
Maison >Périphériques technologiques >IA >Le grand modèle Yi-VL est open source et se classe premier dans MMMU et CMMMU
Le grand modèle Yi-VL est open source et se classe premier dans MMMU et CMMMU

- WBOYavant
- 2024-01-22 21:30:21456parcourir
https://huggingface.co/01-ai https://www.modelscope.cn/organization/01ai



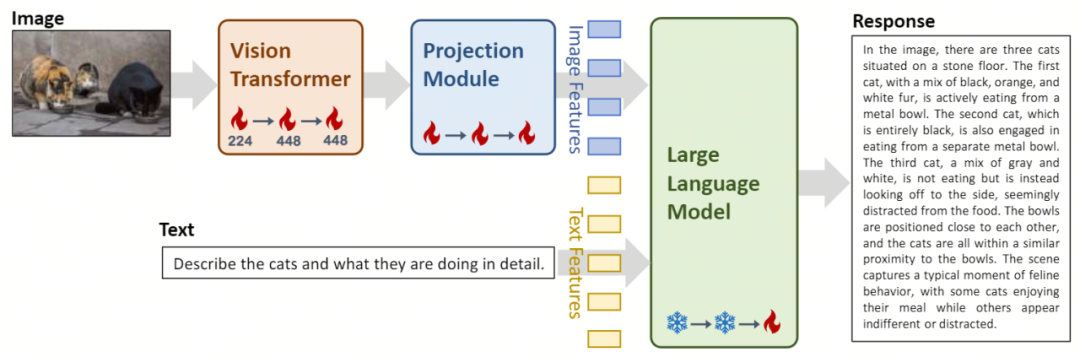
Vision Transformer (ViT en abrégé) est utilisé pour le codage d'images, à l'aide du modèle open source OpenClip ViT-H/14 initialise les paramètres entraînables et apprend à extraire des fonctionnalités de paires « image-texte » à grande échelle, donnant au modèle la capacité de traiter et de comprendre les images. Le module Projection apporte au modèle la possibilité d'aligner spatialement les caractéristiques de l'image avec les caractéristiques du texte. Ce module se compose d'un Perceptron Multicouche (MLP) contenant des normalisations de couches. Cette conception permet au modèle de fusionner et de traiter plus efficacement les informations visuelles et textuelles, améliorant ainsi la précision de la compréhension et de la génération multimodales. L'introduction des modèles linguistiques à grande échelle Yi-34B-Chat et Yi-6B-Chat fournit à Yi-VL de puissantes capacités de compréhension et de génération du langage. Cette partie du modèle utilise une technologie avancée de traitement du langage naturel pour aider Yi-VL à comprendre en profondeur les structures linguistiques complexes et à générer une sortie de texte cohérente et pertinente.
Phase 1 : Zero One Wish utilise 100 millions d'ensembles de données appariés « image-texte » pour former les modules ViT et Projection. À ce stade, la résolution de l’image est réglée sur 224 x 224 pour améliorer les capacités d’acquisition de connaissances de ViT dans des architectures spécifiques tout en permettant un alignement efficace avec de grands modèles de langage. La deuxième étape : Zero One Thing augmente la résolution de l'image de ViT à 448x448. Cette amélioration permet au modèle de mieux reconnaître les détails visuels complexes. Cette étape utilise environ 25 millions de paires image-texte. La troisième étape : Zero One Wish ouvre les paramètres de l'ensemble du modèle pour la formation, dans le but d'améliorer les performances du modèle dans l'interaction de chat multimodale. Les données de formation couvrent un large éventail de sources de données, avec un total d'environ 1 million de paires « image-texte », garantissant l'étendue et l'équilibre des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Cet article est reproduit dans:. en cas de violation, veuillez contacter admin@php.cn Supprimer
Article précédent:Comment organiser des projets d'apprentissage automatique : application de Crisp-DMArticle suivant:Comment organiser des projets d'apprentissage automatique : application de Crisp-DM
Articles Liés
Voir plus- La première alliance industrielle 5G RedCap au monde a été créée pour accélérer le développement de la technologie 5G.
- Un long article de 10 000 mots丨Déconstruire la chaîne industrielle de la sécurité de l'IA, les solutions et les opportunités entrepreneuriales
- Dirigeant d'Audi : la pénurie de semi-conducteurs a plongé l'industrie automobile allemande dans une période de goulot d'étranglement qui durera plusieurs années
- Comment les robots collaboratifs peuvent-ils permettre la fabrication intelligente et la modernisation de l'industrie chimique quotidienne ? Écoutez ce que disent les experts
- La société d'IA de Kai-Fu Lee 'Zero One Thousand Things' open source Yi grand modèle a été accusée de plagiat LLaMA