
Maison >Tutoriel système >Linux >Application d'apprentissage automatique pour l'exploitation et la maintenance automatisées des SGBD
Application d'apprentissage automatique pour l'exploitation et la maintenance automatisées des SGBD

- 王林avant
- 2024-01-24 12:21:16711parcourir
Un système de gestion de base de données (SGBD) est un élément essentiel de toute application gourmande en données. Ils peuvent gérer de grandes quantités de données et des charges de travail complexes, mais ils sont également difficiles à gérer car il existe des centaines, voire des milliers de « boutons » (variables de configuration) qui contrôlent divers facteurs, tels que la quantité de mémoire à utiliser pour la mise en cache et l'écriture sur le disque. . fréquence. Les organisations doivent souvent embaucher des experts pour effectuer les réglages, et les experts coûtent trop cher pour de nombreuses organisations. Les étudiants et les chercheurs du groupe de recherche sur les bases de données de l'université Carnegie Mellon développent un nouvel outil appelé OtterTune qui peut trouver automatiquement les bons paramètres pour les « boutons » d'un SGBD. Le but de l'outil est de permettre à n'importe qui de déployer un SGBD, même sans aucune expertise en administration de bases de données.
OtterTune est différent des autres outils de configuration de SGBD car il utilise la connaissance des réglages précédents du SGBD pour régler un nouveau SGBD, ce qui réduit considérablement le temps et les ressources consommés. OtterTune y parvient en conservant une base de connaissances accumulée lors des réglages précédents. Ces données accumulées sont utilisées pour créer des modèles d'apprentissage automatique (ML) afin de capturer la réaction du SGBD à différents paramètres. OtterTune utilise ces modèles pour guider l'expérimentation de nouvelles applications, en suggérant des configurations qui améliorent les objectifs finaux, tels que la réduction de la latence et l'augmentation du débit.
Dans cet article, nous discuterons de chacun des composants du pipeline d'apprentissage automatique d'OtterTune et de la manière dont ils interagissent pour affiner la configuration de votre SGBD. Nous évaluons ensuite les performances de réglage d'OtterTune sur MySQL et Postgres, en comparant ses configurations optimales avec celles des DBA et d'autres outils de réglage automatisés.
OtterTune est un outil open source développé par des étudiants et des chercheurs du Database Research Group de l'Université Carnegie Mellon. Tout le code est hébergé sur Github et publié sous la licence Apache License 2.0.
Comment fonctionne OtterTuneL'image ci-dessous montre les composants et le flux de travail d'OtterTune
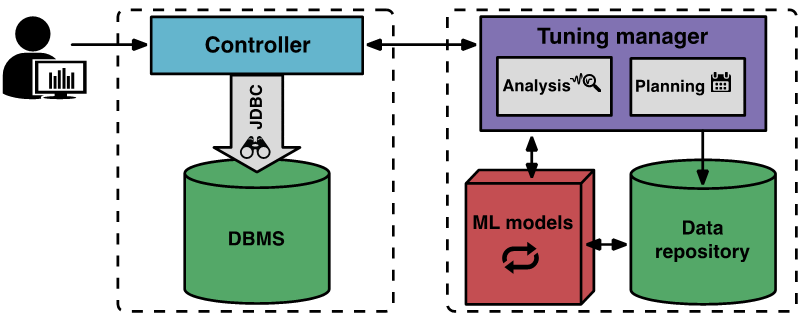
Le processus de réglage commence lorsque l'utilisateur indique à OtterTune l'objectif final à régler (par exemple, latence ou débit), et que le programme de contrôleur client se connecte au SGBD cible et collecte le type d'instance Amazon EC2 et la configuration actuelle.
Ensuite, le contrôleur démarre la première période d'observation pour observer et enregistrer la cible finale. Une fois l'observation terminée, le contrôleur collecte les métriques internes du SGBD, telles que le nombre de lectures et d'écritures des pages disque MySQL. Le contrôleur renvoie ces données au programme de gestion de réglage.
