
Maison >Tutoriel système >Linux >Cohérence de l'extraction en temps réel et de la synchronisation des données basée sur les journaux
Cohérence de l'extraction en temps réel et de la synchronisation des données basée sur les journaux

- 王林avant
- 2024-01-16 14:36:05755parcourir
Auteur : Wang Dong
Architecte du centre de R&D technologique CreditEase
- Je travaille actuellement au CreditEase Technology R&D Center en tant qu'architecte, responsable des solutions de produits informatiques en streaming et Big Data.
- A travaillé en tant qu'ingénieur senior au centre de R&D chinois de Naver China (la plus grande société de moteurs de recherche en Corée du Sud). Il est engagé dans le développement de clusters de bases de données distribuées CUBRID et dans le développement de moteurs de bases de données CUBRID depuis de nombreuses années http://www.cubrid). .org/blog/news/cubrid-cluster- introduction/
Introduction au thème :
- Présentation générale de DWS
- Architecture globale et plan de mise en œuvre technique dbus+wormhole
- Cas d'application pratiques du DWS
Bonjour à tous, je suis Wang Dong, du CreditEase Technology R&D Center. C'est la première fois que je partage dans la communauté. S'il y a des lacunes, veuillez me corriger et me pardonner.
Le thème de ce partage est "Mise en œuvre et application de la plateforme DWS basée sur les journaux", principalement pour partager certaines des choses que nous faisons actuellement chez CreditEase. Ce sujet contient les résultats des efforts de nombreux frères et sœurs des deux équipes (les résultats de notre équipe et de l'équipe Shanwei). Cette fois, je vais l'écrire en mon nom et faire de mon mieux pour vous le présenter.
En fait, l'ensemble de la mise en œuvre est relativement simple en principe, et bien sûr, elle implique également beaucoup de technologie. Je vais essayer de l'exprimer de la manière la plus simple possible pour que chacun comprenne le principe et la signification de cette affaire. Pendant le processus, si vous avez des questions, vous pouvez les poser à tout moment et je ferai de mon mieux pour y répondre.
DWS est une abréviation et se compose de 3 sous-projets, que j'expliquerai plus tard.
1. ContexteTout a commencé avec les besoins de l’entreprise il y a quelque temps. Tout le monde sait que CreditEase est une société financière sur Internet. Beaucoup de nos données sont différentes des sociétés Internet standards. De manière générale, elles sont :
.
Tous ceux qui jouent avec les données savent que les données sont très précieuses et que ces données sont stockées dans les bases de données de divers systèmes. Comment les utilisateurs qui ont besoin de données peuvent-ils obtenir des données cohérentes et en temps réel ?
Il existe plusieurs pratiques courantes dans le passé :- DBA ouvre la base de données de sauvegarde de chaque système. Pendant les périodes de faible activité (comme la nuit), les utilisateurs peuvent extraire les données requises. En raison des différents temps d'extraction, des incohérences des données entre les différents utilisateurs de données, des conflits de données et des extractions répétées, je pense que de nombreux administrateurs de base de données ont mal à la tête.
- La plate-forme Big Data unifiée de l'entreprise utilise Sqoop pour extraire uniformément les données de divers systèmes pendant les périodes de faible activité, les enregistrer dans des tables Hive, puis fournir des services de données à d'autres utilisateurs de données. Cette approche résout le problème de cohérence, mais la rapidité est médiocre, essentiellement à T+1.
- Le principal problème de l'obtention de changements incrémentiels basés sur des déclencheurs est que le côté commercial est très intrusif et que les déclencheurs entraînent également des pertes de performances.
Aucune de ces solutions n’est parfaite. Après avoir compris et envisagé différentes méthodes de mise en œuvre, nous nous sommes finalement inspirés des idées de linkedin et avons pensé que pour résoudre à la fois la cohérence des données et les performances en temps réel, une méthode plus raisonnable devrait provenir du journal.
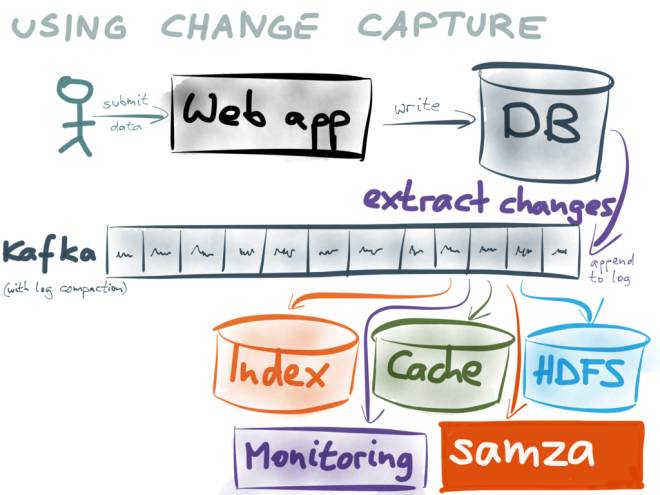
(Cette image provient de : https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea / )
Utilisez le journal incrémentiel comme base de tous les systèmes. Les utilisateurs de données ultérieurs consomment des journaux en s'abonnant à Kafka.
Par exemple :
- Les utilisateurs de Big Data peuvent enregistrer des données dans des tables Hive ou des fichiers Parquet pour les requêtes Hive ou Spark ;
- Les utilisateurs qui fournissent des services de recherche peuvent les enregistrer dans Elasticsearch ou HBase ;
- Les utilisateurs qui fournissent des services de mise en cache peuvent mettre en cache les journaux dans Redis ou alluxio ;
- Les utilisateurs de la synchronisation des données peuvent enregistrer les données dans leur propre base de données ;
- Étant donné que les journaux de Kafka peuvent être consommés à plusieurs reprises et mis en cache pendant un certain temps, chaque utilisateur peut maintenir la cohérence avec la base de données et garantir des performances en temps réel en consommant les journaux de Kafka ;
Pourquoi utiliser log et kafka comme base au lieu d'utiliser Sqoop pour l'extraction ? Parce que :
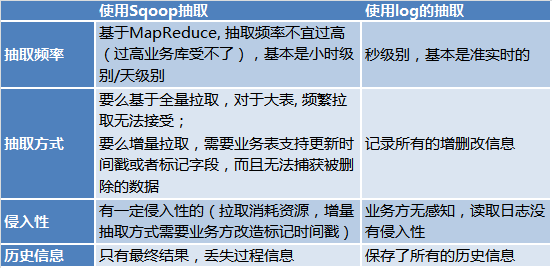
Pourquoi ne pas utiliser la double écriture ? , veuillez vous référer à https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
Je n’expliquerai pas grand-chose ici.
Nous avons donc eu l'idée de construire une plateforme au niveau de l'entreprise basée sur les logs.
Ce qui suit explique la plateforme DWS La plateforme DWS se compose de 3 sous-projets :
- Dbus (bus de données) : responsable de l'extraction des données de la source en temps réel, de leur conversion au format json convenu (données UMS) avec son propre schéma et de leur mise dans Kafka ;
- Wormhole (plateforme d'échange de données) : Responsable de la lecture des données de kafka et de l'écriture des données sur la cible ;
- Swifts (plate-forme informatique en temps réel) : Responsable de la lecture des données de Kafka, du calcul en temps réel et de la réécriture des données dans Kafka.
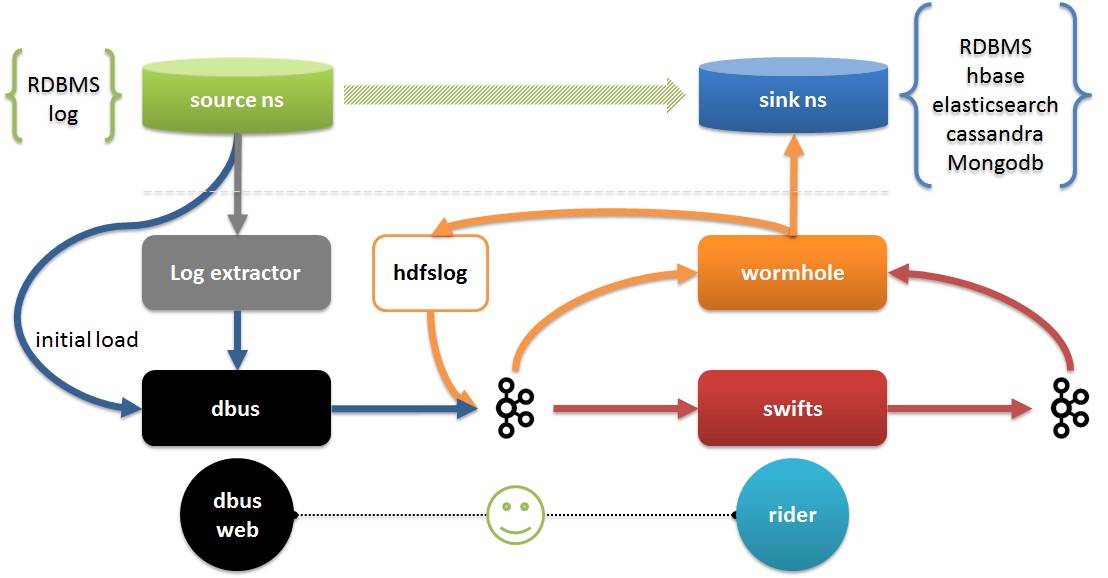
- L'extracteur de journaux et dbus fonctionnent ensemble pour terminer l'extraction et la conversion des données. L'extraction comprend une extraction complète et incrémentielle.
- Wormhole peut enregistrer toutes les données de journal sur HDFS ; il peut également implémenter des données dans toutes les bases de données prenant en charge jdbc, y compris HBash, Elasticsearch, Cassandra, etc. ;
- Swifts prend en charge les calculs de streaming via la configuration et SQL, y compris la prise en charge de la jointure de streaming, de la recherche, du filtre, de l'agrégation de fenêtres et d'autres fonctions ; Dbus web est la fin de la gestion de la configuration de dbus. En plus de la gestion de la configuration, le pilote inclut également la gestion de l'exécution de Wormhole et Swifts, la vérification de la qualité des données, etc.
- En raison de contraintes de temps, aujourd'hui, je présenterai principalement Dbus et Wormhole dans DWS, et présenterai Swifts si nécessaire.
Photo de : https://github.com/alibaba/canal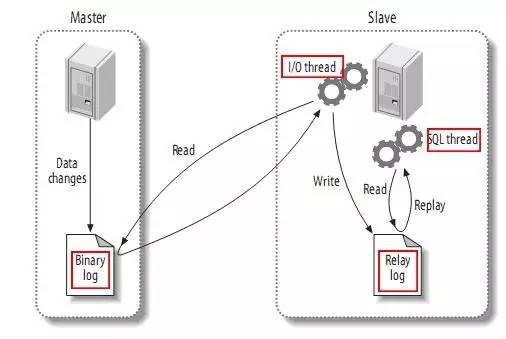
- Mode déclaration : chaque instruction SQL qui modifie les données sera enregistrée dans le journal bin du maître. Lorsque l'esclave se réplique, le processus SQL l'analysera dans le même SQL qui a été exécuté du côté maître d'origine et l'exécutera à nouveau.
- Mode mixte : MySQL distinguera le formulaire de journal à enregistrer en fonction de chaque instruction SQL spécifique exécutée, c'est-à-dire en choisira une entre Statement et Row.
- Leurs avantages et inconvénients respectifs sont les suivants :
Ici vient de : http://www.jquerycn.cn/a_13625
Habituellement, notre configuration MySQL est une solution de 2 bases de données maîtres (vip) + 1 base de données esclave + 1 base de données de récupération après sinistre étant donné que la base de données de récupération après sinistre est généralement utilisée pour la récupération après sinistre à distance, les performances en temps réel ne sont pas élevées. déployer.
Afin de minimiser l'impact sur la partie source, nous devons évidemment lire le journal binlog de la bibliothèque esclave.
Il existe de nombreuses solutions pour lire binlog, et il y en a beaucoup sur github. Veuillez vous référer à https://github.com/search?utf8=%E2%9C%93&q=binlog. En fin de compte, nous avons choisi le canal d'Alibaba comme méthode d'extraction des grumes.
