
Maison >Périphériques technologiques >IA >L'équipe de recherche de Xiaohongshu révèle : l'importance de vérifier les échantillons négatifs dans la distillation sur modèle à grande échelle
L'équipe de recherche de Xiaohongshu révèle : l'importance de vérifier les échantillons négatifs dans la distillation sur modèle à grande échelle

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-17 11:51:051523parcourir

Les grands modèles de langage (LLM) fonctionnent bien sur les tâches d'inférence, mais leurs propriétés de boîte noire et leur grand nombre de paramètres limitent leur application dans la pratique. Surtout lorsqu’ils traitent des problèmes mathématiques complexes, les LLM développent parfois des chaînes de raisonnement défectueuses. Les méthodes de recherche traditionnelles ne transfèrent que les connaissances issues d’échantillons positifs, ignorant les informations importantes contenant des réponses erronées dans les données synthétiques. Par conséquent, afin d’améliorer les performances et la fiabilité des LLM, nous devons considérer et utiliser les données synthétiques de manière plus complète, sans nous limiter aux échantillons positifs, pour aider les LLM à mieux comprendre et raisonner sur des problèmes complexes. Cela aidera à résoudre les défis des LLM dans la pratique et à promouvoir leur application généralisée.
Lors de l'AAAI 2024, L'équipe d'algorithmes de recherche de Xiaohongshu a proposé un cadre innovant qui utilise pleinement la connaissance des échantillons négatifs dans le processus de distillation des capacités de raisonnement de grands modèles. Les échantillons négatifs, c’est-à-dire les données qui ne parviennent pas à produire des réponses correctes au cours du processus d’inférence, sont souvent considérés comme inutiles, alors qu’ils contiennent en réalité des informations précieuses.
L'article propose et vérifie la valeur des échantillons négatifs dans le processus de distillation sur grand modèle, et construit un cadre de spécialisation du modèle : en plus d'utiliser des échantillons positifs, les échantillons négatifs sont également pleinement utilisés pour affiner les connaissances du LLM. Le cadre comprend trois étapes de sérialisation, dont Negative Assisted Training (NAT), Negative Calibration Enhancement (NCE) et Dynamic Self-Cohérence (ASC), couvrant l'ensemble du processus, de la formation à l'inférence. Grâce à une vaste série d'expériences, nous démontrons le rôle essentiel des données négatives dans la distillation des connaissances LLM.
1. Contexte
Dans la situation actuelle, guidés par la chaîne de pensée (CoT), les grands modèles de langage (LLM) ont démontré de puissantes capacités de raisonnement. Cependant, nous avons montré que cette capacité émergente ne peut être obtenue que par des modèles comportant des centaines de milliards de paramètres. Étant donné que ces modèles nécessitent d’énormes ressources informatiques et des coûts d’inférence élevés, ils sont difficiles à appliquer sous des contraintes de ressources. Par conséquent, notre objectif de recherche est de développer de petits modèles capables de raisonnement arithmétique complexe pour un déploiement à grande échelle dans des applications du monde réel.
La distillation des connaissances offre un moyen efficace de transférer les capacités spécifiques des LLM dans des modèles plus petits. Ce processus, également connu sous le nom de spécialisation des modèles, oblige les petits modèles à se concentrer sur certaines capacités. Des recherches antérieures utilisent l'apprentissage contextuel (ICL) des LLM pour générer des chemins de raisonnement pour des problèmes mathématiques et les utilisent comme données de formation, ce qui aide les petits modèles à acquérir des capacités de raisonnement complexes. Cependant, ces études n'ont utilisé que les chemins d'inférence générés avec des réponses correctes (c'est-à-dire des échantillons positifs) comme échantillons d'apprentissage, ignorant les connaissances précieuses des étapes d'inférence avec de mauvaises réponses (c'est-à-dire des échantillons négatifs). Par conséquent, les chercheurs ont commencé à explorer comment utiliser l’étape d’inférence dans des échantillons négatifs pour améliorer les performances des petits modèles. Une approche consiste à utiliser la formation contradictoire, dans laquelle un modèle générateur est introduit pour générer des chemins d'inférence pour les mauvaises réponses, et ces chemins sont ensuite utilisés avec des exemples positifs pour former un petit modèle. De cette façon, le petit modèle peut acquérir des connaissances précieuses lors de l’étape de raisonnement des erreurs et améliorer sa capacité de raisonnement. Une autre approche consiste à utiliser l'apprentissage auto-supervisé, en comparant les réponses correctes aux réponses incorrectes et en laissant un petit modèle apprendre à les distinguer et à en extraire des informations utiles. Ces méthodes peuvent fournir une formation plus complète aux petits modèles, leur donnant ainsi des capacités de raisonnement plus puissantes. En bref, l’utilisation des étapes d’inférence dans des échantillons négatifs peut aider les petits modèles à obtenir une formation plus complète et à améliorer leurs capacités d’inférence. Ce type d'image
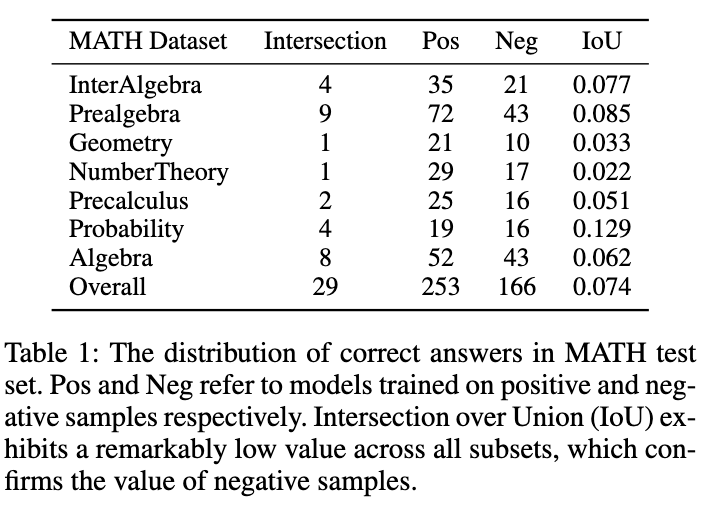
est présenté dans la figure 1. Le tableau 1 montre un phénomène intéressant : les modèles formés sur des échantillons de données positifs et négatifs ont respectivement un très faible chevauchement dans les réponses précises sur l'ensemble de tests MATH. Bien que le modèle formé avec des échantillons négatifs soit moins précis, il peut résoudre certaines questions auxquelles le modèle d'échantillon positif ne peut pas répondre correctement, ce qui confirme que les échantillons négatifs contiennent des connaissances précieuses. De plus, les liens erronés dans les échantillons négatifs peuvent aider le modèle à éviter de commettre des erreurs similaires. Une autre raison pour laquelle nous devrions tirer parti des échantillons négatifs est la stratégie de tarification basée sur les jetons d’OpenAI. Même la précision de GPT-4 sur l'ensemble de données MATH est inférieure à 50 %, ce qui signifie qu'une grande quantité de jetons sera gaspillée si seules des connaissances positives sur les échantillons sont utilisées. Par conséquent, nous proposons qu’au lieu d’éliminer directement les échantillons négatifs, un meilleur moyen consiste à en extraire et à utiliser des connaissances précieuses pour améliorer la spécialisation des petits modèles.
Le processus de spécialisation du modèle peut généralement être résumé en trois étapes :
1) Distillation de la chaîne de pensée, en utilisant la chaîne d'inférence générée par les LLM pour former un petit modèle.
2) Auto-amélioration, effectuez une auto-distillation ou une auto-expansion des données pour optimiser davantage le modèle.
3) L'auto-cohérence est largement utilisée comme stratégie de décodage efficace pour améliorer les performances du modèle dans les tâches d'inférence.
Dans ce travail, nous proposons un nouveau cadre de spécialisation de modèles capable d'exploiter pleinement les échantillons négatifs et de faciliter l'extraction de capacités d'inférence complexes à partir des LLM.
- Nous avons d'abord conçu la méthode Negative Assisted Training (NAT), dans laquelle la structure double LoRA est conçue pour acquérir des connaissances sous les aspects positifs et négatifs. En tant que module auxiliaire, la connaissance de la LoRA négative peut être intégrée de manière dynamique dans le processus de formation de la LoRA positive grâce au mécanisme d'attention corrective.
- Pour l'auto-amélioration, nous concevons Negative Calibration Enhancement (NCE), qui prend la sortie négative comme référence pour renforcer la distillation des liens clés de raisonnement avancé.
