
Maison >Périphériques technologiques >IA >Point Transformer mis à jour : plus efficace, plus rapide et plus puissant !
Point Transformer mis à jour : plus efficace, plus rapide et plus puissant !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-17 08:27:051274parcourir
Titre original : Point Transformer V3 : Simpler, Faster, Stronger
Lien papier : https://arxiv.org/pdf/2312.10035.pdf
Lien code : https://github.com/Pointcept/PointTransformerV3
Auteur Unité : HKU SH AI Lab MPI PKU MIT
Idée de thèse :
Cet article n'a pas pour objectif de rechercher l'innovation au sein du mécanisme d'attention. Au lieu de cela, il se concentre sur l’exploitation de la puissance de l’échelle pour surmonter les compromis existants entre précision et efficacité dans le contexte du traitement des nuages de points. S'inspirant des progrès récents dans l'apprentissage des représentations 3D à grande échelle, cet article reconnaît que les performances des modèles sont davantage affectées par l'échelle que par la complexité de la conception. Par conséquent, cet article propose Point Transformer V3 (PTv3), qui donne la priorité à la simplicité et à l'efficacité plutôt qu'à la précision de certains mécanismes qui ont moins d'impact sur les performances globales après la mise à l'échelle, tels que les nuages de points organisés selon des modèles spécifiques de cartographie de quartier sérialisé pour remplacer les KNN. recherche de quartier exacte. Ce principe permet une mise à l'échelle importante, étendant le champ de réception de 16 à 1024 points, tout en restant efficace (traitement 3x plus rapide et 10x plus efficace en mémoire par rapport à son prédécesseur PTv2). PTv3 obtient des résultats de pointe sur plus de 20 tâches en aval couvrant des scénarios intérieurs et extérieurs. PTv3 fait passer ces résultats au niveau supérieur avec des améliorations supplémentaires grâce à une formation conjointe multi-ensembles de données.
Conception de réseau :
Les progrès récents dans l'apprentissage des représentations 3D [85] ont permis de surmonter les limitations d'échelle des données dans le traitement des nuages de points en introduisant des méthodes de formation collaborative sur plusieurs ensembles de données 3D. Combiné à cette stratégie, un squelette convolutif efficace [12] comble efficacement le déficit de précision généralement associé aux transformateurs de nuages de points [38, 84]. Cependant, les transformateurs de nuages de points eux-mêmes n’ont pas encore pleinement bénéficié de cet avantage d’échelle en raison de l’écart d’efficacité des transformateurs de nuages de points par rapport aux convolutions clairsemées. Cette découverte a façonné la motivation initiale de ce travail : réévaluer les choix de conception des transformateurs ponctuels du point de vue du principe de mise à l'échelle. Cet article estime que les performances du modèle sont affectées de manière plus significative par l'échelle que par la conception complexe.
Par conséquent, cet article présente Point Transformer V3 (PTv3), qui privilégie la simplicité et l'efficacité plutôt que la précision de certains mécanismes pour atteindre l'évolutivité. De tels ajustements ont un impact négligeable sur les performances globales après la mise à l'échelle. Plus précisément, PTv3 a apporté les ajustements suivants pour atteindre une efficacité et une évolutivité supérieures :
- Inspiré par deux avancées récentes [48, 77] et reconnaissant les avantages d'évolutivité des nuages de points structurés non structurés, PTv3 a modifié la proximité spatiale traditionnelle définie par le K-Nearest Les requêtes Neighbours (KNN) représentent 28 % du temps de transfert. Au lieu de cela, il explore le potentiel des quartiers sérialisés dans des nuages de points organisés selon des modèles spécifiques.
- PTv3 adopte une approche simplifiée spécifiquement adaptée aux nuages de points sérialisés, remplaçant les mécanismes d'interaction des patchs d'attention plus complexes tels que le décalage de fenêtre (qui entrave la fusion des opérateurs d'attention) et les mécanismes de voisinage (entraînant une consommation élevée de mémoire).