Canal a d’abord été utilisé pour synchroniser les salles informatiques chinoises et américaines d’Alibaba. Le principe de canal est relativement simple :
.
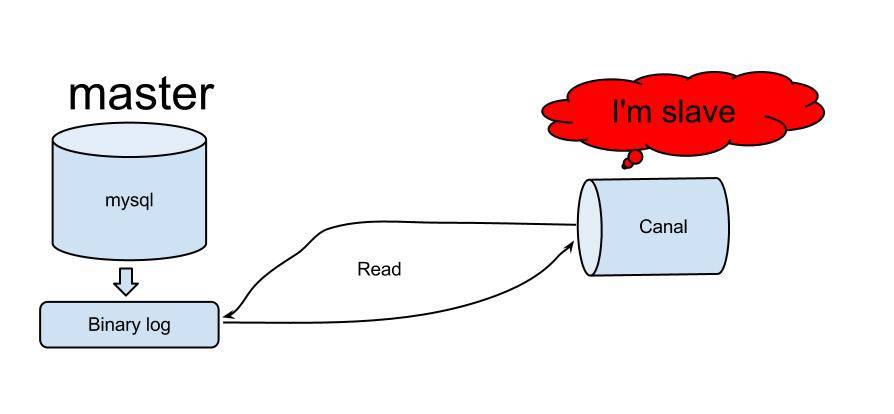
Photo de : https://github.com/alibaba/canal
SolutionLes principales solutions pour la version MySQL de Dbus sont les suivantes :
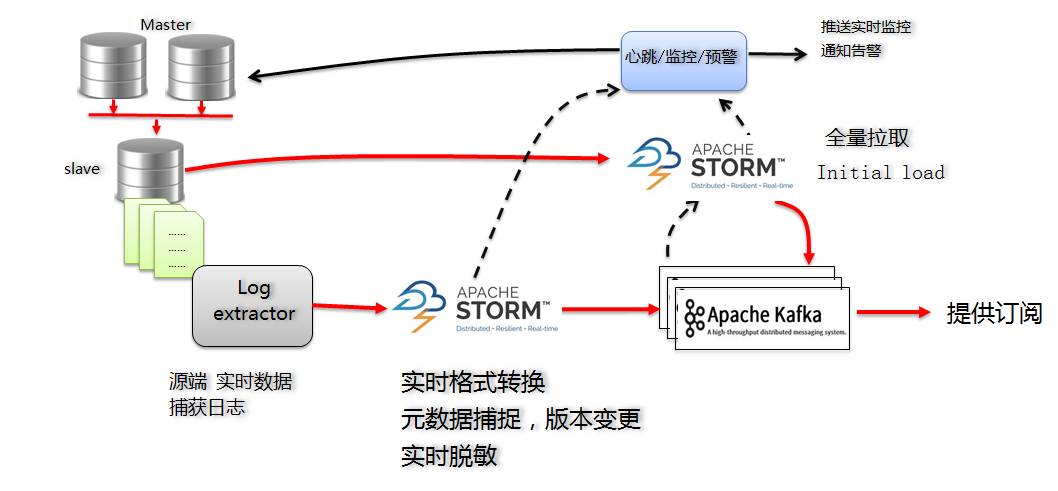
Pour les logs incrémentaux, en s'abonnant à Canal Server, on obtient les logs incrémentaux de MySQL :
- Selon la sortie de Canal, le journal est au format protobuf. Développez un programme Storm incrémental pour convertir les données au format UMS que nous avons défini en temps réel (format json, je le présenterai plus tard), et enregistrez-le sur kafka ;
- Le programme Storm incrémentiel est également chargé de capturer les modifications de schéma pour contrôler le numéro de version ;
- Les informations de configuration incrémentielles de Storm sont enregistrées dans Zookeeper pour répondre aux exigences de haute disponibilité.
- Kafka sert à la fois de résultats de sortie et de zone tampon et de déconstruction des messages pendant le traitement.
Lorsque nous envisageons d'utiliser Storm comme solution, nous pensons principalement que Storm présente les avantages suivants :
- La technologie est relativement mature et stable, et elle peut être considérée comme une combinaison standard lorsqu'elle est associée à Kafka ;
- Les performances en temps réel sont relativement élevées et peuvent répondre aux besoins en temps réel ;
- Répondre aux exigences de haute disponibilité ;
- En configurant la simultanéité Storm, vous pouvez activer la possibilité d'étendre les performances ;
Pour les tables de flux, la partie incrémentielle est suffisante, mais de nombreuses tables ont besoin de connaître les informations initiales (existantes). À ce stade, nous avons besoin d’un chargement initial (premier chargement).
Pour le chargement initial (premier chargement), nous avons également développé un programme Storm d'extraction complète à extraire de la base de données de secours de la base de données source via une connexion jdbc. La charge initiale consiste à extraire toutes les données. Nous vous recommandons donc de le faire pendant les périodes de faible activité. Heureusement, vous ne le faites qu’une seule fois et vous n’avez pas besoin de le faire tous les jours.