- En plus de la phase de formation, nous utilisons également des informations négatives pendant le processus d'inférence. Les méthodes traditionnelles d'autocohérence attribuent des pondérations égales ou basées sur la probabilité à tous les résultats candidats, ce qui entraîne le vote pour certaines réponses peu fiables. Afin d'atténuer ce problème, la méthode d'auto-cohérence dynamique (ASC) est proposée pour trier avant le vote, dans laquelle le modèle de tri est formé sur des échantillons positifs et négatifs.
2. Méthode
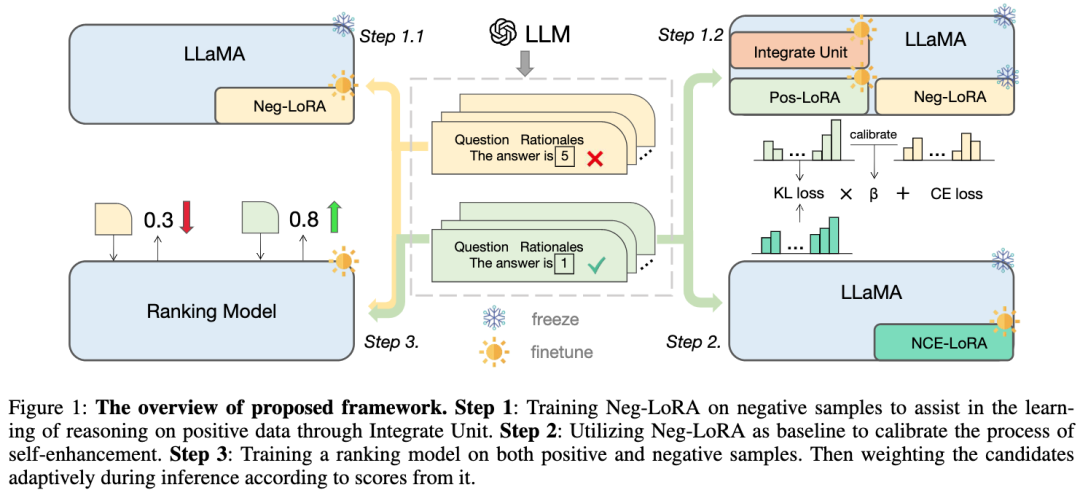
Le framework que nous avons proposé utilise LLaMA comme modèle de base et contient principalement trois parties, comme le montre la figure :
-
Étape 1 : Entraîner la LoRA négative en fusionnant L'unité aide apprendre la connaissance d'inférence des échantillons positifs
-
Étape 2 : Utiliser la LoRA négative comme base de référence pour calibrer le processus d'auto-amélioration
- ; Étape 3 : Un modèle de classement est formé sur des échantillons positifs et négatifs, et les liens d'inférence candidats sont pondérés de manière adaptative en fonction de leurs scores lors de l'inférence.
 Photos
Photos
2.1 Formation à l'assistance négative (NAT)
Nous proposons un paradigme de formation à l'assistance négative (NAT), divisé en Absorption des connaissances négatives et L'unité d'intégration dynamique comporte deux parties :
2.1.1 Absorption des connaissances négatives
En maximisant l'attente suivante sur les données négatives
, la connaissance des échantillons négatifs est absorbée par LoRA θ
. Durant ce processus, les paramètres de LLaMA restent figés.
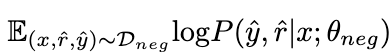 Photos
Photos
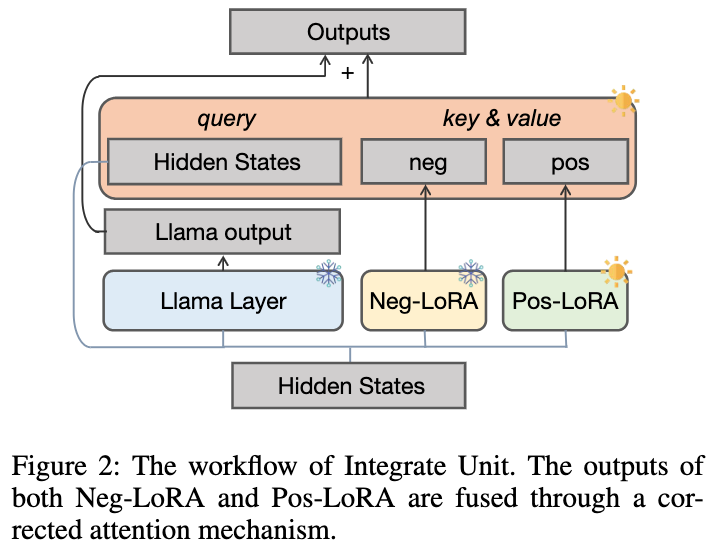
2.1.2 Unité intégrée dynamique
Comme il est impossible de déterminer à l'avance pour quels problèmes mathématiques θ
est bon, nous avons conçu une unité intégrée dynamique comme indiqué dans la figure ci-dessous pour faciliter Dans le processus d'apprentissage d'échantillons de connaissances positives, les connaissances de θ
sont intégrées dynamiquement :
 images
images
Nous gelons θ
pour empêcher les connaissances internes d'être oublié, et introduisez en plus le module LoRA positif θ . Idéalement, nous devrions intégrer en amont les modules LoRA positifs et négatifs (les sorties dans chaque couche LLaMA sont représentées par et ) pour compléter les connaissances bénéfiques qui manquent dans les échantillons positifs mais correspondant à . Lorsque θ
contient des connaissances nuisibles, nous devons effectuer une intégration négative des modules LoRA positifs et négatifs pour aider à réduire d'éventuels mauvais comportements dans les échantillons positifs.
Nous proposons un mécanisme d'attention corrective pour atteindre cet objectif comme suit :
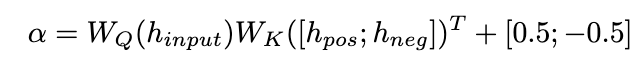 Photos
Photos
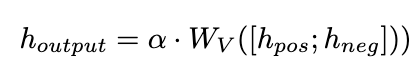 Photos
Photos
Nous utilisons
comme requête pour calculer les poids d'attention de et . En ajoutant le terme de correction [0,5 ; -0,5], le poids d'attention de est limité à la plage de [-0,5, 0,5], obtenant ainsi l'effet d'intégrer de manière adaptative les connaissances dans les directions positive et négative. Enfin, la somme de
et de la sortie de la couche LLaMA forme la sortie de l'unité d'intégration dynamique.
2.2 Amélioration de l'étalonnage négatif (NCE)
Pour améliorer davantage la capacité de raisonnement du modèle, nous proposons l'amélioration de l'étalonnage négatif (NCE), qui utilise des connaissances négatives pour faciliter le processus d'auto-amélioration. Nous utilisons d'abord NAT pour générer des paires comme échantillons d'augmentation pour chaque question et les complétons dans l'ensemble de données de formation. Pour la partie auto-distillation, nous notons que certains échantillons peuvent contenir des étapes d'inférence plus critiques, cruciales pour améliorer la capacité d'inférence du modèle. Notre objectif principal est d'identifier ces étapes d'inférence critiques et d'améliorer leur apprentissage lors de l'auto-distillation.
Considérant que NAT contient déjà des connaissances utiles sur θ
, les facteurs qui font que NAT a des capacités de raisonnement plus fortes que θ
sont implicites dans les liens de raisonnement incohérents entre les deux. Par conséquent, nous utilisons la divergence KL pour mesurer cette incohérence et maximiser l'attente de cette formule :
Plus la valeur β est grande , plus la différence entre les deux est grande, cela signifie que l'échantillon contient des connaissances plus critiques. En introduisant β pour ajuster le poids de perte de différents échantillons, NCE sera en mesure d'apprendre et d'améliorer de manière sélective les connaissances intégrées dans NAT.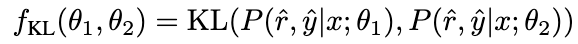 2.3 Auto-cohérence dynamique (ASC)
2.3 Auto-cohérence dynamique (ASC)
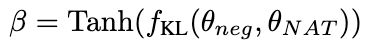 L'auto-cohérence (SC) est efficace pour améliorer encore les performances du modèle dans un raisonnement complexe. Cependant, les méthodes actuelles attribuent des poids égaux à chaque candidat ou attribuent simplement des poids basés sur les probabilités de génération. Ces stratégies ne peuvent pas ajuster les pondérations des candidats en fonction de la qualité de (rˆ, yˆ) pendant la phase de vote, ce qui peut rendre difficile la sélection du bon candidat. À cette fin, nous proposons la méthode d'auto-cohérence dynamique (ASC), qui utilise des données positives et négatives pour former un modèle de classement et peut repondérer de manière adaptative les liens d'inférence candidats.