- PTv3 élimine la dépendance à l'encodage de position relative, qui représente 26 % du temps de transmission, au profit de couches convolutives frontales clairsemées plus simples.
Cet article considère ces conceptions comme des choix intuitifs motivés par les principes de mise à l'échelle et les avancées des transformateurs de nuages de points existants. Surtout, cet article souligne l’importance cruciale de comprendre comment l’évolutivité affecte la conception du backbone, plutôt que la conception détaillée des modules.
Ce principe améliore considérablement l'évolutivité, surmontant le compromis traditionnel entre précision et efficacité (voir Figure 1). PTv3 offre une inférence 3,3 fois plus rapide et une utilisation de la mémoire 10,2 fois inférieure à celle de son prédécesseur. Plus important encore, PTv3 exploite sa capacité inhérente à adapter la portée de détection, étendant son champ de réception de 16 à 1 024 points tout en maintenant son efficacité. Cette évolutivité sous-tend ses performances supérieures dans les tâches de perception du monde réel, PTv3 obtenant des résultats de pointe sur plus de 20 tâches en aval dans des scénarios intérieurs et extérieurs. PTv3 améliore encore ces résultats en augmentant encore la taille de ses données grâce à un entraînement multi-ensembles de données [85]. Nous espérons que les idées de cet article inspireront de futures recherches dans cette direction.
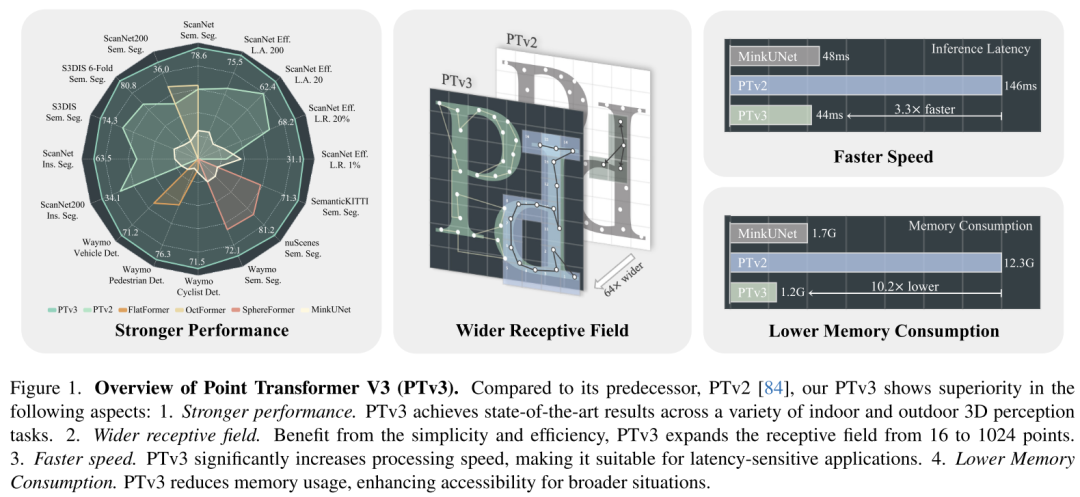
Figure 1. Présentation du Point Transformer V3 (PTv3). Comparé à son prédécesseur PTv2 [84], PTv3 dans cet article montre une supériorité dans les aspects suivants : 1. Des performances plus fortes. PTv3 obtient des résultats de pointe sur une variété de tâches de perception 3D intérieures et extérieures. 2. Champ de réception plus large. Bénéficiant de simplicité et d'efficacité, PTv3 étend le champ réceptif de 16 à 1024 points. 3. Plus vite. PTv3 augmente considérablement la vitesse de traitement, ce qui le rend adapté aux applications sensibles à la latence. 4. Réduisez la consommation de mémoire. PTv3 réduit l'utilisation de la mémoire et améliore l'accessibilité dans un plus large éventail de situations.