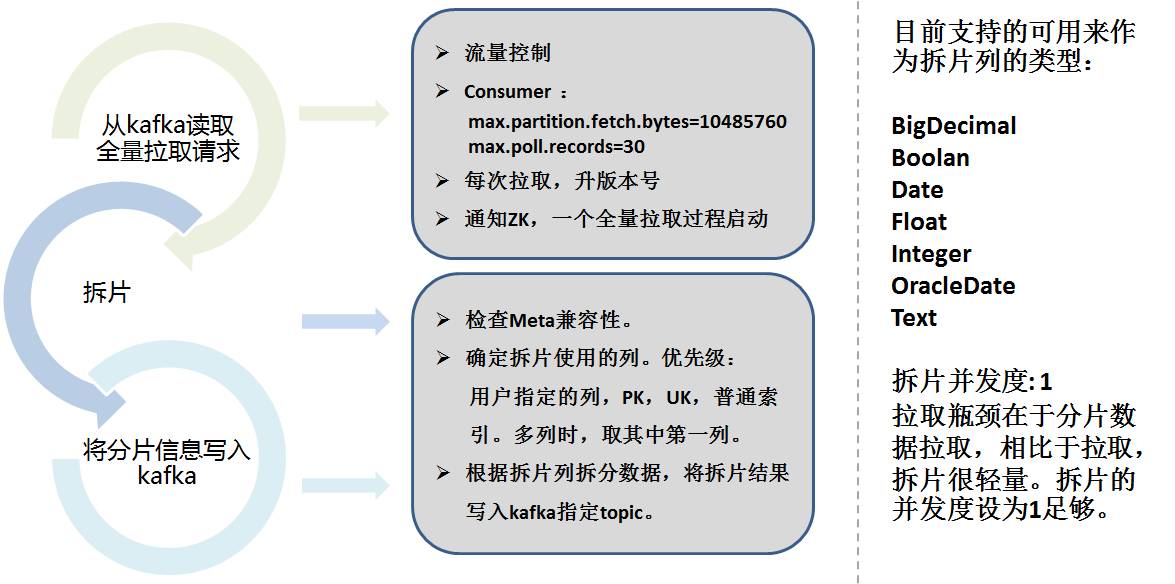
Pour extraire le montant total, nous nous appuyons sur les idées de Sqoop. L'extraction complète de Storm est divisée en 2 parties :
- Partage de données
- Extraction réelle
Le partage de données doit prendre en compte la colonne de partitionnement, diviser les données en fonction de la plage en fonction de la configuration, sélectionner automatiquement la colonne et enregistrer les informations de partitionnement dans Kafka.
Voici la stratégie de partitionnement spécifique :
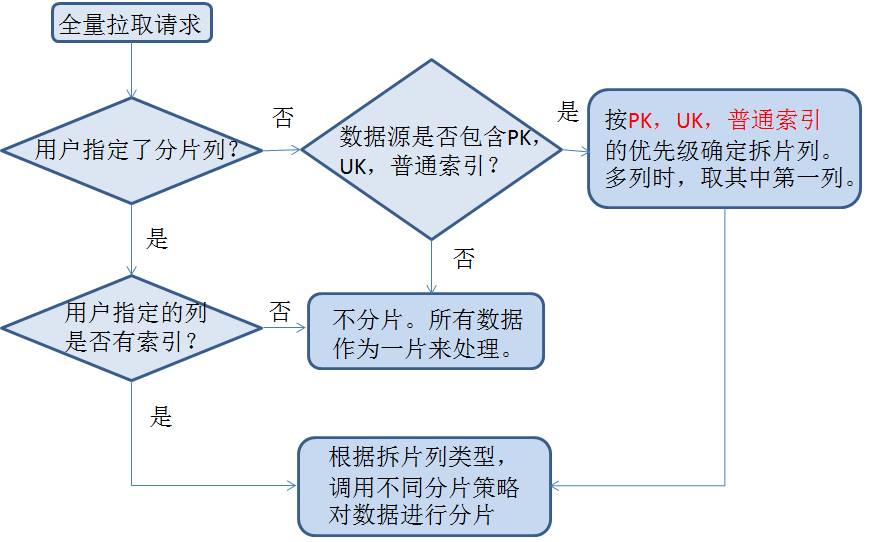
Le programme Storm pour l'extraction complète lit les informations de partitionnement de Kafka et utilise plusieurs niveaux de concurrence pour se connecter en parallèle à la base de données de secours pour l'extraction. Car le temps d’extraction peut être très long. Pendant le processus d'extraction, l'état en temps réel est écrit dans Zookeeper pour faciliter la surveillance du programme de battement de cœur.
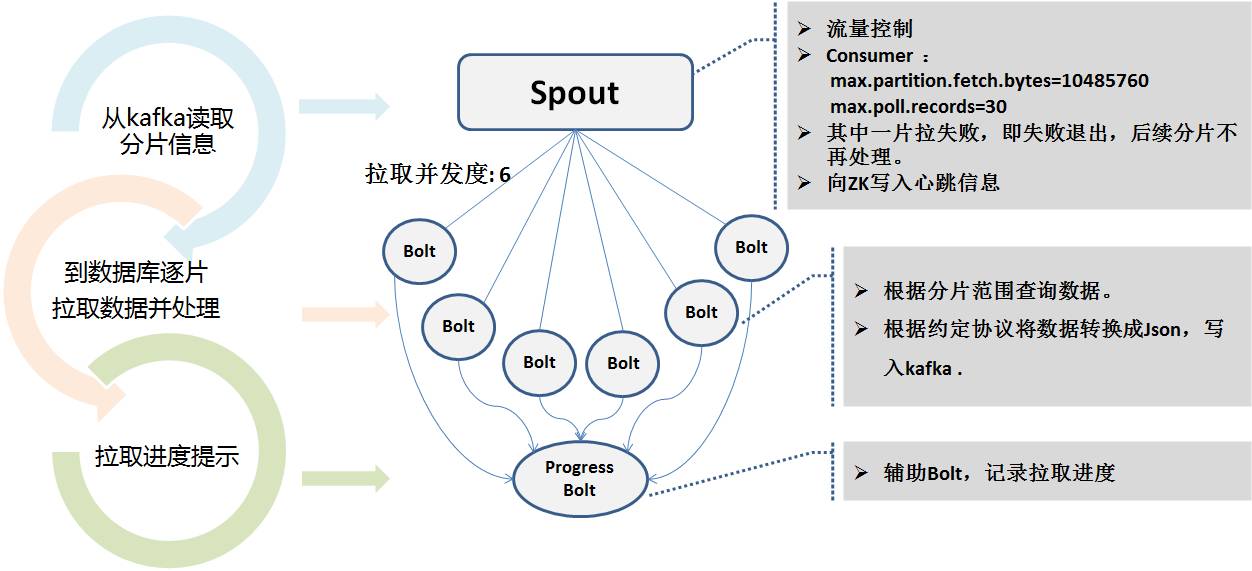
Qu'il soit incrémentiel ou complet, le message final envoyé à kafka est un format de message unifié sur lequel nous nous sommes mis d'accord, appelé format UMS (schéma de message unifié).