L'auto-cohérence (SC) est efficace pour améliorer encore les performances du modèle dans un raisonnement complexe. Cependant, les méthodes actuelles attribuent des poids égaux à chaque candidat ou attribuent simplement des poids basés sur les probabilités de génération. Ces stratégies ne peuvent pas ajuster les pondérations des candidats en fonction de la qualité de (rˆ, yˆ) pendant la phase de vote, ce qui peut rendre difficile la sélection du bon candidat. À cette fin, nous proposons la méthode d'auto-cohérence dynamique (ASC), qui utilise des données positives et négatives pour former un modèle de classement et peut repondérer de manière adaptative les liens d'inférence candidats.
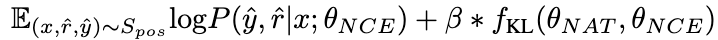 2.3.1 Formation du modèle de classement
2.3.1 Formation du modèle de classement
Idéalement, nous voulons que le modèle de classement attribue des poids plus élevés aux liens d'inférence qui mènent à la bonne réponse, et vice versa. Par conséquent, nous construisons les échantillons d'entraînement de la manière suivante :
images
et utilisons la perte MSE pour entraîner le modèle de classement :
images
2.3.2 Stratégie de pondération
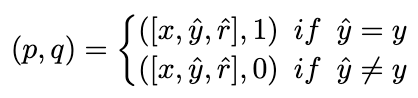
Picture 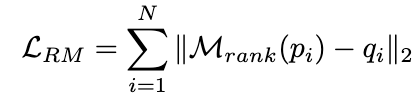
Picture
Du point de vue du transfert de connaissances, ASC met en œuvre une utilisation plus poussée des connaissances (positives et négatives) des LLM pour aider les petits modèles à obtenir de meilleures performances.
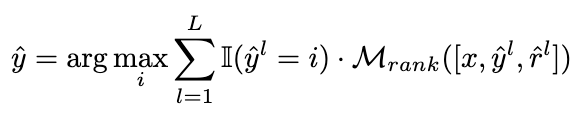 3. Expérience
3. Expérience
Pour le modèle enseignant, nous utilisons les API gpt-3.5-turbo et gpt-4 d'Open AI pour générer la chaîne d'inférence. Pour le modèle étudiant, nous choisissons LLaMA-7b. Il existe deux principaux types de lignes de base dans notre recherche : l'une est constituée de grands modèles de langage (LLM) et l'autre est basée sur LLaMA-7b. Pour les LLM, nous les comparons à deux modèles populaires : GPT3 et PaLM. Pour LLaMA-7b, nous présentons d'abord notre méthode de comparaison avec trois paramètres : Few-shot, Fine-tune (sur des échantillons d'entraînement originaux), CoT KD (Chain of Thought Distillation). En termes d'apprentissage du point de vue négatif, quatre méthodes de base seront également incluses : MIX (entraînement LLaMA directement avec un mélange de données positives et négatives), CL (apprentissage contrasté), NT (entraînement négatif) et UL (perte sans probabilité). ) ). Toutes les méthodes utilisent une recherche gourmande (c'est-à-dire température = 0), et les résultats expérimentaux de NAT sont présentés dans la figure, montrant que la méthode NAT proposée améliore la tâche sur toutes les précisions de base. Comme le montrent les faibles valeurs de GPT3 et PaLM, MATH est un ensemble de données mathématiques très difficile, mais NAT est toujours capable de bien fonctionner avec très peu de paramètres. Par rapport au réglage fin des données brutes, NAT permet d'obtenir une amélioration d'environ 75,75 % sous deux sources CoT différentes. NAT améliore également considérablement la précision par rapport au CoT KD sur les échantillons positifs, démontrant ainsi la valeur des échantillons négatifs. Pour l'utilisation de bases d'informations négatives, les faibles performances de MIX indiquent que la formation directe d'échantillons négatifs entraînera de mauvaises performances du modèle. Les autres méthodes sont également pour la plupart inférieures au NAT, ce qui montre que l’utilisation uniquement d’échantillons négatifs dans le sens négatif n’est pas suffisante dans les tâches de raisonnement complexes. Comme le montre la figure, par rapport à la distillation des connaissances (KD), NCE atteint une amélioration moyenne de 10 % (0,66), ce qui prouve l'utilisation de résultats négatifs échantillons Validité des informations d’étalonnage fournies pour la distillation. Par rapport au NAT, bien que NCE réduise certains paramètres, il présente toujours une amélioration de 6,5 %, atteignant ainsi l'objectif de compresser le modèle et d'améliorer les performances. Pour évaluer l'ASC, nous le comparons avec le SC de base et le SC pondéré (WS), en utilisant la température d'échantillonnage T = 1, générant 16 échantillons. Comme le montre la figure, les résultats montrent que l’agrégation par ASC des réponses de différents échantillons est une stratégie plus prometteuse. En plus de l'ensemble de données MATH, nous avons évalué la capacité de généralisation du cadre sur d'autres tâches de raisonnement mathématique. Les résultats expérimentaux sont les suivants. Ce travail explore l'efficacité de l'utilisation d'échantillons négatifs pour extraire des capacités de raisonnement complexes de grands modèles de langage et les transférer vers de petits modèles spécialisés. L'équipe d'algorithmes de recherche de Xiaohongshu a proposé un tout nouveau cadre, qui se compose de trois étapes de sérialisation et utilise pleinement les informations négatives tout au long du processus de spécialisation du modèle. La Negative Assistance Training (NAT) peut fournir un moyen plus complet d'utiliser les informations négatives sous deux angles. Negative Calibration Enhancement (NCE) est capable de calibrer le processus d'auto-distillation afin qu'il puisse maîtriser les connaissances clés de manière plus ciblée. Un modèle de classement formé sur les deux points de vue peut attribuer des pondérations plus appropriées pour répondre à l'agrégation afin d'obtenir une « auto-cohérence dynamique (ASC) . Des expériences approfondies montrent que notre cadre peut améliorer l'efficacité du raffinement des capacités de raisonnement grâce aux échantillons négatifs générés. Adresse papier : https://www.php.cn/link/8fa2a95ee83cd1633cfd64f78e856bd33.1 Résultats expérimentaux NAT
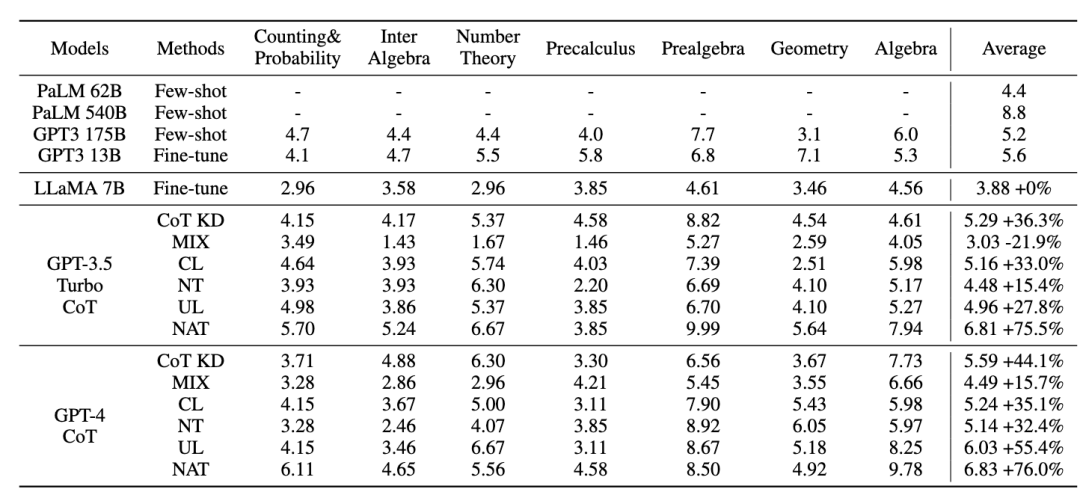 Photos
Photos3.2 Résultats expérimentaux NCE
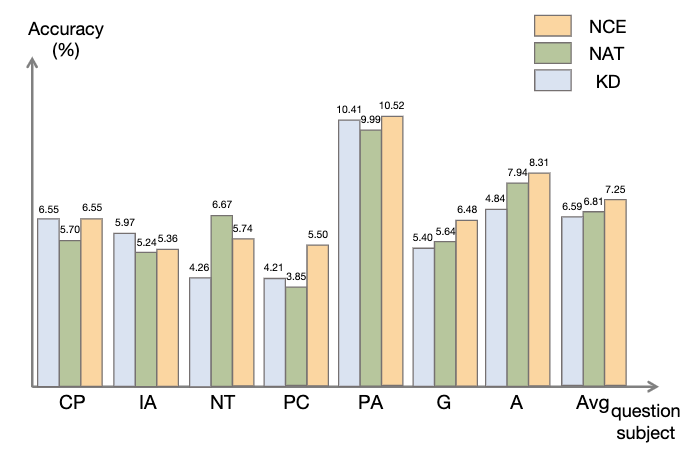 Photos
Photos3.3 Résultats expérimentaux ASC
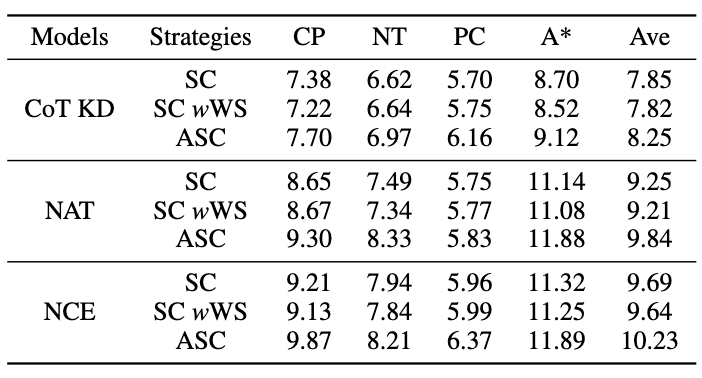 Photos
Photos3.4 Résultats expérimentaux de généralisation
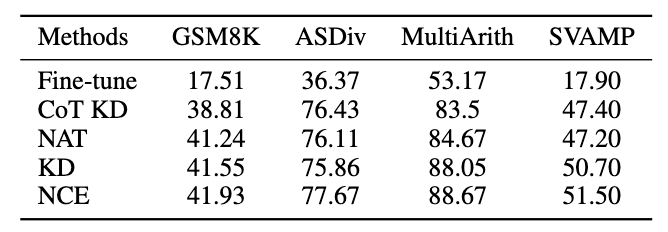 Images
Images 4. Conclusion
5. Introduction à l'auteur
Maintenant doctorant à l'Institut de technologie de Pékin, stagiaire en recherche communautaire à Xiaohongshu, travaillant dans AAAI, ACL, EMNLP, NAACL, NeurIPS, KBS A publié plusieurs articles dans des conférences/revues de premier plan dans les domaines de l'apprentissage automatique et du traitement du langage naturel. Ses principaux axes de recherche sont la distillation et l'inférence de grands modèles de langage, la génération de dialogues en domaine ouvert, etc.
Maintenant doctorant à l'Institut de technologie de Pékin, stagiaire en recherche communautaire Xiaohongshu, a publié de nombreux articles de premier auteur dans NeurIPS, AAAI, etc., et a remporté DSTC11 Piste 4 Deuxième place. La principale direction de recherche est l’inférence et l’évaluation de grands modèles linguistiques.
Responsable du rappel des vecteurs de recherche de la communauté Xiaohongshu. A publié plusieurs articles dans des conférences/revues de premier plan dans les domaines de l'apprentissage automatique et du traitement du langage naturel telles que AAAI, EMNLP, ACL, NAACL, KBS, etc.
Daoxuan (Pan Boyuan) :
Responsable de la recherche de transactions à Xiaohongshu. Il a publié plusieurs articles de premier auteur lors de conférences de premier plan dans le domaine de l'apprentissage automatique et du traitement du langage naturel telles que NeurIPS, ICML et ACL, a remporté la deuxième place du classement SQuAD du Stanford Machine Reading Competition et la première place du Stanford Natural. Classement d'inférence linguistique.
Zeng Shushu (Zeng Shushu) :
Responsable de la compréhension et du rappel sémantiques de recherche dans la communauté Xiaohongshu. Il est diplômé d'une maîtrise du Département d'électronique de l'Université Tsinghua et a travaillé sur des algorithmes dans le traitement du langage naturel, la recommandation, la recherche et d'autres domaines connexes dans le domaine d'Internet.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI