
Maison >Tutoriel système >Linux >Un problème qui me préoccupe depuis six mois
Un problème qui me préoccupe depuis six mois

- PHPzavant
- 2024-01-16 23:33:181469parcourir
Cet article présentera une panne difficile dans un environnement de virtualisation qui trouble l'auteur depuis près de six mois. La cause finale de la panne et la méthode de réparation sont également ridicules. Non pas parce que ce processus est compliqué, mais pour partager un processus psychologique, réfléchir à la manière d'équilibrer les affaires et la technologie en cas d'échec et à utiliser correctement les moteurs de recherche.
Phénomène de défautNous disposons d'un cluster proxy hautes performances qui a fonctionné de manière stable pendant la phase de test interne. Cependant, moins d'un demi-mois après son lancement officiel, les hôtes qui fournissent des services proxy se sont soudainement écrasés les uns après les autres, provoquant la panne de tous les services sur les hôtes. être interrompu.
Analyse des défautsLorsqu'un défaut survient, l'hôte plante directement et ne peut pas se connecter à distance. La salle informatique répond à la saisie au clavier sur place. Étant donné que le syslog hôte a été connecté à ELK, nous avons collecté divers syslogs avant et après le crash.
Journal des erreursEn vérifiant le journal système de l'hôte en panne, j'ai découvert que l'erreur de noyau suivante avait été signalée avant le crash de la machine :
Nov 12 15:06:31 hello-worldkernel: [6373724.634681] BUG: unable to handle kernel NULL pointer dereferenceat 0000000000000078 Nov 12 15:06:31 hello-world kernel: [6373724.634718] IP: []pick_next_task_fair+0x6b8/0x820 Nov 12 15:06:31 hello-world kernel: [6373724.634749] PGD 10561e4067 PUDffdb46067 PMD 0 Nov 12 15:06:31 hello-world kernel: [6373724.634780] Oops: 0000 [#1] SMP
Cela montre que l'accès au pointeur nul du noyau déclenche un bug système, qui provoque ensuite une série d'erreurs de pile d'appels et finalement des plantages.
Afin d'analyser plus en détail le phénomène de panne, vous devez d'abord comprendre l'architecture de ce cluster proxy hautes performances.
Introduction à l'architecture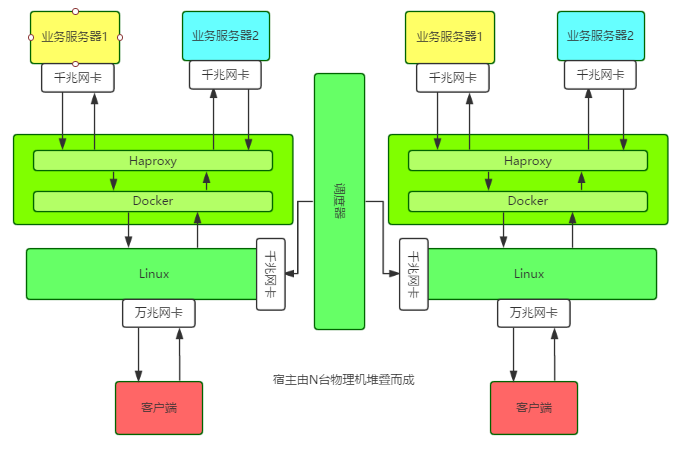
Un seul nœud exécute un conteneur Docker sur un hôte doté d'une carte réseau 10G, puis exécute une instance Haproxy dans le conteneur. Les informations de configuration et les informations commerciales de chaque nœud et instance sont hébergées sur le planificateur.
La particularité est que l'hôte utilise Linux Bridge pour configurer directement l'adresse IP du conteneur Docker. Toutes les adresses IP des services externes, y compris l'adresse IP du réseau externe de l'hôte, sont liées au pont Linux.
Présentation de la candidatureLe système d'exploitation, le matériel et la version Docker de chaque hôte sont tous identiques. Le système d'exploitation et la version Docker sont les suivants :
[操作系统] System : Linux Kernel : 3.16.0-4-amd64 Version : 8.5 Arch : x86_64 [Docker版本] Docker version 1.12.1, build 6b644ecAnalyse préliminaire
La configuration hôte de ce cluster est cohérente, et les symptômes de panne sont également cohérents. Il y a trois doutes :
1. La version Docker est incompatible avec la version du noyau hôteLes environnements des trois hôtes étaient à l'origine les mêmes, mais l'un d'entre eux s'est écrasé après 2 mois d'exécution stable des services, l'un s'est écrasé pendant l'exécution des services après un mois et l'autre s'est écrasé pendant l'exécution des services en ligne en une semaine.
Il a été constaté qu'en plus du journal anormal des crashs, chaque hôte a également le même journal d'erreurs :
time=”2016-09-07T20:22:19.450573015+08:00″level=warning msg=”Your kernel does not support cgroup memory limit” time=”2016-09-07T20:22:19.450618295+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs period” time=”2016-09-07T20:22:19.450640785+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs quotas” time=”2016-09-07T20:22:19.450769672+08:00″ level=warningmsg=”mountpoint for pids not found”
Selon les conseils ci-dessus, cela devrait être dû au fait que la version du noyau du système d'exploitation ne prend pas en charge certaines fonctions pour cette version de Docker. Cependant, la recherche sur un moteur de recherche n’affecte pas les fonctionnalités de Docker ni la stabilité du système.
Par exemple :
time=”2017-01-19T18:16:30+08:00″level=error msg=”containerd: notify OOM events” error=”openmemory.oom_control: no such file or directory” time=”2017-01-19T18:22:41.368392532+08:00″level=error msg=”Handler for POST /v1.23/containers/338016c68da6/stopreturned error: No such container: 338016c68da6″
Il s'agit d'un problème qui existe depuis Docker 1.9 et qui a été corrigé dans la version 1.12.3.
Par exemple, quelqu'un sur Github a répondu :
“I have been update my docker from 1.11.2 to 1.12.3, This issue is fixed. BTW, this error message can be ignored, it should really just be a warning.”
Mais les problèmes mentionnés ici ne sont que des problèmes qui peuvent être résolus par la version v1.12.2. Après avoir mis à niveau la version Docker, nous avons constaté que le crash était toujours le même.
Nous avons donc confirmé de nombreux problèmes avec le même phénomène de panne que le nôtre via différents Google, et avons dans un premier temps confirmé la corrélation entre la panne et Docker. Sur la base du problème officiel, nous avons également initialement confirmé que la version Docker est incompatible avec le noyau du système. version et peut entraîner des temps d'arrêt ; puis, via le journal des modifications et le problème officiels, nous avons confirmé que la version de Docker utilisée par l'hôte est incompatible avec la version du noyau du système, nous avons mis à niveau la version de Docker vers 1.12.2. , mais l'accident s'est quand même produit sans aucun accident.
2. L'utilisation de la méthode du pont Linux pour modifier la carte réseau hôte peut déclencher des bugsJ'ai trouvé un hôte qui s'est écrasé après avoir exécuté le service pendant une semaine, a arrêté d'exécuter Docker et n'a modifié le réseau qu'il a fonctionné de manière stable pendant une semaine et aucune anomalie n'a été trouvée.
3. L'utilisation de canalisations pour configurer l'IP des conteneurs Docker peut déclencher des bugsDepuis que nous avons utilisé le script de tuyauterie open source lors de l'attribution d'adresses IP aux conteneurs, nous soupçonnions qu'il y avait un bug dans le principe de fonctionnement de la tuyauterie, nous avons donc essayé d'attribuer des adresses IP sans utiliser de tuyauterie et avons constaté que l'hôte plantait toujours.
Le dépannage initial était donc problématique, et c'était très frustrant de voir l'hôte planter au moins une fois par mois.
故障定位因为还有线上业务在跑,所以没有贸然升级所有宿主内核,而是期望能通过升级Docker或者其它热更新的方式修复问题。但是不断的尝试并没有带来理想中的效果。
直到有一天,在跟一位对Linux内核颇有研究的老司机聊起这个问题时,他三下五除二,Google到了几篇文章,然后提醒我们如果是这个 bug,那是在 Linux 3.18 内核才能修复的。
原因:从sched: Fix race between task_group and sched_task_group的解析来看,就是parent 进程改变了它的task_group,还没调用cgroup_post_fork()去同步给child,然后child还去访问原来的cgroup就会null。
不过这个问题发生在比较低版本的Docker,基本是Docker 1.9以下,而我们用的是Docker1.11.1/1.12.1。所以尽管报错现象比较相似,但我们还是没有100%把握。
但是,这个提醒却给我们打开了思路:去看内核代码,实在不行就下掉所有业务,然后全部升级操作系统内核,保持一个月观察期。
于是,我们开始啃Linux内核代码之路。先查看操作系统本地是否有源码,没有的话需要去Linux kernel官方网站搜索。
下载了源码包后,根据报错syslog的内容进行关键字匹配,发现了以下内容。由于我们的机器是x86_64架构,所以那些avr32/m32r之类的可以跳过不看。结果看下来,完全没有可用信息。
/kernel/linux-3.16.39#grep -nri “unable to handle kernel NULL pointer dereference” * arch/tile/mm/fault.c:530: pr_alert(“Unable to handlekernel NULL pointer dereference/n”); arch/sparc/kernel/unaligned_32.c:221: printk(KERN_ALERT “Unable to handle kernel NULL pointerdereference in mna handler”); arch/sparc/mm/fault_32.c:44: “Unable to handle kernel NULL pointer dereference/n”); arch/m68k/mm/fault.c:47: pr_alert(“Unable tohandle kernel NULL pointer dereference”); arch/ia64/mm/fault.c:292: printk(KERN_ALERT “Unable tohandle kernel NULL pointer dereference (address %016lx)/n”, address); debian/patches/bugfix/all/mpi-fix-null-ptr-dereference-in-mpi_powm-ver-3.patch:20:BUG:unable to handle kernel NULL pointer dereference at (null)
最后,我们还是下线了所有业务,将操作系统内核和Docker版本全部升级到最新版。这个过程有些艰难,当初推广这个系统时拉的广告历历在目,现在下线业务,回炉重造,挺考验勇气和决心的。
故障处理下面是整个故障处理过程中,我们进行的一些操作。
升级操作系统内核对于Docker 1.11.1与内核4.9不兼容的问题,可以删除原有的Docker配置,然后使用官方脚本重新安装最新版本Docker
/proxy/bin#ls /var/lib/dpkg/info/docker-engine. docker-engine.conffiles docker-engine.md5sums docker-engine.postrm docker-engine.prerm docker-engine.list docker-engine.postinst docker-engine.preinst #Getthe latest Docker package. $curl -fsSL https://get.docker.com/ | sh #启动 nohupdocker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock-s=devicemapper&
这里需要注意的是,Docker安装方式在不同操作系统版本上不尽相同,甚至相同发行版上也有不同,比如原来我们使用以下方式安装Docker:
apt-get install docker-engine
然后在早些时候,还有使用下面的安装方式:
apt-get install lxc-docker
可能是基于原来安装方式的千奇百怪导致问题丛出,所以Docker官方提供了一个脚本用于适配不同系统、不同发行版本Docker安装的问题,这也是一个比较奇怪的地方,所以Docker生态还是蛮乱的。
验证16:44:15 up 28 days, 23:41, 2 users, load average: 0.10, 0.13, 0.15 docker 30320 1 0 Jan11 ? 00:49:56 /usr/bin/docker daemon -p/var/run/docker.pid
Docker内核升级到1.19,Linux内核升级到3.19后,保持运行至今已经2个月多了,都是ok的。
总结这个故障的处理时间跨度很大,都快半年了,想起今年除夕夜收到服务器死机报警的情景,心里像打破五味瓶一样五味杂陈。期间问过不少研究Docker和操作系统内核的同事,往操作系统内核版本等各个方向进行了测试,但总与正确答案背道而驰或差那么一点点。最后发现原来是处理得不够彻底,比如升级不彻底,环境被污染;比如升级的版本不够新,填的坑不够厚。回顾了整个故障处理过程,总结下来大概如下:
回归运维的本质运维要具有预见性、长期规划,而不能仅仅满足于眼前:
- Plan d'urgence : résumez les types de pannes qui peuvent survenir après la mise en ligne du système et fournissez un plan d'urgence.
- Construire le service : donner la priorité au service, puis gérer le défaut.
- Problèmes de sélection techniques tels que la sélection de la version de l'application : une attention particulière doit être accordée aux différentes versions lors du déploiement de l'environnement et de la sélection des applications. Il est préférable d'utiliser des versions qui sont courantes dans la communauté ou qui ont été testées ou vérifiées comme réalisables par d'autres. étudiants dans l'entreprise.
- Noyau du système d'exploitation : pour mettre à niveau le noyau de manière raisonnable, ce n'est qu'en localisant les problèmes dans la version spécifique que la version du noyau peut être mise à niveau de manière ciblée, sinon tout sera vain.
- Dans notre conception originale, il n'y avait pas de mécanisme de verrouillage permettant à différents planificateurs d'utilisateurs d'exploiter le même conteneur en même temps, et il ne suivait pas non plus le principe du jugement source. Il y a également eu des échecs de migration. Lors de la migration, il est déterminé si l'adresse de destination à migrer est l'adresse locale. S'il s'agit d'une adresse locale, l'opération doit être rejetée. Je me demande si cette question vous semble familière. J'ai constaté que de nombreuses personnes ne parviennent souvent pas à juger la source d'entrée ou l'état de la source de l'opération pendant le développement du programme, ce qui entraîne divers bugs.
En traitant ce problème, vous constaterez que différentes personnes recherchent différentes choses en utilisant Google. Pourquoi ? Je pense que c'est là que les moteurs de recherche sont pleins de défauts, voire flexibles. Pour cette erreur, j'ai utilisé Linux Docker Impossible de gérer le déréférencement du pointeur NULL du noyau pour la recherche, mais les résultats étaient différents des autres utilisant "Impossible de gérer le déréférencement du pointeur NULL du noyau". La raison est qu'après l'ajout de "", la recherche devient plus précise. À propos de la bonne façon d'ouvrir Google.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une question d'algorithme classique provoquée par une commande Linux couramment utilisée dans les projets
- Qu'est-ce que la certification Linux ?
- Comment vérifier la version jdk dans le système Linux
- Comment utiliser la commande base64 pour crypter la commande Linux et l'exécuter
- Comment effectuer l'agrégation de journaux et les statistiques via les outils de ligne de commande Linux ?