
Maison >Périphériques technologiques >IA >Google publie l'ensemble de données BIG-Bench Mistake pour aider les modèles de langage d'IA à améliorer leurs capacités d'auto-correction
Google publie l'ensemble de données BIG-Bench Mistake pour aider les modèles de langage d'IA à améliorer leurs capacités d'auto-correction

- 王林avant
- 2024-01-16 16:39:131373parcourir

Google Research a utilisé son propre benchmark BIG-Bench pour établir l'ensemble de données « BIG-Bench Mistake » et a mené une recherche d'évaluation sur la probabilité d'erreur et les capacités de correction d'erreur des modèles de langage populaires sur le marché. Cette initiative vise à améliorer la qualité et la précision des modèles linguistiques et à fournir un meilleur support aux applications dans les domaines de la recherche intelligente et du traitement du langage naturel.
Les chercheurs de Google ont déclaré avoir créé un ensemble de données spécial appelé "BIG-Bench Mistake" pour évaluer la probabilité d'erreur et les capacités d'autocorrection des grands modèles de langage. Le but de cet ensemble de données est de combler le manque d’ensembles de données pour évaluer ces capacités.
Les chercheurs ont exécuté 5 tâches sur le benchmark BIG-Bench en utilisant le modèle de langage PaLM. Par la suite, ils ont modifié la trajectoire de « chaîne de pensée » générée, ajouté une partie « erreur logique » et utilisé à nouveau le modèle pour déterminer les erreurs dans la trajectoire de chaîne de pensée.
Afin d'améliorer la précision de l'ensemble de données, les chercheurs de Google ont répété le processus ci-dessus et ont formé un ensemble de données de référence dédié appelé « BIG-Bench Mistake », qui contenait 255 erreurs logiques.
Les chercheurs ont souligné que les erreurs logiques dans l'ensemble de données "BIG-Bench Mistake" sont très évidentes, elles peuvent donc être utilisées comme une bonne norme de test pour aider le modèle de langage à commencer à s'entraîner à partir de simples erreurs logiques et à améliorer progressivement sa capacité à identifier les erreurs.
Les chercheurs ont utilisé cet ensemble de données pour tester des modèles sur le marché et ont découvert que même si la grande majorité des modèles de langage peuvent identifier les erreurs logiques qui se produisent au cours du processus de raisonnement et se corriger, ce processus n'est "pas idéal" et généralement nécessite une intervention humaine pour corriger le contenu de la sortie du modèle.
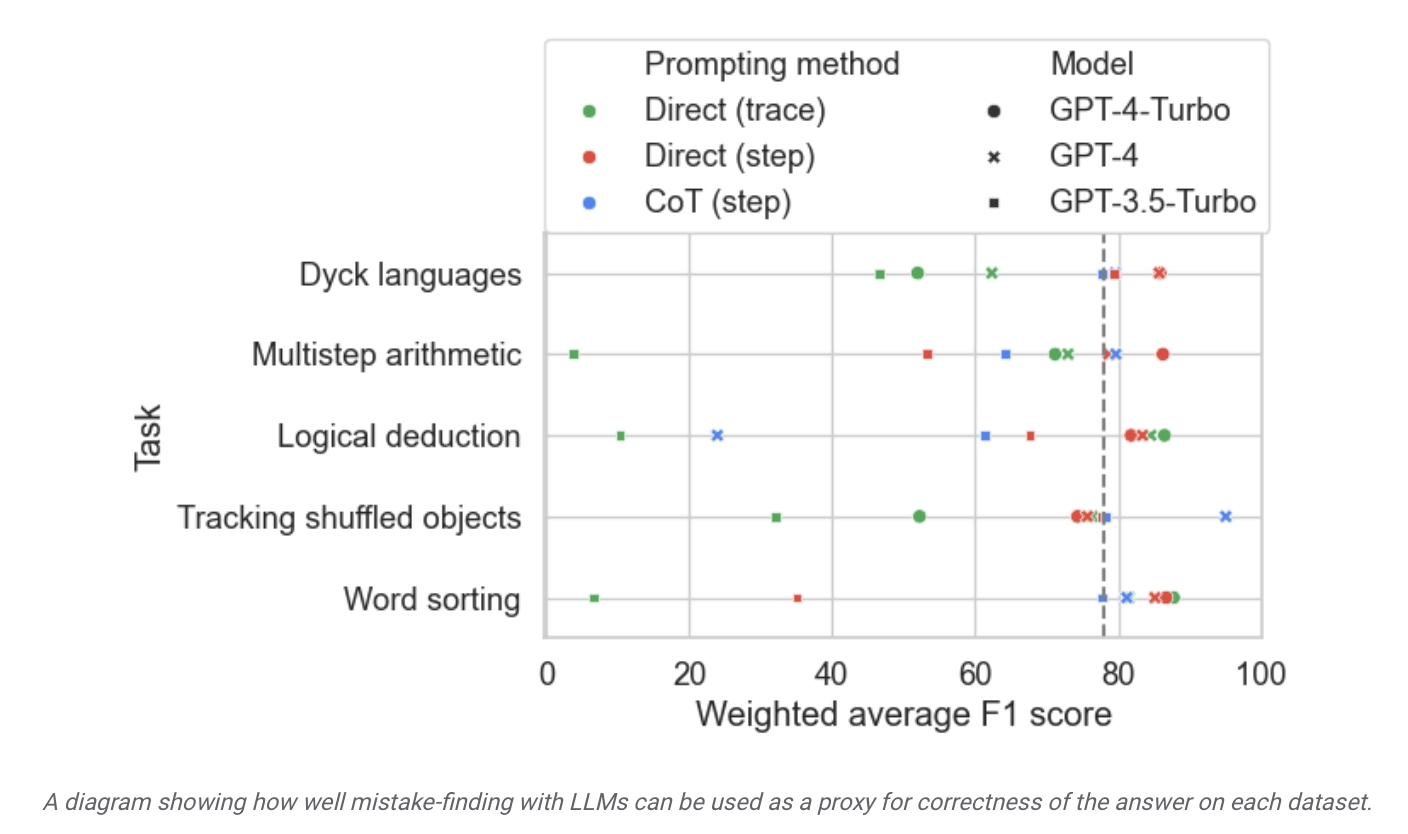
▲ Source de l'image Communiqué de presse de Google Research
Ce site a découvert à partir du rapport que Google affirme que le "grand modèle de langage actuellement le plus avancé" a des capacités d'autocorrection relativement limitées et qu'il a obtenu les meilleurs résultats dans les résultats de tests pertinents. Le modèle n'a trouvé que 52,9 % d'erreurs logiques.

Déployer de petits modèles dédiés. à la supervision de grands modèles a contribué à améliorer l'efficacité, à réduire les coûts de déploiement de l'IA associés et à faciliter le réglage fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que dois-je faire si Win10 ne trouve pas les Airpods ?
- Le Late Night King de Google reçoit une énorme mise à jour ! Le grand modèle PaLM 2 est sorti de manière choquante ! Bard écrit du code et ne sait pas quoi faire !
- Le dernier lecteur d'Aragonite, Onyx BOOX Palma, dévoilé, est aussi accrocheur qu'un téléphone portable
- Kunlun Wanwei lance Tiangong AI Search : le premier outil de recherche d'IA national intégrant des modèles linguistiques à grande échelle