



Le clustering K-means est un algorithme de clustering non supervisé couramment utilisé qui atteint une similarité intra-cluster élevée et une similarité inter-cluster en divisant l'ensemble de données en k clusters, chaque cluster contenant des points de données similaires à faible similarité. Cet article explique comment utiliser K-means pour le clustering non supervisé.
1. Le principe de base du clustering K-means
Le clustering K-means est un algorithme d'apprentissage non supervisé couramment utilisé. Son principe de base est de diviser les points de données en k clusters afin que chaque point de données appartienne à un. des clusters, et la similarité des points de données au sein du cluster est aussi élevée que possible, et la similarité entre les différents clusters est aussi faible que possible. Les étapes spécifiques sont les suivantes :
1. Initialisation : sélectionnez aléatoirement k points de données comme centres de cluster.
2. Affectation : attribuez chaque point de données au cluster où se trouve son centre de cluster le plus proche.
3. Mise à jour : Recalculez le centre du cluster de chaque cluster.
4. Répétez les étapes 2 et 3 jusqu'à ce que les clusters ne changent plus ou que le nombre d'itérations prédéterminé soit atteint.
L'objectif du clustering K-means est de minimiser la somme des distances entre les points de données de chaque cluster et le centre du cluster. Cette distance est également appelée « somme intra-cluster des carrés des erreurs (SSE). )". L'algorithme arrête d'itérer lorsque la valeur SSE ne diminue plus ou atteint un nombre prédéterminé d'itérations.
2. Étapes de mise en œuvre du clustering K-means
Les étapes de mise en œuvre de l'algorithme de clustering K-means sont les suivantes :
1 Sélectionnez k centres de cluster : sélectionnez aléatoirement k points de données dans l'ensemble de données. comme centre du cluster.
2. Calculer la distance : calculez la distance entre chaque point de données et k centres de cluster, et sélectionnez le cluster avec le centre de cluster le plus proche.
3. Mettez à jour le centre du cluster : recalculez le centre du cluster pour chaque cluster, c'est-à-dire que la coordonnée moyenne de tous les points de données du cluster est utilisée comme nouveau centre du cluster.
4. Répétez les étapes 2 et 3 jusqu'à ce que le nombre d'itérations prédéterminé soit atteint ou que les clusters ne changent plus.
5. Afficher les résultats du clustering : attribuez chaque point de données de l'ensemble de données au cluster final et affichez les résultats du clustering.
Lors de la mise en œuvre de l'algorithme de clustering K-means, vous devez faire attention aux points suivants :
1 Initialisation du centre du cluster : La sélection du centre du cluster a un grand impact sur l'effet de clustering. De manière générale, k points de données peuvent être sélectionnés au hasard comme centres de cluster.
2. Sélection des méthodes de calcul de distance : les méthodes de calcul de distance couramment utilisées incluent la distance euclidienne, la distance de Manhattan et la similarité cosinus, etc. Différentes méthodes de calcul de distance conviennent à différents types de données.
3. Sélection du nombre de clusters k : La sélection du nombre de clusters k est souvent une question subjective et doit être sélectionnée en fonction du scénario d'application spécifique. De manière générale, le nombre optimal de clusters peut être déterminé grâce à des méthodes telles que la méthode du coude et le coefficient de silhouette.
3. Avantages et inconvénients du clustering K-means
Les avantages du clustering K-means incluent :
1.
2. Peut gérer des ensembles de données à grande échelle.
3. Lorsque la distribution des données est relativement uniforme, l'effet de clustering est meilleur.
Les inconvénients du clustering K-means incluent :
1 Il est sensible à l'initialisation du centre du cluster et peut converger vers la solution optimale locale.
2. Le traitement des points anormaux n'est pas assez efficace.
3. Lorsque la répartition des données est inégale ou qu'il y a du bruit, l'effet de regroupement peut être médiocre.
4. Méthodes améliorées de clustering K-means
Afin de surmonter les limites du clustering K-means, les chercheurs ont proposé de nombreuses méthodes améliorées, notamment :
1.K-Medoids clustering : Modification le centre du cluster, d'un point de données à un point représentatif (médoïde) au sein du cluster, peut mieux gérer les valeurs aberrantes et le bruit.
2. Algorithmes de clustering basés sur la densité : tels que DBSCAN, OPTICS, etc., peuvent mieux gérer des clusters de densités différentes.
3. Regroupement spectral : traitez les points de données comme des nœuds dans le graphique, considérez la similarité comme des poids de bord et réalisez le regroupement grâce à la décomposition spectrale du graphique, qui peut gérer des clusters non convexes et des clusters de formes différentes.
4. Clustering hiérarchique : traitez les points de données comme des nœuds dans l'arborescence et implémentez le clustering en fusionnant ou en divisant continuellement les clusters pour obtenir la structure hiérarchique des clusters.
5. Clustering flou : attribuez des points de données à différents clusters. Chaque point de données a un degré d'appartenance pour chaque cluster, ce qui peut gérer des situations où l'incertitude des points de données est grande.
En bref, le clustering K-means est un algorithme de clustering non supervisé simple et efficace, mais ses limites doivent être prises en compte dans les applications pratiques, et d'autres méthodes d'amélioration peuvent être combinées pour améliorer l'effet de clustering.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

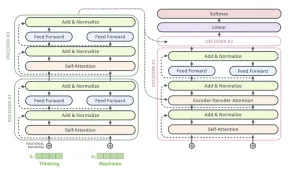 Essayez TEAPOTLLM pour des questions et réponses fiables, du chiffon et de l'extraction d'informationsApr 25, 2025 am 10:45 AM
Essayez TEAPOTLLM pour des questions et réponses fiables, du chiffon et de l'extraction d'informationsApr 25, 2025 am 10:45 AMTEAPOTLLM: un modèle de langue léger et résistant aux hallucinations Les modèles de génération de texte sont des outils puissants pour la recherche et les applications, en tirant parti de l'architecture, de la formation et des ensembles de données étendus pour obtenir des capacités remarquables. Open-S de Teapotai
 Quoi de neuf dans Devin 2.0? Breakdown complet à l'intérieurApr 25, 2025 am 10:43 AM
Quoi de neuf dans Devin 2.0? Breakdown complet à l'intérieurApr 25, 2025 am 10:43 AMDevin 2.0: révolutionner le développement de logiciels avec l'IA Devin 2.0 de Cognition AI transforme le fonctionnement des développeurs. Une mise à niveau significative de son prédécesseur, Devin 2.0 possède une vitesse, une efficacité et une facilité d'utilisation améliorées. Cet outil alimenté par IA STR
 Ai Art vs Art humain: La tendance de Ghibli est-elle un hommage ou un vol?Apr 25, 2025 am 10:37 AM
Ai Art vs Art humain: La tendance de Ghibli est-elle un hommage ou un vol?Apr 25, 2025 am 10:37 AMCe débat a commencé avec une vidéo Instagram critiquant la tendance virale de la transformation des photos en art de style Ghibli-Ghibli-de style Studio généré par l'IA. Le créateur de la vidéo a fait valoir qu'il s'agissait de vol, un raccourci irrespectueux sapant l'œuvre de vrais artistes. Ils ont affirmé
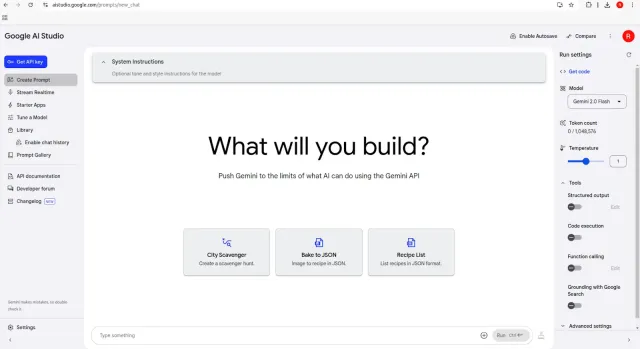 Guide du débutant sur Google AI StudioApr 25, 2025 am 10:32 AM
Guide du débutant sur Google AI StudioApr 25, 2025 am 10:32 AMDéverrouillez la puissance de Google AI Studio: votre terrain de jeu d'innovation AI Google AI Studio transforme vos rêves technologiques les plus fous en réalité, offrant une passerelle conviviale vers le monde de l'intelligence artificielle. Ce guide démystifie la machine complexe L
 5 plates-formes cloud abordables pour le réglage fin des LLMApr 25, 2025 am 10:30 AM
5 plates-formes cloud abordables pour le réglage fin des LLMApr 25, 2025 am 10:30 AMLes modèles de grande langue (LLMS) affinés sont coûteux, nécessitant des GPU puissants et des ressources informatiques substantielles. Cependant, les plates-formes cloud abordables offrent une alternative rentable aux fournisseurs traditionnels comme AWS, Google Cloud et Azure, de
 Deepseek V3 vs Llama 4: Quel modèle règne en maître? - Analytique VidhyaApr 25, 2025 am 10:27 AM
Deepseek V3 vs Llama 4: Quel modèle règne en maître? - Analytique VidhyaApr 25, 2025 am 10:27 AMDans le paysage en constante évolution des modèles de grands langues, Deepseek V3 vs Llama 4 est devenu l'un des affrontements les plus chauds pour les développeurs, les chercheurs et les amateurs d'IA. Que vous optimisiez pour le flamboyant inférieur
 Que sont les modèles open source et de poids ouvert?Apr 25, 2025 am 10:19 AM
Que sont les modèles open source et de poids ouvert?Apr 25, 2025 am 10:19 AMLes modèles Deepseek et GEMMA 3 de Google mettent en évidence la tendance croissante du développement de modèles d'IA "ouverte", mettant l'accent sur les capacités de raisonnement exceptionnelles et les conceptions légères. Openai est sur le point de contribuer à cet écosystème avec un prochain & quo
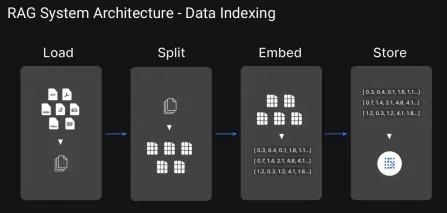 Top 13 techniques de chiffon avancé pour votre prochain projetApr 25, 2025 am 10:07 AM
Top 13 techniques de chiffon avancé pour votre prochain projetApr 25, 2025 am 10:07 AML'IA peut-elle générer des réponses vraiment pertinentes à grande échelle? Comment pouvons-nous nous assurer qu'il comprend des conversations complexes et multi-tournées? Et comment pouvons-nous l'empêcher de cracher en toute confiance des faits incorrects? Ce sont les types de défis que MO


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