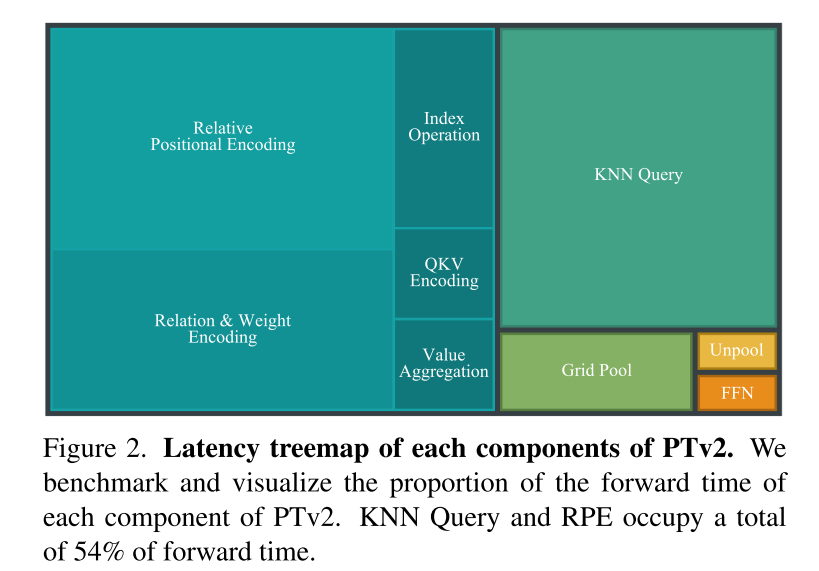
Figure 2. Diagramme d'arbre de retard de chaque composant de PTv2. Cet article compare et visualise le rapport de temps de transfert de chaque composant de PTv2. KNN Query et RPE occupent un total de 54 % du temps de transfert.

Figure 3. Sérialisation des nuages de points. Cet article présente quatre modèles de sérialisation via la visualisation triplet. Pour chaque triplet, la courbe de remplissage d'espace pour la sérialisation (à gauche), l'ordre de tri des variables de sérialisation du nuage de points dans la courbe de remplissage d'espace (au milieu) et les correctifs groupés du nuage de points sérialisé pour une attention locale sont affichés (à droite). La transformation des quatre modes de sérialisation permet au mécanisme d'attention de capturer diverses relations et contextes spatiaux, améliorant ainsi la précision du modèle et la capacité de généralisation.
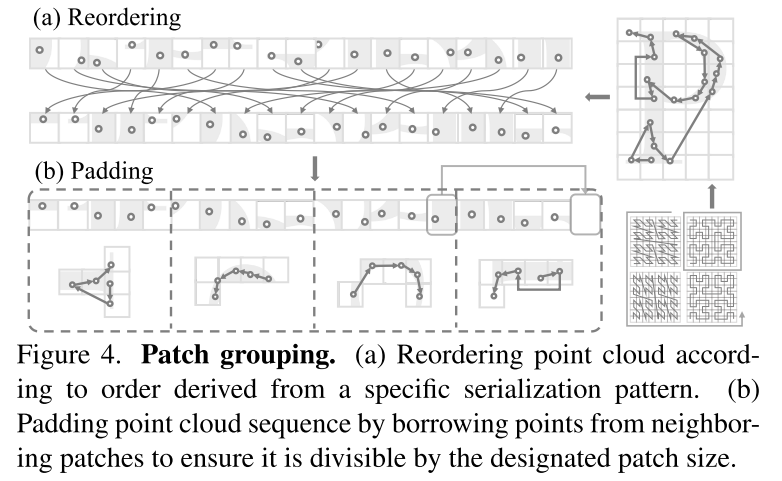
Figure 4. Regroupement des patchs. (a) Réorganisation des nuages de points selon un ordre dérivé d'un schéma de sérialisation spécifique. (b) Remplissez la séquence de nuages de points en empruntant des points à des patchs adjacents pour vous assurer qu'elle est divisible par la taille de patch spécifiée.
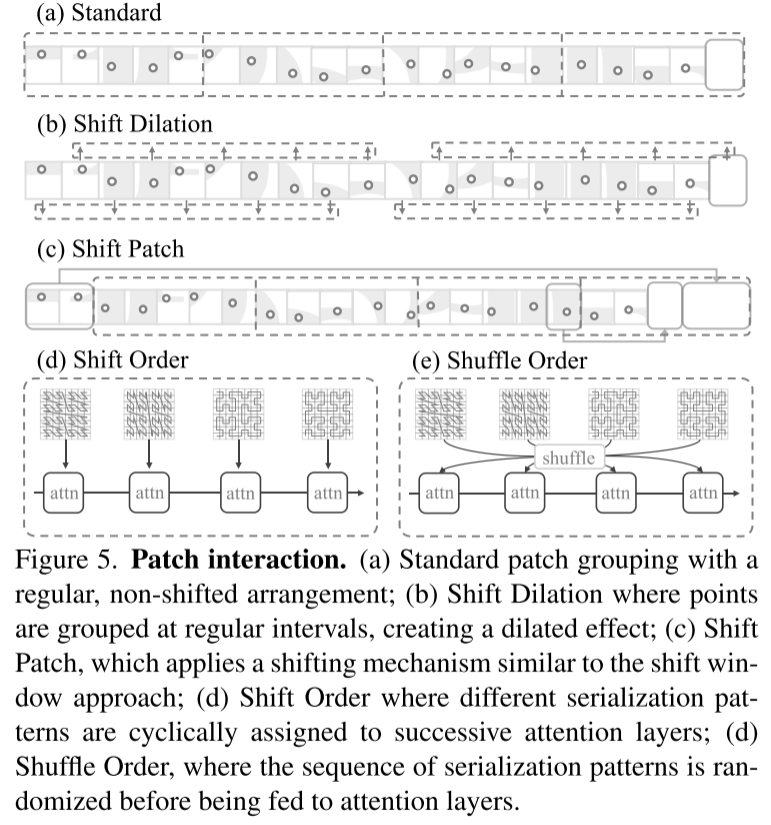
Figure 5. Interaction des correctifs. (a) Regroupement de patchs standard, avec une disposition régulière et non décalée ; (b) Expansion de translation, dans laquelle les points sont agrégés à intervalles réguliers pour produire un effet d'expansion (c) Shift Patch, qui utilise un mécanisme de décalage similaire au ; méthode de fenêtre de décalage ; (d) Shift Order, dans lequel différents modèles de sérialisation sont attribués de manière cyclique aux couches d'attention successives ; (d) Shuffle Order, dans lequel la séquence de modèles de sérialisation est randomisée avant d'être entrée dans la couche d'attention ;
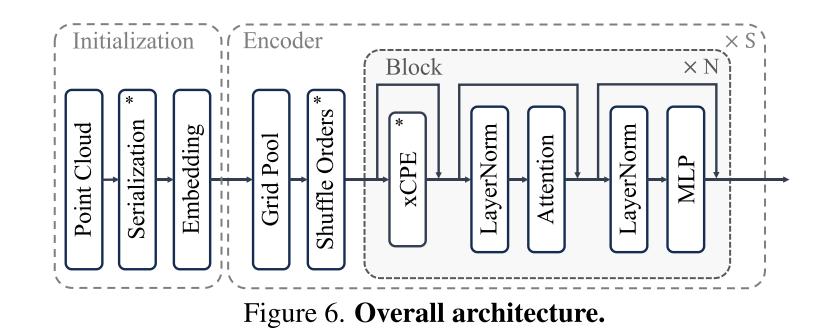
Figure 6. Architecture globale.
Résultats expérimentaux :
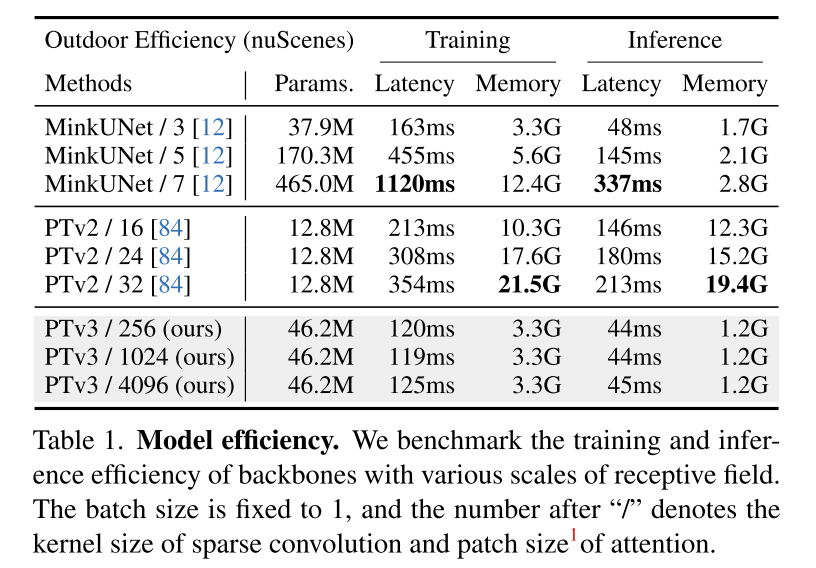
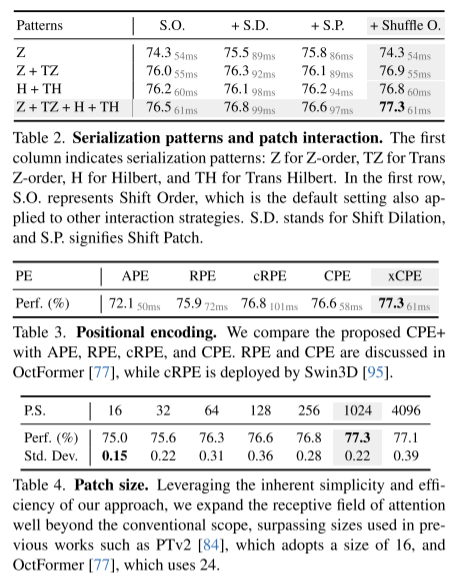
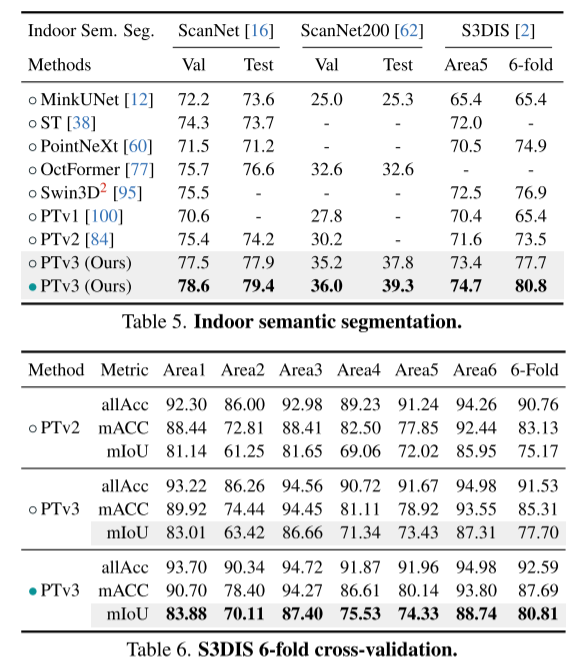
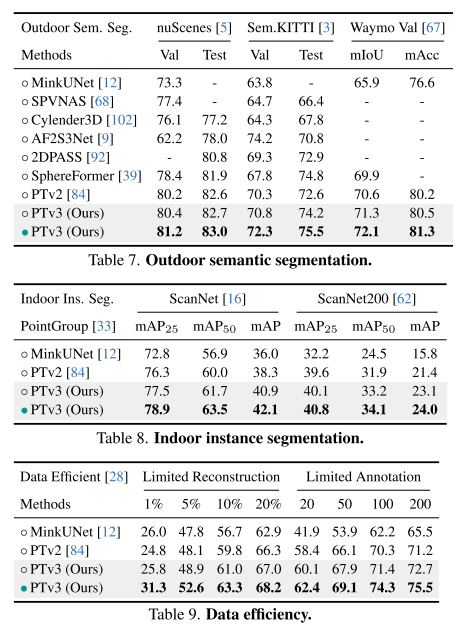
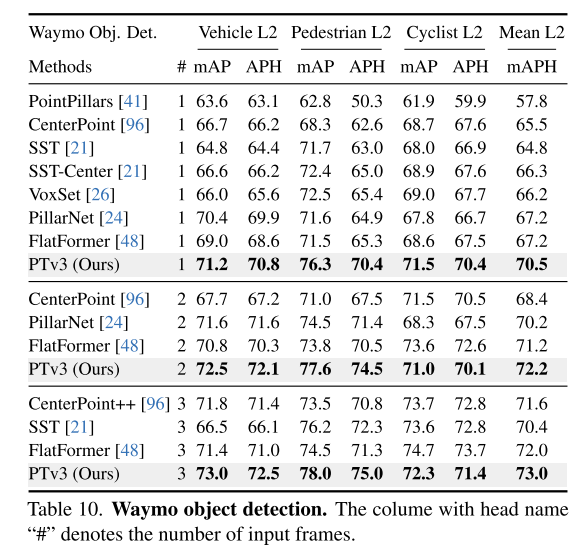
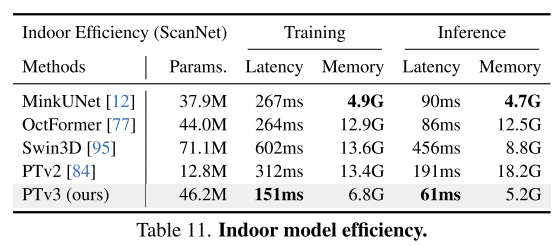
Résumé :
Cet article présente Point Transform er V3, qui vise à améliorer la précision du traitement des nuages de points. Un grand pas en avant par rapport au compromis traditionnel entre efficacité et efficience. Guidé par une nouvelle interprétation du principe de mise à l'échelle dans la conception du backbone, cet article soutient que les performances du modèle sont plus profondément affectées par l'échelle que par la complexité de la conception. En donnant la priorité à l’efficacité plutôt qu’à la précision des mécanismes d’impact plus petits, cet article exploite le pouvoir de l’échelle, améliorant ainsi les performances. En bref, cet article peut rendre un modèle plus puissant en le rendant plus simple et plus rapide.
Citation :
Wu, X., Jiang, L., Wang, P., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T. et Zhao , H. (2023). Point Transformer V3 : Plus simple, plus rapide, plus fort. /abs/2312.10035

.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La formation ViT et MAE réduit la quantité de calcul de moitié ! Sea et l'Université de Pékin ont proposé conjointement l'optimiseur efficace Adan, qui peut être utilisé pour les modèles profonds
- Analyse des principes d'accélération de la formation en IA et partage des pratiques d'ingénierie
- Les programmeurs sont en danger ! On dit qu'OpenAI recrute des troupes d'externalisation dans le monde entier et forme étape par étape les agriculteurs de code ChatGPT.
- NUS et Byte ont collaboré de manière intersectorielle pour obtenir une formation 72 fois plus rapide grâce à l'optimisation des modèles, et ont remporté le prix AAAI2023 Outstanding Paper.
- QTNet : Nouvelle solution de fusion temporelle pour nuages de points, images et détecteurs multimodaux (NeurIPS 2023)