
Maison >Périphériques technologiques >IA >Google lance l'ensemble de données BIG-Bench Mistake pour aider l'IA à améliorer ses capacités de correction d'erreurs
Google lance l'ensemble de données BIG-Bench Mistake pour aider l'IA à améliorer ses capacités de correction d'erreurs

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-16 18:57:16759parcourir
Google Research a récemment mené une étude d'évaluation sur les modèles de langage populaires, en utilisant son propre benchmark BIG-Bench et le nouvel ensemble de données « BIG-Bench Mistake ». Ils se sont principalement concentrés sur la probabilité d’erreur et la capacité de correction d’erreurs du modèle de langage. Cette étude fournit des données précieuses pour mieux comprendre les performances des modèles linguistiques sur le marché.
Les chercheurs de Google ont déclaré avoir créé un ensemble de données de référence spécial appelé « BIG-Bench Mistake » pour évaluer la « probabilité d'erreur » et la « capacité d'auto-correction » des grands modèles de langage. Cela est dû au manque d’ensembles de données correspondants dans le passé pour évaluer et tester efficacement ces indicateurs clés.
Les chercheurs ont utilisé le modèle de langage PaLM pour exécuter 5 tâches dans leur propre tâche de référence BIG-Bench, et ont ajouté la trajectoire « Chaîne de pensée » générée à la partie « Erreur logique » pour retester la précision du modèle.
Afin d'améliorer la précision de l'ensemble de données, les chercheurs de Google ont répété le processus ci-dessus et ont finalement créé un ensemble de données de référence spécifiquement pour l'évaluation, qui contenait 255 erreurs logiques, appelées « BIG-Bench Mistake ».
Les chercheurs ont souligné que les erreurs logiques dans l'ensemble de données « BIG-Bench Mistake » sont très évidentes, elles peuvent donc être utilisées comme un bon standard pour les tests de modèles de langage. Cet ensemble de données aide le modèle à apprendre d'erreurs simples et à améliorer progressivement sa capacité à identifier les erreurs.
Les chercheurs ont utilisé cet ensemble de données pour tester des modèles sur le marché et ont découvert que même si la plupart des modèles de langage peuvent identifier les erreurs logiques dans le processus de raisonnement et se corriger eux-mêmes, ce processus n'est pas très idéal. Souvent, une intervention humaine est également nécessaire pour corriger les résultats du modèle.
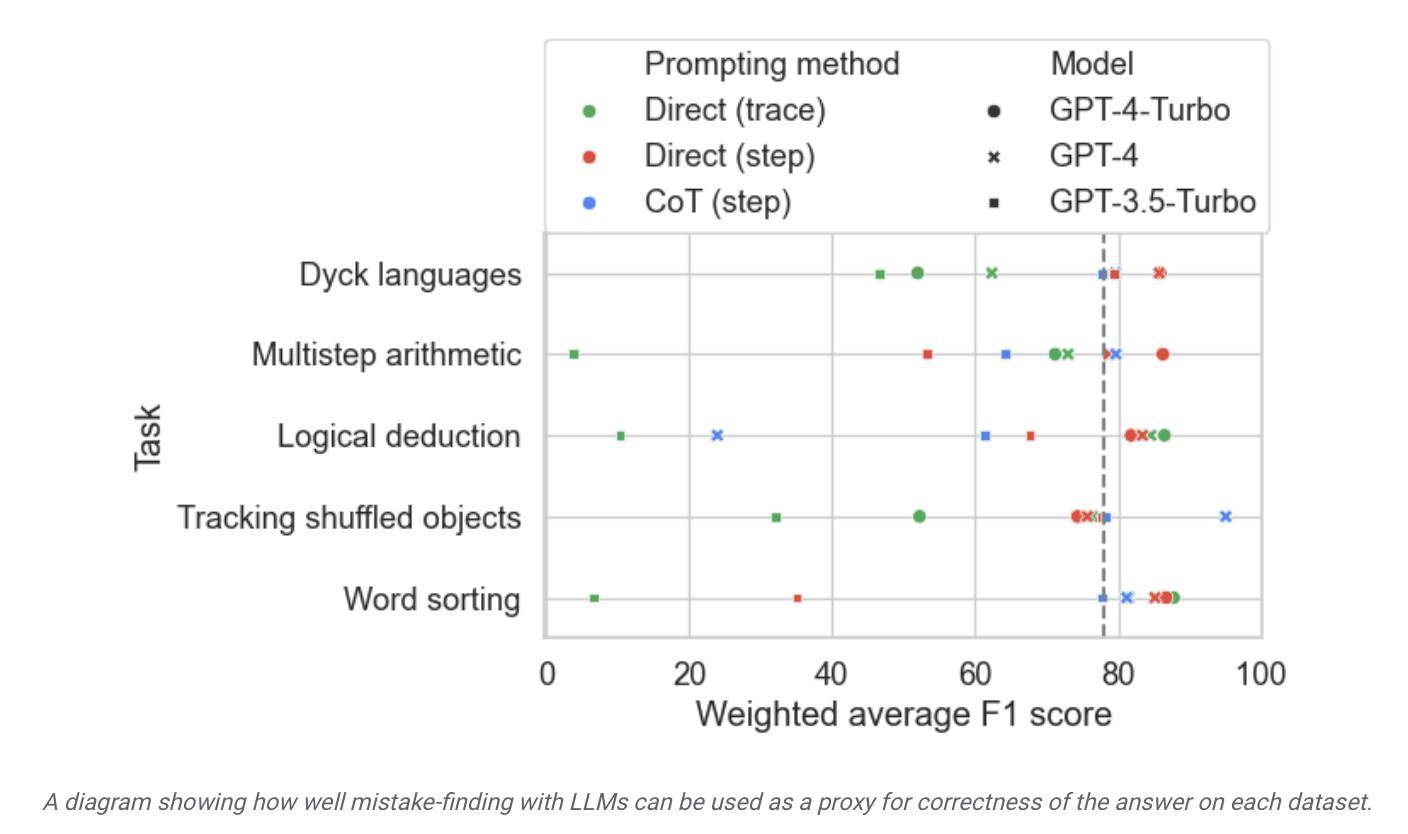
▲ Source photo communiqué de presse Google Research
Selon le rapport, Google affirme qu'il est actuellement considéré comme le grand modèle de langage le plus avancé, mais sa capacité d'autocorrection est relativement limitée. Lors des tests, le modèle le plus performant n'a trouvé que 52,9 % d'erreurs logiques.

Les chercheurs de Google ont également affirmé que cet ensemble de données BIG-Bench Mistake est propice à l'amélioration de la capacité d'autocorrection du modèle. Après avoir affiné le modèle sur des tâches de test pertinentes, « même les petits modèles fonctionnent généralement mieux que les grands modèles avec un échantillon nul ». instructions." ".
Selon cela, Google estime qu'en termes de correction des erreurs de modèle, les petits modèles propriétaires peuvent être utilisés pour « superviser » les grands modèles, au lieu de laisser les grands modèles de langage apprendre à « corriger leurs propres erreurs », en déployant de petits modèles dédiés dédiés à la supervision. les grands modèles sont bénéfiques pour améliorer l’efficacité, réduire les coûts de déploiement de l’IA associés et faciliter le réglage fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI