
Maison >Périphériques technologiques >IA >Le potentiel des VLM open source est libéré par le framework RoboFlamingo
Le potentiel des VLM open source est libéré par le framework RoboFlamingo

- PHPzavant
- 2024-01-17 14:12:24858parcourir
Ces dernières années, la recherche sur les grands modèles s'est accélérée et a progressivement démontré une compréhension multimodale et des capacités de raisonnement temporel et spatial dans diverses tâches. Diverses tâches opérationnelles incarnées des robots nécessitent naturellement des exigences élevées en matière de compréhension des commandes linguistiques, de perception des scènes et de planification spatio-temporelle. Cela conduit naturellement à une question : les capacités des grands modèles peuvent-elles être pleinement utilisées et migrées vers le domaine de la robotique ? planifier directement la séquence d'action sous-jacente ?
ByteDance Research utilise le grand modèle de vision de langage multimodal open source OpenFlamingo pour développer un modèle de fonctionnement de robot RoboFlamingo facile à utiliser qui ne nécessite qu'une formation sur une seule machine. Le VLM peut être transformé en VLM robotique grâce à un simple réglage fin, qui convient aux tâches d'exploitation des robots d'interaction linguistique.
Vérifié par OpenFlamingo sur l'ensemble de données de fonctionnement du robot CALVIN. Les résultats expérimentaux montrent que RoboFlamingo utilise seulement 1 % des données avec annotation linguistique et atteint les performances SOTA dans une série de tâches d'exploitation du robot. Avec l'ouverture de l'ensemble de données RT-X, RoboFlamingo, qui est pré-entraîné sur des données open source et affiné pour différentes plates-formes de robots, devrait devenir un processus de modèle de robot à grande échelle simple et efficace. L'article a également testé les performances de réglage précis de VLM avec différents chefs de stratégie, différents paradigmes de formation et différentes structures Flamingo sur les tâches du robot, et est parvenu à des conclusions intéressantes.

- Page d'accueil du projet : https://roboflamingo.github.io
- Adresse du code : https://github.com/RoboFlamingo/RoboFlamingo
- Adresse papier : https://arxiv.org/abs/2311.01378
Contexte de recherche
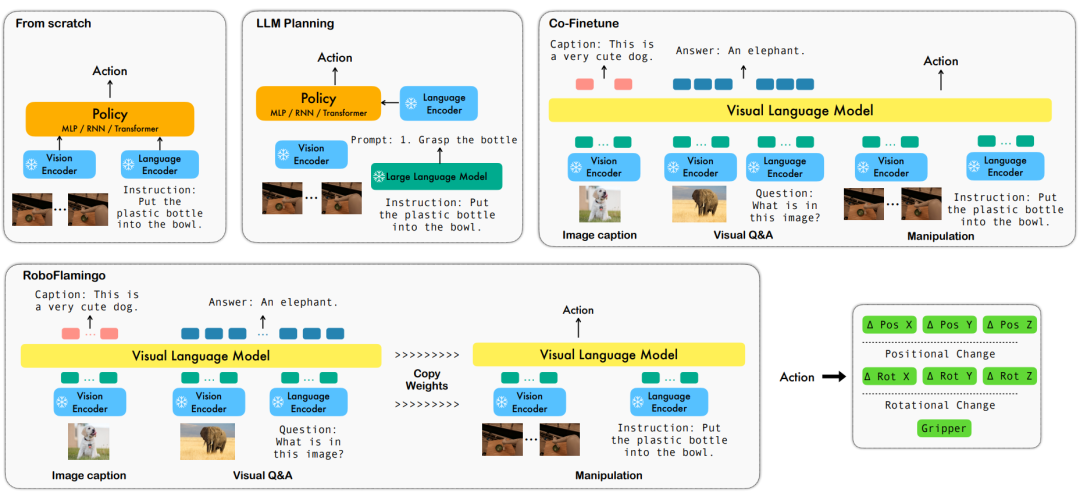
Le fonctionnement d'un robot basé sur le langage est une application importante dans le domaine de l'intelligence incorporée, impliquant des données multimodales. et le traitement, y compris la vision, le langage et le contrôle. Ces dernières années, les modèles basés sur le langage visuel (VLM) ont fait des progrès significatifs dans des domaines tels que la description d'images, la réponse visuelle aux questions et la génération d'images. Cependant, l’application de ces modèles aux opérations des robots se heurte encore à des défis, tels que la manière d’intégrer les informations visuelles et linguistiques et la manière de gérer la séquence temporelle des opérations des robots. La résolution de ces défis nécessite des améliorations dans de multiples aspects, tels que l'amélioration des capacités de représentation multimodale du modèle, la conception de mécanismes de fusion de modèles plus efficaces et l'introduction de structures et d'algorithmes de modèle qui s'adaptent à la nature séquentielle des opérations du robot. De plus, il est nécessaire de développer des ensembles de données robotiques plus riches pour former et évaluer ces modèles. Grâce à une recherche et à une innovation continues, les opérations robotisées basées sur le langage devraient jouer un rôle plus important dans les applications pratiques et fournir des services plus intelligents et plus pratiques aux humains.