Le gestionnaire de réglage d'OtterTune enregistre les données métriques reçues dans la base de connaissances. OtterTune utilise ces résultats pour calculer la prochaine configuration du SGBD cible et la renvoie au contrôleur avec l'amélioration des performances estimée. L'utilisateur peut décider de poursuivre ou d'arrêter le processus de réglage.
AttentionOtterTune maintient une liste noire de « boutons » pour chaque version du SGBD prise en charge, y compris ceux qui sont insignifiants au réglage (comme le chemin pour enregistrer le fichier de données), ou ceux qui auront des conséquences graves ou cachées (comme la perte de données) . OtterTune fournit cette liste noire à l'utilisateur au début du processus de réglage, et l'utilisateur peut ajouter d'autres « boutons » qu'il souhaite qu'OtterTune évite.
OtterTune a des hypothèses prédéterminées qui peuvent entraîner certaines limitations pour certains utilisateurs. Par exemple, il suppose que l'utilisateur dispose des droits d'administrateur pour que le contrôleur puisse modifier la configuration du SGBD. Sinon, les utilisateurs doivent déployer une copie de la base de données sur un autre matériel pour qu'OtterTune puisse effectuer des expériences de réglage. Cela oblige les utilisateurs à reproduire la charge de travail ou à transmettre les requêtes au SGBD de production. Consultez notre article pour connaître les préréglages et restrictions complets.
Pipeline d'apprentissage automatiqueL'image ci-dessous montre le processus de traitement des données du pipeline OtterTune ML, et toutes les observations sont enregistrées dans la base de connaissances.
OtterTune transmet d'abord les données d'observation au composant de caractérisation de la charge de travail, qui peut identifier un petit ensemble de métriques de SGBD qui capturent le plus efficacement les changements de performances et les caractéristiques saillantes des différentes charges de travail.
Étape suivante, le « composant d'identification des boutons » génère une liste de classement des boutons, comprenant les boutons qui ont le plus grand impact sur les performances du SGBD. OtterTune « transmet » ensuite toutes ces informations au Tuner automatique, qui mappe la charge de travail du SGBD cible à la charge de travail la plus proche dans la base de connaissances et réutilise ces données de charge de travail pour générer une meilleure configuration.
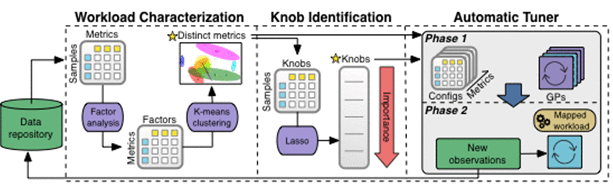
Approfondissons ci-dessous chaque composant du pipeline d’apprentissage automatique.
Caractérisation de la charge de travail : OtterTune exploite les métriques d'exécution internes du SGBD pour caractériser le comportement d'une certaine charge de travail. Ces métriques représentent avec précision la charge de travail car elles capturent plusieurs aspects du comportement de la charge de travail. Cependant, de nombreux indicateurs sont redondants : certains représentent la même mesure dans différentes unités, d'autres représentent un composant indépendant du SGBD, mais leurs valeurs sont fortement corrélées. Il est important d’éliminer les mesures redondantes pour réduire la complexité des modèles d’apprentissage automatique. Par conséquent, nous regroupons les métriques du SGBD en fonction de la corrélation et sélectionnons la plus représentative, en particulier celle la plus proche de la médiane. Les composants ultérieurs de l’apprentissage automatique utiliseront ces mesures.
Identification des boutons : un SGBD peut avoir des centaines de boutons, mais seuls certains d'entre eux affectent les performances. OtterTune utilise une technique de sélection de fonctionnalités populaire appelée Lasso pour déterminer quels boutons ont le plus grand impact sur les performances globales de votre système. En utilisant cette technique pour traiter les données de la base de connaissances, OtterTune a pu déterminer l'ordre d'importance des boutons du SGBD.
Ensuite, OtterTune doit décider du nombre de boutons à utiliser lors des recommandations de configuration. L'utilisation d'un trop grand nombre de boutons augmentera considérablement le temps de réglage d'OtterTune, tandis que l'utilisation de trop peu de boutons rendra difficile la recherche de la meilleure configuration. OtterTune utilise une approche incrémentielle pour automatiser ce processus, en augmentant progressivement le nombre de boutons utilisés lors d'une session de réglage. Cette approche permet à OtterTune d'explorer et d'affiner la configuration avec un petit nombre de boutons les plus importants d'abord, puis de l'étendre pour prendre en compte d'autres boutons.
Auto-tuner : le composant tuner automatique utilise une méthode d'analyse en deux étapes pour décider quelle configuration recommander après chaque phase d'observation.
Tout d'abord, le système utilise les données de performances trouvées par le composant de caractérisation de la charge de travail pour identifier le processus de réglage historique le plus proche de la charge de travail du SGBD cible actuelle, en comparant les deux métriques pour confirmer quelles valeurs répondent de la même manière aux différents paramètres des boutons.
OtterTune essaie ensuite une autre configuration de bouton, appliquant un modèle statistique aux données collectées et aux données de charge de travail les plus proches de la base de connaissances. Ce modèle permet à OtterTune de prédire les performances du SGBD dans toutes les configurations possibles. OtterTune ajuste la configuration suivante, en alternant entre exploration (collecte d'informations pour améliorer le modèle) et exploitation (approche avide de la métrique cible).
RéaliséOtterTune est écrit en Python.
Pour les composants de caractérisation de la charge de travail et d'identification des boutons, les performances d'exécution ne sont pas une considération majeure, nous utilisons donc scikit-learn pour implémenter l'algorithme d'apprentissage automatique correspondant. Ces algorithmes s'exécutent en arrière-plan et absorbent les données nouvellement générées dans la base de connaissances.
Pour le réglage automatique des composants, les algorithmes d'apprentissage automatique sont très critiques. Chaque phase d'observation doit être exécutée une fois terminée, absorbant de nouvelles données afin qu'OtterTune puisse choisir le prochain bouton à tester. Puisque les performances doivent être prises en compte, nous utilisons TensorFlow pour les implémenter.
Pour collecter le matériel SGBD, la configuration des boutons et les mesures de performances d'exécution, nous avons intégré le framework de référence OLTP-Bench dans le contrôleur d'OtterTune.
Conception expérimentaleNous avons comparé les meilleures configurations OtterTune pour MySQL et Postgres avec les options de configuration suivantes pour évaluation :
Par défaut : configuration initiale du SGBD
Script de réglage : Configuration effectuée par un outil de suggestion de réglage open source
DBA : Configuration choisie par le DBA humain
RDS : appliquez une configuration personnalisée d'un SGBD géré par un développeur Amazon au même type d'instance EC2.
Nous avons effectué toutes les expériences sur les instances Amazon EC2 Spot. Chaque expérience s'exécute sur deux instances, de type m4.large et m3.xlarge : une pour le contrôleur OtterTune et une pour le déploiement du SGBD cible. Le gestionnaire de réglage OtterTune et la base de connaissances sont déployés localement sur un serveur de mémoire à 20 cœurs de 128 Go.
La charge de travail utilise TPC-C, qui est la norme industrielle pour évaluer les performances des systèmes de trading en ligne.
ÉvaluationNous avons mesuré la latence et le débit pour chacune des bases de données de l'expérience – MySQL et Postgres – et les graphiques ci-dessous montrent les résultats. Le premier graphique montre le nombre de « latence du 99e centile », qui représente le temps « dans le pire des cas » nécessaire pour terminer une transaction. Le deuxième graphique montre les résultats de débit, mesurés comme le nombre moyen de transactions exécutées par seconde.
Résultats de l'expérience MySQLConfiguration optimale générée par OtterTune par rapport à la configuration du script de réglage et de RDS, OtterTune a réduit la latence MySQL d'environ 60 % et augmenté le débit de 22 % à 35 %. OtterTune génère également une configuration presque aussi bonne que DBA.
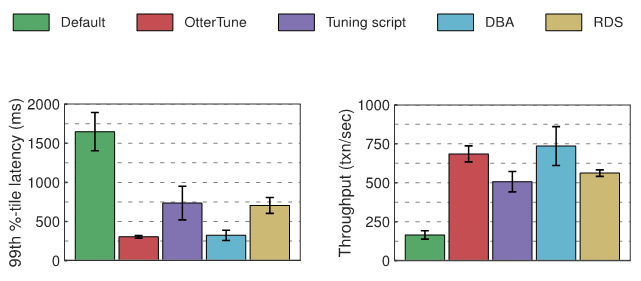
Sous les charges TPC-C, seuls quelques boutons MySQL affectent de manière significative les performances. La configuration d'OtterTune et de DBA règle ces boutons sur de bonnes valeurs. RDS a obtenu des résultats légèrement moins bons car un bouton s'est vu attribuer une valeur sous-optimale. Le script de réglage a donné les pires résultats car un seul bouton a été modifié.
Résultats de l'expérience Postgres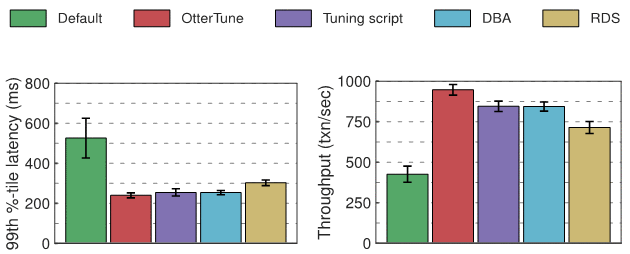
En termes de latence, par rapport à la configuration par défaut de Postgres, les configurations d'OtterTune, des outils de réglage, de DBA et de RDS ont obtenu des améliorations similaires. Nous pouvons probablement attribuer cela à la surcharge réseau entre le client OLTP-Bench et le SGBD. En termes de débit, Postgres est 12 % supérieur à celui des scripts DBA et de réglage lorsqu'il est configuré avec OtterTune, et 32 % supérieur à celui de RDS.
ConclusionOtterTune automatise le processus de recherche de valeurs optimales pour les boutons de configuration du SGBD. Il optimise un SGBD nouvellement déployé en réutilisant les données de formation collectées lors des processus de réglage précédents. Étant donné qu'OtterTune n'a pas besoin de générer un ensemble de données d'initialisation pour entraîner son modèle d'apprentissage automatique, le temps de réglage est considérablement réduit.
Quelle est la prochaine étape ? Conformément à la popularité croissante du DBaaS (où la connexion à distance à l'hôte du SGBD n'est pas possible), OtterTune sera bientôt en mesure de sonder automatiquement les capacités matérielles du SGBD cible sans nécessiter de connexion à distance.
Pour en savoir plus sur OtterTune, consultez notre article et notre code sur GitHub. Gardez un œil sur ce site car nous ferons bientôt d'OtterTune un service de réglage en ligne.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que Red Hat Linux ?
- Le frère open source de Linux, Red Hat, a été racheté par IBM pour 34 milliards de dollars
- Comment utiliser la commande de compression Linux Zip
- Comment filtrer et classer les journaux via les outils de ligne de commande Linux ?
- Oracle, SUSE et CIQ forment conjointement l'Open Enterprise Linux Association pour développer conjointement des versions de distribution compatibles avec Red Hat RHEL Enterprise Edition