
Maison >Périphériques technologiques >IA >Ant Group publie un nouvel algorithme capable d'accélérer l'inférence de grands modèles de 2 à 6 fois
Ant Group publie un nouvel algorithme capable d'accélérer l'inférence de grands modèles de 2 à 6 fois

- 王林avant
- 2024-01-17 21:33:05898parcourir
Récemment, Ant Group a mis en open source un ensemble de nouveaux algorithmes qui peuvent aider les grands modèles à accélérer l'inférence de 2 à 6 fois, attirant l'attention du secteur.
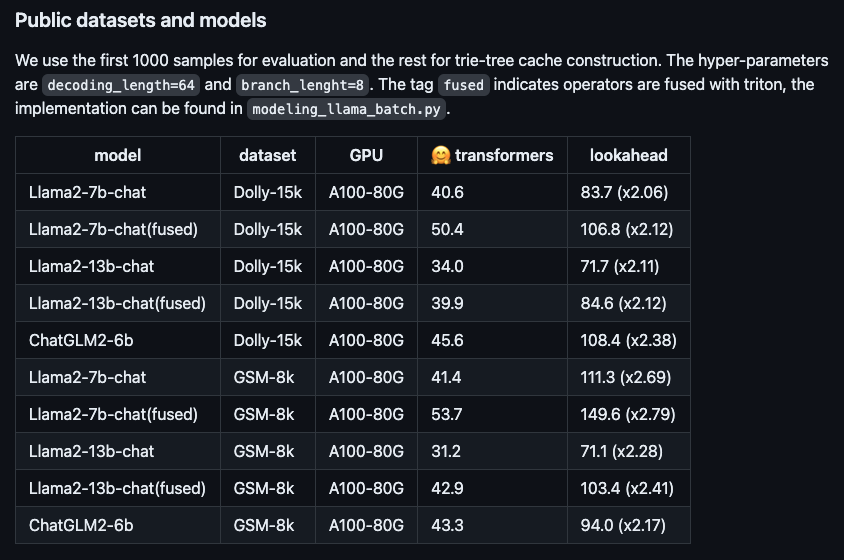
Photo : L'accélération des performances du nouvel algorithme sur différents grands modèles open source.
Ce nouvel algorithme s'appelle Lookahead Inference Acceleration Framework, qui est sans perte et plug-and-play. Cet algorithme a été implémenté dans un grand nombre de scènes de fourmis, réduisant considérablement le temps d'inférence.
En prenant comme exemples le modèle Llama2-7B-chat et l'ensemble de données Dolly, nous avons effectué des mesures réelles et constaté que la vitesse de génération de jetons est passée de 48,2/seconde à 112,9/seconde, soit une augmentation de vitesse de 2,34 fois. Sur l'ensemble de données RAG (Retrieval Enhanced Generation) interne d'Ant, le taux d'accélération de la version 10B du grand modèle Bailing AntGLM a atteint 5,36. Dans le même temps, l’augmentation de la mémoire vidéo et de la consommation de mémoire est presque négligeable.
Les modèles actuels à grande échelle sont généralement basés sur un décodage autorégressif et ne génèrent qu'un seul jeton à la fois. Cette méthode gaspille non seulement la puissance de traitement parallèle du GPU, mais entraîne également des retards excessifs dans l'expérience utilisateur, affectant la fluidité. Afin d'améliorer ce problème, vous pouvez essayer d'utiliser le décodage parallèle pour générer plusieurs jetons en même temps afin d'améliorer l'efficacité et l'expérience utilisateur.
Par exemple, le processus de génération de jetons d'origine peut être comparé à la première méthode de saisie chinoise. Les utilisateurs doivent appuyer sur le clavier mot par mot pour saisir du texte. Cependant, après avoir adopté l'algorithme d'accélération d'Ant, le processus de génération de jetons est similaire à la méthode de saisie Lenovo moderne, et la phrase entière peut être directement affichée via la fonction Lenovo. De telles améliorations améliorent considérablement la vitesse et l’efficacité de la saisie.
Certains algorithmes d'optimisation ont déjà émergé dans l'industrie, se concentrant principalement sur les méthodes permettant de générer des brouillons de meilleure qualité (c'est-à-dire deviner et générer des séquences de jetons). Cependant, il a été prouvé dans la pratique qu’une fois que la longueur du projet dépasse 30 jetons, l’efficacité du raisonnement de bout en bout ne peut plus être améliorée. Évidemment, cette longueur n’utilise pas pleinement la puissance de calcul du GPU.
Afin d'améliorer encore les performances matérielles, l'algorithme d'accélération d'inférence Ant Lookahead adopte une stratégie multi-branches. Cela signifie que la séquence de brouillon n'a plus qu'une seule branche, mais contient plusieurs branches parallèles qui peuvent être vérifiées simultanément. De cette manière, le nombre de jetons générés par un processus forward peut être augmenté tout en gardant la consommation de temps du processus forward pratiquement inchangée.
L'algorithme d'accélération d'inférence Ant Lookahead améliore encore l'efficacité du calcul en utilisant des arbres de tri pour stocker et récupérer des séquences de jetons, et en fusionnant les mêmes nœuds parents dans plusieurs brouillons. Afin d'améliorer la facilité d'utilisation, la construction d'arbres de tri de cet algorithme ne repose pas sur des projets de modèles supplémentaires, mais utilise uniquement des invites et des réponses générées pendant le processus de raisonnement pour une construction dynamique, réduisant ainsi le coût d'accès de l'utilisateur.
L'algorithme est désormais open source sur GitHub (https://www.php.cn/link/51200d29d1fc15f5a71c1dab4bb54f7c), et les articles connexes sont publiés dans ARXIV (https://www.php.cn/link/24a29a235c0678859695b10896 51 3b3d) .
Les informations publiques montrent qu'Ant Group a continué à investir dans l'intelligence artificielle sur la base de riches besoins de scénarios commerciaux et a défini des domaines techniques comprenant de grands modèles, des graphiques de connaissances, l'optimisation des opérations, l'apprentissage de graphiques et l'IA de confiance.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Où est l'adresse de la World VR Industry Conference ?
- L'intelligence artificielle donne un nouvel élan à l'industrie pharmaceutique chinoise
- La taille de l'industrie informatique de la Chine atteint 2 600 milliards de yuans, avec plus de 20,91 millions de serveurs à usage général et 820 000 serveurs d'IA livrés au cours des six dernières années.
- Les membres de la CCPPC du district de Xuhui ont organisé des activités d'inspection intensives et prêté attention au développement de l'industrie de l'intelligence artificielle.
- 360 Group a remporté le prix « China Data Intelligence Industry AI Large Model Pioneer Enterprise » basé sur 360 Intelligent Brain