Afin de résoudre ces problèmes, l'équipe de recherche en robotique de ByteDance Research a affiné le VLM (Visual Language Model) open source existant - OpenFlamingo, et a conçu un nouveau cadre de manipulation du langage visuel appelé RoboFlamingo. La caractéristique de ce cadre est qu'il utilise VLM pour parvenir à une compréhension du langage visuel en une seule étape et traite les informations historiques via un module de tête de politique supplémentaire. Grâce à des méthodes simples de réglage fin, RoboFlamingo peut être adapté aux tâches d'exploitation de robots basées sur le langage. L’introduction de ce cadre devrait résoudre une série de problèmes existants dans les opérations actuelles des robots.
RoboFlamingo a été vérifié sur l'ensemble de données de fonctionnement du robot basé sur le langage CALVIN. Les résultats expérimentaux montrent que RoboFlamingo n'utilise que 1 % des données annotées par le langage et atteint des performances SOTA (plus de 10 %) sur une série d'opérations de robot. tâches.Le taux de réussite de la séquence de tâches de l'apprentissage des tâches est de 66 %, le nombre moyen de tâches terminées est de 4,09, la méthode de base est de 38 %, le nombre moyen de tâches terminées est de 3,06 ; %, le nombre moyen de tâches terminées est de 2,48, la méthode de référence est de 1 %, le nombre moyen de tâches terminées est de 0,67), et peut obtenir une réponse en temps réel grâce à un contrôle en boucle ouverte, et peut être déployé de manière flexible sur des niveaux inférieurs. plateformes de performances. Ces résultats démontrent que RoboFlamingo est une méthode efficace de manipulation de robot et peut constituer une référence utile pour les futures applications robotiques.
Méthode
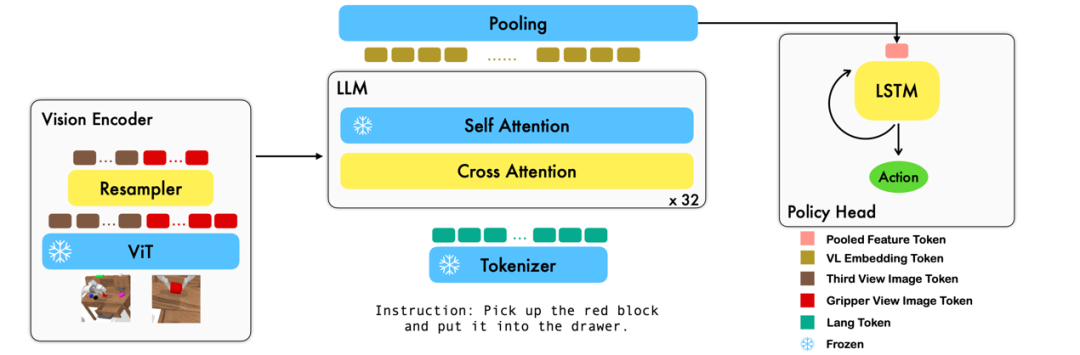
Ce travail utilise le modèle de base du langage visuel existant basé sur des paires image-texte pour générer les actions relatives de chaque étape du robot grâce à un entraînement de bout en bout. Le modèle se compose de trois modules principaux : l'encodeur de vision, le décodeur de fusion de fonctionnalités et le responsable de la politique. Dans le module d'encodeur Vision, l'observation visuelle actuelle est d'abord entrée dans ViT, puis le jeton sorti par ViT est sous-échantillonné via le ré-échantillonneur. Cette étape permet de réduire la dimension d'entrée du modèle, améliorant ainsi l'efficacité de la formation. Le module de décodeur de fusion de fonctionnalités prend des jetons de texte en entrée et utilise la sortie de l'encodeur visuel comme requête via un mécanisme d'attention croisée, réalisant ainsi la fusion des fonctionnalités visuelles et linguistiques. Dans chaque couche, le décodeur de fusion de caractéristiques effectue d'abord l'opération d'attention croisée, puis exécute l'opération d'auto-attention. Ces opérations permettent d'extraire des corrélations entre le langage et les caractéristiques visuelles pour mieux générer les actions du robot. Sur la base des séquences de jetons actuelles et historiques émises par le décodeur de fusion de fonctionnalités, le responsable de la politique génère directement les actions relatives actuelles à 7 DoF, y compris la pose d'extrémité du bras du robot à 6 dimensions et l'ouverture/fermeture de la pince à 1 dimension. Enfin, effectuez un pooling maximum sur le décodeur de fusion de fonctionnalités et envoyez-le au responsable de la politique pour générer des actions relatives. De cette manière, notre modèle est capable de fusionner efficacement les informations visuelles et linguistiques pour générer des mouvements précis du robot. Cela offre de larges perspectives d’application dans des domaines tels que le contrôle des robots et la navigation autonome.
Pendant le processus de formation, RoboFlamingo utilise les paramètres ViT, LLM et Cross Attention pré-entraînés et affine uniquement les paramètres du rééchantillonneur, de l'attention croisée et du responsable de la politique.
Résultats expérimentaux
Ensemble de données :
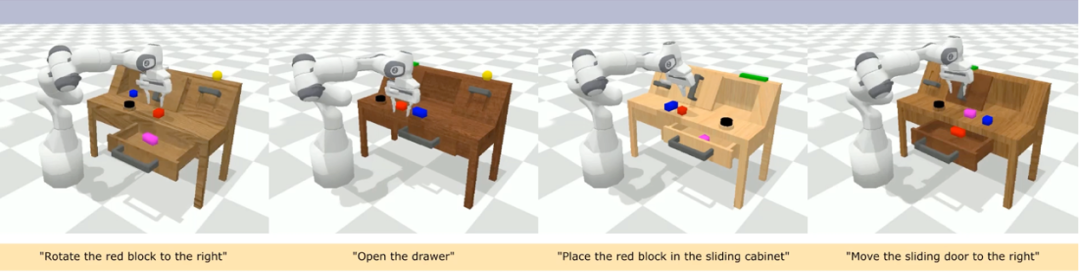
CALVIN (Composing Actions from Language and Vision) est une référence de simulation open source pour l'apprentissage de tâches opérationnelles à long horizon basées sur le langage. Par rapport aux ensembles de données de tâches visuo-linguistiques existants, les tâches de CALVIN sont plus complexes en termes de longueur de séquence, d'espace d'action et de langage, et prennent en charge une spécification flexible des entrées des capteurs. CALVIN est divisé en quatre divisions ABCD, chaque division correspond à un contexte et une disposition différents.
Analyse quantitative :
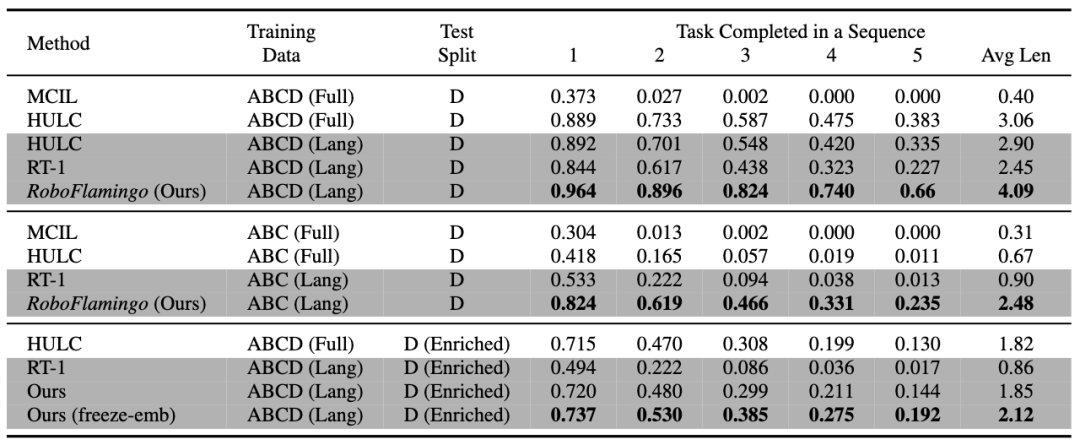
RoboFlamingo a les meilleures performances dans tous les paramètres et indicateurs, ce qui montre qu'il a une forte capacité d'imitation, une capacité de généralisation visuelle et une capacité de généralisation linguistique. Full et Lang indiquent si le modèle a été formé à l'aide de données visuelles non appariées (c'est-à-dire des données visuelles sans appariement de langues) ; Freeze-emb fait référence au gel de la couche d'intégration du décodeur fusionné ; Enriched indique l'utilisation d'instructions améliorées GPT-4 ;
Expériences d'ablation :
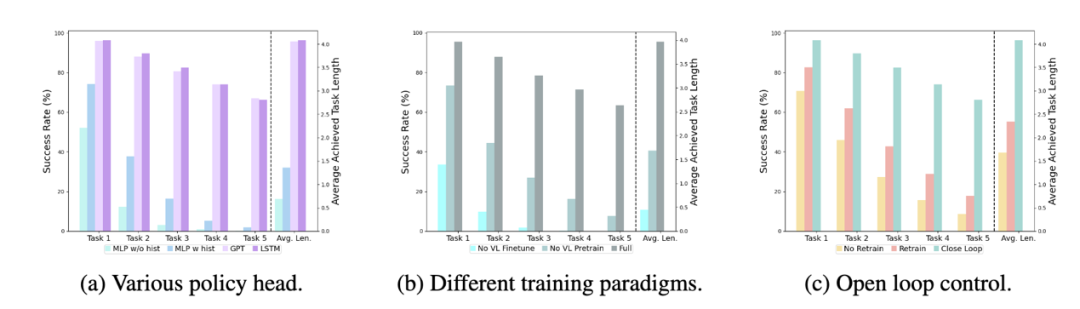
Différents chefs de politique :
Les expériences ont examiné quatre chefs de politique différents : MLP sans hist, MLP avec hist, GPT et LSTM. Parmi eux, MLP sans hist prédit directement l'historique sur la base des observations actuelles, et ses performances sont les pires avec la fusion des observations historiques du côté de l'encodeur de vision et prédit les actions, et les performances sont améliorées. au niveau du responsable politique respectivement, conserve implicitement les informations historiques et ses performances sont les meilleures, ce qui illustre l'efficacité de la fusion des informations historiques via le responsable politique.
L'impact du pré-entraînement visuel-langage :
Le pré-entraînement joue un rôle clé dans l'amélioration des performances de RoboFlamingo. Les expériences montrent que RoboFlamingo est plus performant dans les tâches robotiques grâce à un pré-entraînement sur un vaste ensemble de données visuo-linguistiques.
Taille et performances du modèle :
Alors que les modèles généralement plus grands conduisent à de meilleures performances, les résultats expérimentaux montrent que même des modèles plus petits peuvent rivaliser avec de grands modèles sur certaines tâches.
Impact du réglage fin des instructions :
Le réglage fin des instructions est une technique puissante, et les résultats expérimentaux montrent qu'elle peut encore améliorer les performances du modèle.
Résultats qualitatifs
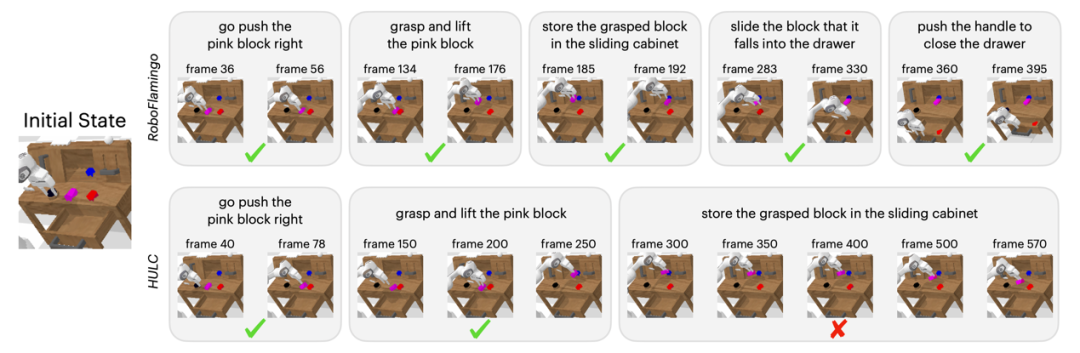
Par rapport à la méthode de base, RoboFlamingo a non seulement exécuté complètement 5 sous-tâches consécutives, mais a également pris beaucoup moins d'étapes pour les deux premières sous-tâches qui ont exécuté avec succès la page de base.
Résumé
Ce travail fournit un nouveau cadre basé sur des VLM open source existants pour les stratégies d'exploitation de robots interactifs avec un langage, qui peuvent obtenir d'excellents résultats avec de simples ajustements. RoboFlamingo fournit aux chercheurs en robotique un puissant framework open source qui peut exploiter plus facilement le potentiel des VLM open source. Les riches résultats expérimentaux de ces travaux peuvent fournir une expérience et des données précieuses pour l'application pratique de la robotique et contribuer à la recherche et au développement technologique futurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!