidéos hautement conformes aux premières contraintes d'image et stratégies de conduite.

Alors, comment WorldDreamer réalise-t-il ces fonctions ?
Construisez un modèle mondial avec Transformer
Les chercheurs estiment que les méthodes de génération vidéo les plus avancées sont principalement divisées en deux catégories : les méthodes basées sur un transformateur et les méthodes basées sur un modèle de diffusion.
L'utilisation de Transformer pour la prédiction de jetons peut apprendre efficacement les informations dynamiques des signaux vidéo et réutiliser l'expérience de la grande communauté de modèles de langage. Par conséquent, la solution basée sur Transformer est un moyen efficace d'apprendre un modèle mondial général.
Les méthodes basées sur des modèles de diffusion sont difficiles à intégrer plusieurs modes dans un seul modèle et sont difficiles à étendre à des paramètres plus larges, il est donc difficile d'apprendre les changements et les lois de mouvement du monde en général.
La recherche actuelle sur les modèles mondiaux se concentre principalement dans les domaines des jeux, des robots et de la conduite autonome, et n'a pas la capacité de capturer de manière exhaustive les changements généraux du monde et les modèles de mouvement.
Ainsi, l'équipe de recherche a proposé WorldDreamer pour améliorer l'apprentissage et la compréhension des changements et des schémas de mouvement dans le monde en général, améliorant ainsi considérablement la capacité de génération de vidéos.
S'appuyant sur l'expérience réussie des modèles de langage à grande échelle, WorldDreamer adopte l'architecture Transformer pour convertir le cadre de modélisation de modèles mondiaux en un problème de prédiction de jetons visuels non supervisé.
La structure spécifique du modèle est illustrée dans la figure ci-dessous :
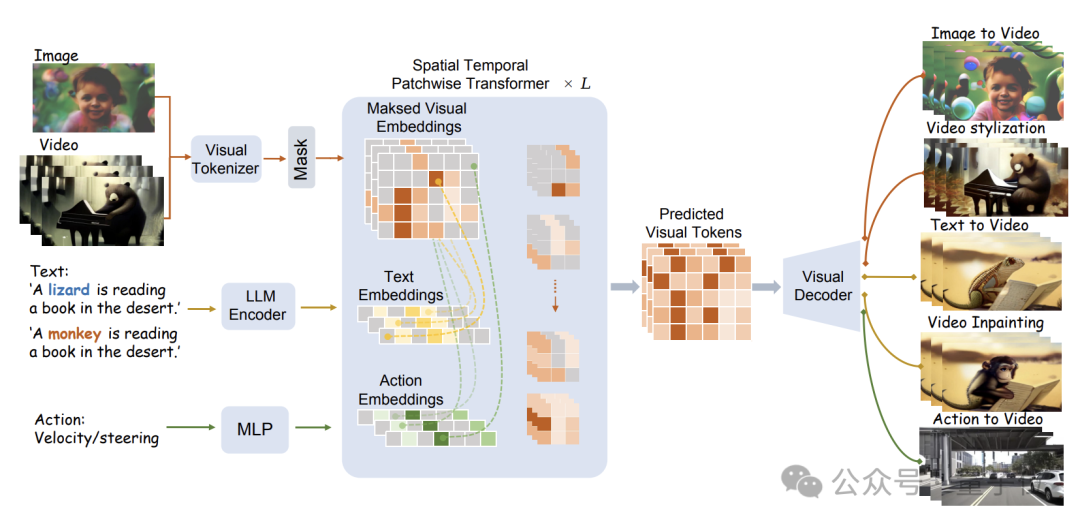
WorldDreamer utilise d'abord un Tokenizer visuel pour coder les signaux visuels (images et vidéos) en jetons discrets.
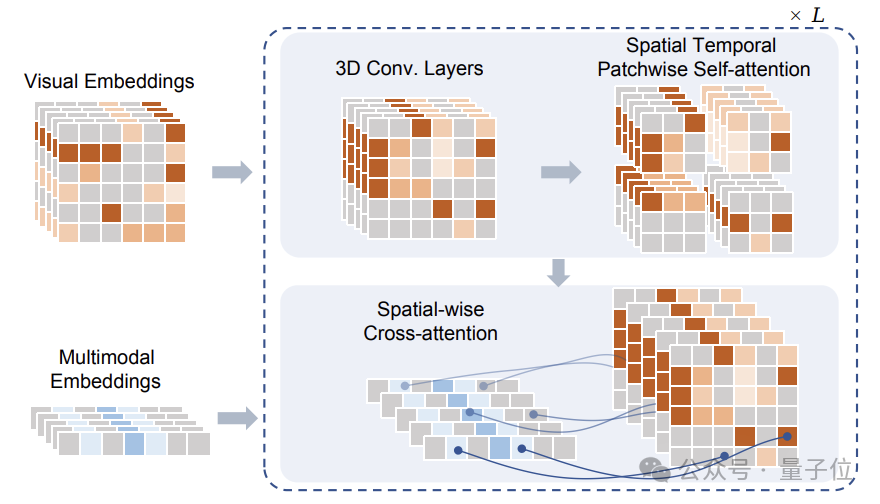
Après masquage, ces jetons sont entrés dans le module Sptial Temporal Patchwuse Transformer (STPT) proposé par l'équipe de recherche.
Dans le même temps, les signaux de texte et d'action sont codés respectivement dans les vecteurs de fonctionnalités correspondants pour être entrés dans STPT en tant que fonctionnalités multimodales.
STPT apprend de manière entièrement interactive les fonctionnalités visuelles, le langage, l'action et d'autres fonctionnalités en interne, et peut prédire le jeton visuel de la partie masquée.
En fin de compte, ces jetons visuels prédits peuvent être utilisés pour effectuer diverses tâches de génération et de montage vidéo.
Il convient de noter que lors de l'entraînement de WorldDreamer, l'équipe de recherche a également construit un triplet de données Visual-Text-Action (visuel-texte-action), et la fonction de perte pendant l'entraînement implique uniquement la prédiction du jeton de vision masquée, il n'y a pas de signal de supervision supplémentaire.
Dans le triplet de données proposé par l'équipe, seules des informations visuelles sont requises, ce qui signifie que l'entraînement WorldDreamer peut toujours être effectué même sans texte ni données d'action.
Ce mode réduit non seulement la difficulté de la collecte de données, mais permet également à WorldDreamer de prendre en charge l'exécution de tâches de génération vidéo sans connaître ou avec une seule condition.
L'équipe de recherche a utilisé une grande quantité de données pour former WorldDreamer, dont 2 milliards de données d'images nettoyées, 10 millions de vidéos de scènes courantes, 500 000 vidéos annotées en langage de haute qualité et près d'un millier de vidéos de scènes de conduite autonome.
L'équipe a mené des millions de formations itératives sur 1 milliard de niveaux de paramètres apprenables. Après la convergence, WorldDreamer a progressivement compris les changements et les schémas de mouvement du monde physique et dispose de diverses capacités de génération et de montage vidéo.
Adresse papier : https://arxiv.org/abs/2401.09985
Page d'accueil du projet : https://world-dreamer.github.io/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!