Comme le montre l'image ci-dessous :
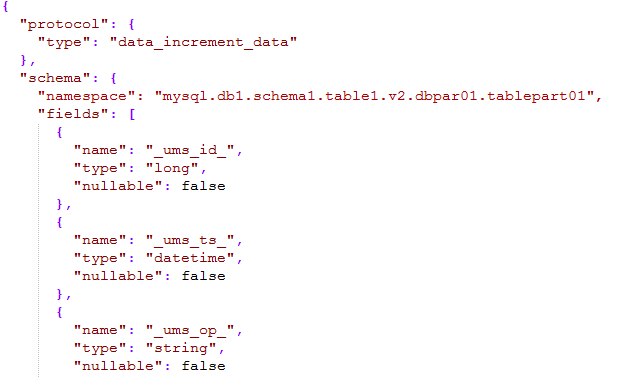

La partie schéma du message définit l'espace de noms, qui est composé du type + nom de la source de données + nom du schéma + nom de la table + numéro de version + numéro de sous-bibliothèque + numéro de sous-table. Elle peut décrire toutes les tables de l'ensemble de l'entreprise et. peut être localisé de manière unique via un espace de noms.
- _ums_op_ indique que le type de données est I (insérer), U (mettre à jour), D (supprimer) ; _ums_ts_ L'horodatage des événements d'ajout, de suppression et de modification Évidemment l'horodatage des nouvelles données est mis à jour ;
- _ums_id_ L'identifiant unique du message, garantissant que le message est unique, mais ici nous garantissons l'ordre des messages (expliqué plus tard ) ;
Les types de données pris en charge dans UMS font référence aux types Hive et sont simplifiés, incluant essentiellement tous les types de données.
Cohérence du volume complet et du volume incrémentiel Dans l'ensemble de la transmission des données, afin de garantir autant que possible l'ordre des messages de journal, Kafka utilise une méthode de partition. En général, il est fondamentalement séquentiel et unique.Mais nous savons que l'écriture de Kafka échouera et peut être réécrite. Storm utilise également un mécanisme de restauration. Par conséquent, nous ne garantissons pas strictement une séquence exacte et complète, mais nous garantissons au moins une fois.
Donc _ums_id_ devient particulièrement important.
Pour une extraction complète, _ums_id_ est unique. Différentes tranches d'identifiant sont extraites de chaque degré de concurrence dans zk, garantissant l'unicité et les performances. Le remplissage de nombres négatifs n'entrera pas en conflit avec les données incrémentielles et garantit également qu'ils sont antérieurs aux données incrémentielles. Quantité de nouvelles.
Pour l'extraction incrémentielle, nous utilisons le numéro de fichier journal de MySQL + le décalage du journal comme identifiant unique. L'identifiant est utilisé comme un entier de 64 bits, les 7 bits supérieurs sont utilisés pour le numéro du fichier journal et les 12 bits inférieurs sont utilisés comme décalage du journal.
Par exemple : 000103000012345678. 103 est le numéro du fichier journal et 12345678 est le décalage du journal.
De cette façon, l'unicité physique est assurée dès le niveau du log (le numéro d'identification ne changera pas même s'il est refait), et l'ordre est également garanti (le log peut également être localisé). En comparant le journal de consommation _ums_id_, vous pouvez savoir quel message est mis à jour en comparant _ums_id_.
En fait, les intentions de _ums_ts_ et _ums_id_ sont similaires, sauf que parfois _ums_ts_ peut être répété, c'est-à-dire que plusieurs opérations se produisent en 1 milliseconde, vous devez donc comparer _ums_id_.
Surveillance du rythme cardiaque et alerte précoce L'ensemble du système implique la synchronisation principale et de sauvegarde de la base de données, du serveur Canal, des processus Storm à simultanéité multiple et d'autres aspects.Par conséquent, la surveillance et l’alerte précoce du processus sont particulièrement importantes.
Grâce au module de battement de cœur, par exemple, insérez une donnée de mentalité dans chaque table extraite toutes les minutes (configurable) et enregistrez l'heure d'envoi. Cette table de battement de cœur est également extraite et suit l'ensemble du processus, qui est en fait le même que le synchronisé. Dans la logique de la table (car plusieurs Storm simultanés peuvent avoir des branches différentes), lorsqu'un paquet de battements de cœur est reçu, il peut être prouvé que l'intégralité du lien est ouverte même s'il n'y a aucune donnée ajoutée, supprimée ou modifiée.
Le programme Storm et le programme Heartbeat envoient les données au sujet statistique public, puis le programme statistique les enregistre dans influxdb. Utilisez grafana pour les afficher, et vous pouvez voir l'effet suivant :
.
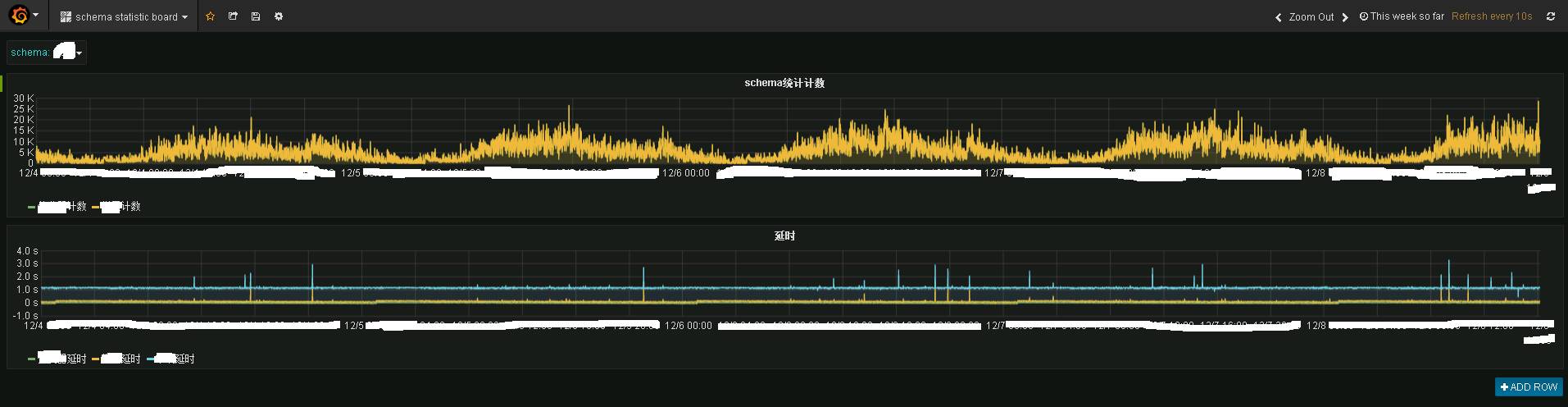 L'image montre les informations de surveillance en temps réel d'un certain système d'entreprise. Ce qui précède est la situation du trafic en temps réel, et ce qui suit est la situation des retards en temps réel. On constate que les performances en temps réel sont toujours très bonnes, en gros, les données ont été transférées vers le terminal Kafka en 1 à 2 secondes.
L'image montre les informations de surveillance en temps réel d'un certain système d'entreprise. Ce qui précède est la situation du trafic en temps réel, et ce qui suit est la situation des retards en temps réel. On constate que les performances en temps réel sont toujours très bonnes, en gros, les données ont été transférées vers le terminal Kafka en 1 à 2 secondes.
Granfana offre une capacité de surveillance en temps réel.
En cas de retard, une alarme par e-mail ou par SMS sera envoyée via le module de battement de cœur de dbus.
Désensibilisation en temps réel Considérant la sécurité des données, les programmes de tempête complète et de tempête incrémentielle de Dbus complètent également les fonctions de désensibilisation en temps réel pour les scénarios où une désensibilisation est requise. Il existe 3 moyens de désensibilisation :
 Pour résumer : en termes simples, Dbus exporte des données provenant de diverses sources en temps réel et propose des abonnements sous forme d'UMS, prenant en charge la désensibilisation en temps réel, la surveillance réelle et l'alarme.
Pour résumer : en termes simples, Dbus exporte des données provenant de diverses sources en temps réel et propose des abonnements sous forme d'UMS, prenant en charge la désensibilisation en temps réel, la surveillance réelle et l'alarme.
L'une des principales raisons est que Kafka a des capacités de découplage naturelles et que le programme peut directement envoyer des messages asynchrones via Kafka. Dbus et Wornhole utilisent également kafka en interne pour la transmission et le découplage des messages.
Une autre raison est qu'UMS est auto-descriptif. En s'abonnant à kafka, tout utilisateur compétent peut directement consommer UMS pour l'utiliser.
Bien que les résultats de l'UMS puissent être souscrits directement, cela nécessite encore un travail de développement. Ce que Wormhole résout, c'est de fournir une configuration en un clic pour implémenter les données dans Kafka dans divers systèmes, permettant aux utilisateurs de données sans capacités de développement d'utiliser les données via Wormhole.
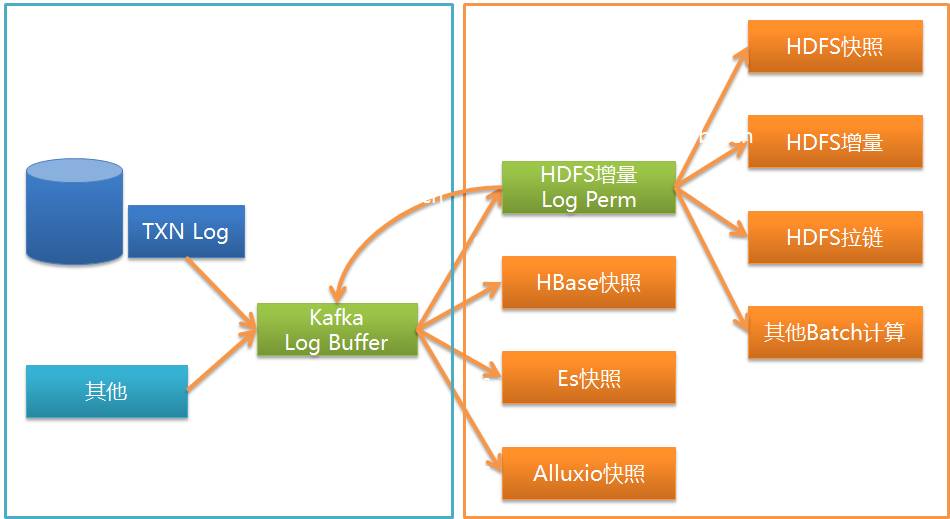
Comme le montre la figure, Wormhole peut implémenter UMS dans Kafka sur divers systèmes, actuellement les plus couramment utilisés sont HDFS, la base de données JDBC et HBase.
En termes de pile technologique, wormhole choisit d'utiliser le streaming d'étincelles.
Dans Wormhole, un flux fait référence à un namaspace de la source à la cible. Un flux d’étincelles dessert plusieurs flux.
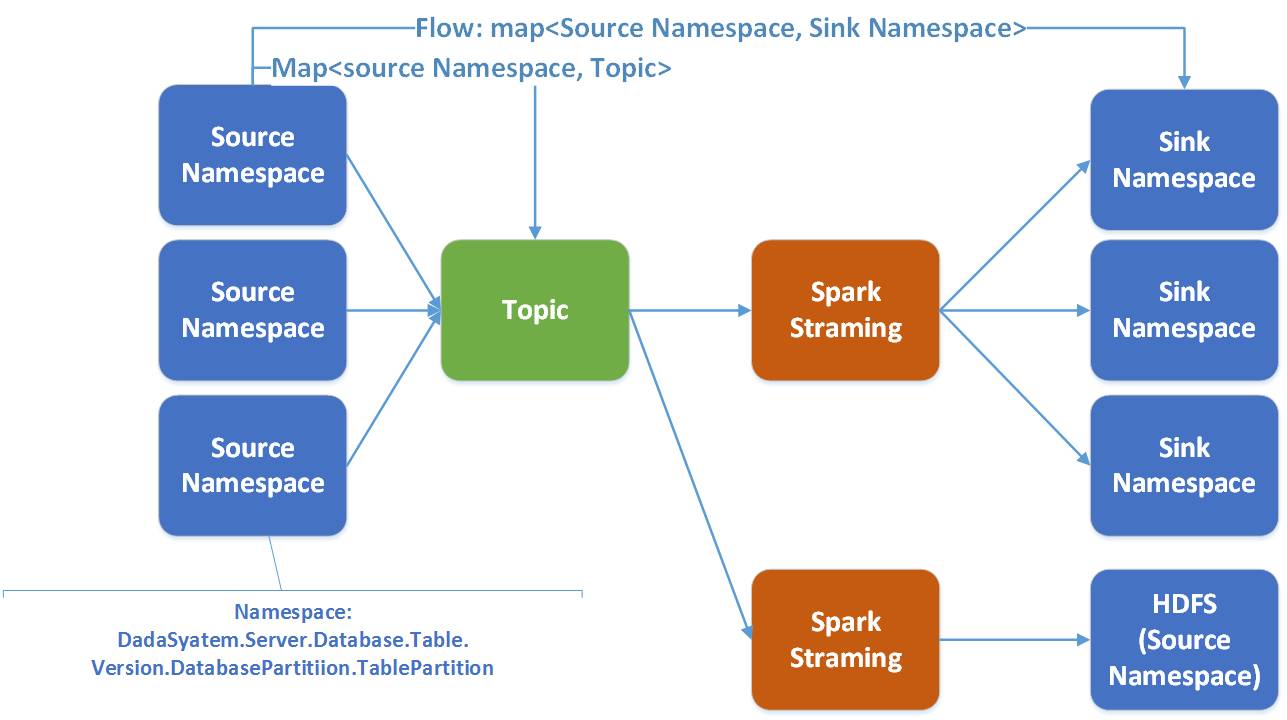
Il y a de bonnes raisons de choisir Spark :
- Spark prend naturellement en charge divers systèmes de stockage hétérogènes ; Bien que Spark Stream ait une latence légèrement inférieure à celle de Storm, Spark a un meilleur débit et de meilleures performances informatiques
- ; Spark offre une plus grande flexibilité dans la prise en charge du calcul parallèle ;
- Spark fournit des fonctions unifiées pour résoudre Sparking Job, Spark Streaming et Spark SQL au sein d'une pile technologique afin de faciliter le développement ultérieur
- ;
- L'essence de Swifts est de lire les données UMS dans Kafka, d'effectuer des calculs en temps réel et d'écrire les résultats dans un autre sujet dans Kafka.
- Le calcul en temps réel peut être effectué de plusieurs manières : comme le filtre, la projection (projection), la recherche, l'agrégation de fenêtres de jointure de streaming, qui peuvent effectuer divers calculs de streaming en temps réel avec une valeur commerciale.
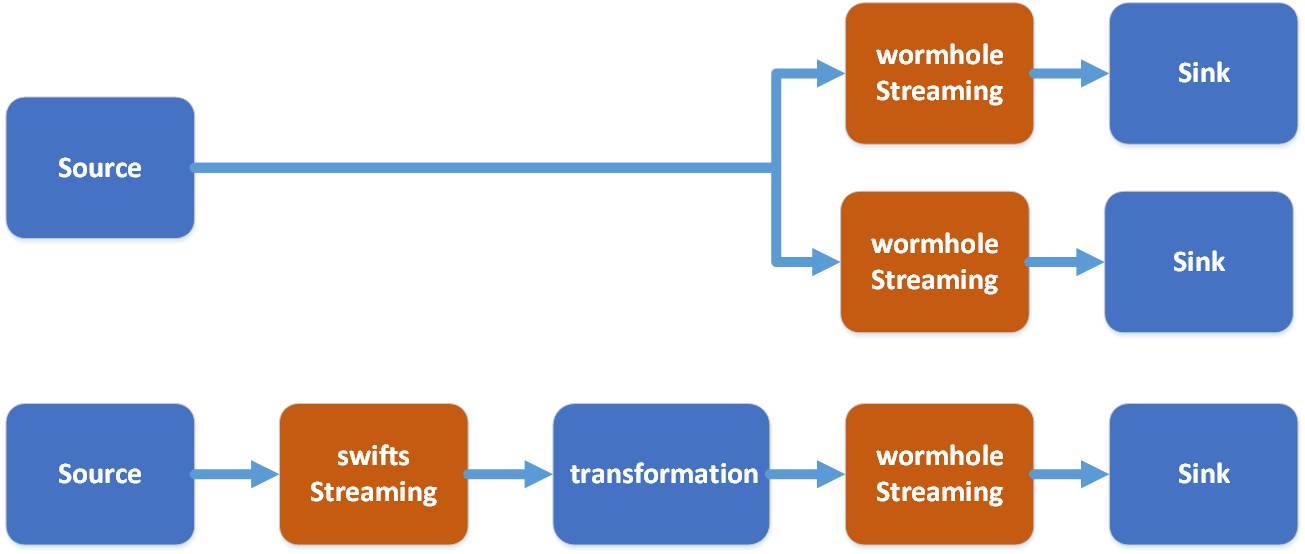
Kafka n'enregistre généralement que quelques jours d'informations et n'enregistre pas toutes les informations, tandis que HDFS peut enregistrer tous les ajouts, suppressions et modifications historiques. Cela rend beaucoup de choses possibles :
- En rejouant les journaux dans HDFS, nous pouvons restaurer des instantanés historiques à tout moment.
- Vous pouvez créer une liste zip pour restaurer les informations historiques de chaque enregistrement pour une analyse facile ;
- Lorsqu'une erreur se produit dans le programme, vous pouvez utiliser le remplissage pour réutiliser les messages et reformer un nouvel instantané.
Étant donné que Spark prend très bien en charge nativement Parquet, Spark SQL peut fournir de bonnes requêtes pour Parquet. Lorsque UMS est implémenté sur HDFS, il est enregistré dans un fichier Parquet. Le contenu de Parquet comprend les informations d'ajout, de suppression et de modification de tous les journaux, ainsi que _ums_id_ et _ums_ts_.
Le streaming Wormhole Spark distribue et stocke les données dans différents répertoires en fonction de l'espace de noms, c'est-à-dire que différentes tables et versions sont placées dans différents répertoires.
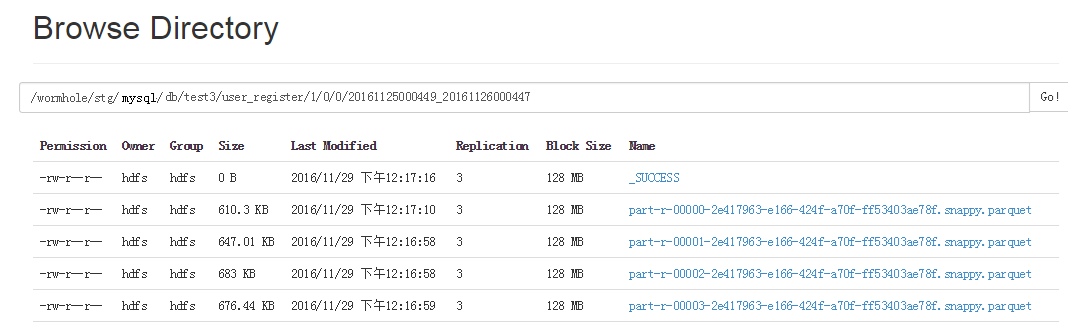 Étant donné que les fichiers Parquet écrits à chaque fois sont de petits fichiers, tout le monde sait que HDFS ne fonctionne pas bien pour les petits fichiers, il existe donc un autre travail pour fusionner régulièrement ces fichiers Parquet en gros fichiers.
Étant donné que les fichiers Parquet écrits à chaque fois sont de petits fichiers, tout le monde sait que HDFS ne fonctionne pas bien pour les petits fichiers, il existe donc un autre travail pour fusionner régulièrement ces fichiers Parquet en gros fichiers.
Chaque répertoire de fichiers Parquet est livré avec l'heure de début et l'heure de fin des données du fichier. De cette façon, lors du remplissage des données, vous pouvez décider quels fichiers Parquet doivent être lus en fonction de la plage de temps sélectionnée, sans lire toutes les données.
Idempotence de l'insertion ou de la mise à jour des données Nous rencontrons souvent le besoin de traiter des données et de les mettre dans une base de données ou HBase. La question qui se pose ici est donc la suivante : quel type de données peut être mis à jour ?Le principe le plus important ici est l’idempotence des données.
Peu importe l'ajout, la suppression ou la modification de données, les problèmes auxquels nous sommes confrontés sont :
- Quelle ligne doit être mise à jour ? Quelle est la stratégie mise à jour.
.
- Utilisez la clé primaire de la bibliothèque métier ;
- Le groupe commercial spécifie plusieurs colonnes comme index uniques communs ;
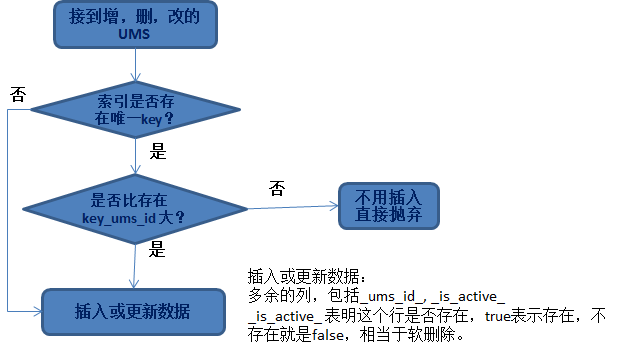 La raison pour laquelle nous devons effectuer une suppression logicielle et ajouter la colonne _is_active_ est pour une telle situation :
La raison pour laquelle nous devons effectuer une suppression logicielle et ajouter la colonne _is_active_ est pour une telle situation :
Si le _ums_id_ inséré est relativement volumineux, il s'agit de données supprimées (indiquant que les données ont été supprimées). S'il ne s'agit pas d'une suppression logicielle, insérez une petite donnée _ums_id_ (anciennes données) à ce moment-là, et elle sera effectivement insérée. .
Cela entraîne l'insertion d'anciennes données. Plus idempotent. Il est donc important que les données supprimées soient toujours conservées (suppression logicielle) et puissent être utilisées pour garantir l'idempotence des données.
Sauvegarde HBase Insérer des données dans Hbase est assez simple. La différence est que HBase peut conserver plusieurs versions de données (bien sûr, vous pouvez également conserver une seule version). La valeur par défaut est de conserver 3 versions ; Ainsi, lors de l'insertion de données dans HBase, les problèmes à résoudre sont :
- Choisissez la version appropriée : utilisez _ums_id_+ un décalage plus grand (par exemple 10 milliards) que la version en ligne.
- Le choix de la version est très intéressant. Il profite de l'unicité et de l'auto-incrémentation de _ums_id_ et est cohérent avec la relation de comparaison de la version elle-même : c'est-à-dire qu'une version plus grande équivaut à un _ums_id_ plus grand, et la version correspondante est plus récent.
Insérer des données dans Jdbc :
Insérez des données dans la base de données. Bien que le principe pour garantir l'idempotence soit simple, si vous souhaitez améliorer les performances, la mise en œuvre devient beaucoup plus compliquée. Vous ne pouvez pas comparer une par une puis insérer ou mettre à jour.
Nous savons que le RDD/ensemble de données de Spark est exploité de manière collectée pour améliorer les performances. De même, nous devons atteindre l'idempotence de manière opérationnelle.
L'idée spécifique est :
- Par rapport aux collections de l'ensemble de données, elles sont divisées en deux catégories :
- A : Données qui n'existent pas, c'est-à-dire insérez simplement cette partie des données ;
Les étudiants qui utilisent Spark savent que le RDD/ensemble de données peut être partitionné et que plusieurs travailleurs peuvent être utilisés et exploités pour améliorer l'efficacité.
Par exemple : parce que d'autres travailleurs ont déjà inséré et que l'insertion échoue en raison de la contrainte unique, vous devez le mettre à jour à la place et comparer _ums_id_ pour voir s'il peut être mis à jour.
Wormhole dispose également d'un mécanisme de nouvelle tentative pour d'autres situations où il ne peut pas être inséré (comme un problème avec le système cible). Il y a tellement de détails. Pas beaucoup d'introduction ici.
Certains sont encore en cours de développement.
Je n'entrerai pas dans les détails de l'insertion dans d'autres stockages. Le principe général est le suivant : concevoir une implémentation d'insertion de données simultanée basée sur une collection, en fonction des caractéristiques de chaque stockage. Ce sont les efforts de Wormhole en matière de performances, et les utilisateurs qui utilisent Wormhole n'ont pas à s'en soucier.
Cela dit, quelles sont les applications pratiques du DWS ? Ensuite, je présenterai le marketing en temps réel mis en œuvre par un certain système utilisant DWS.
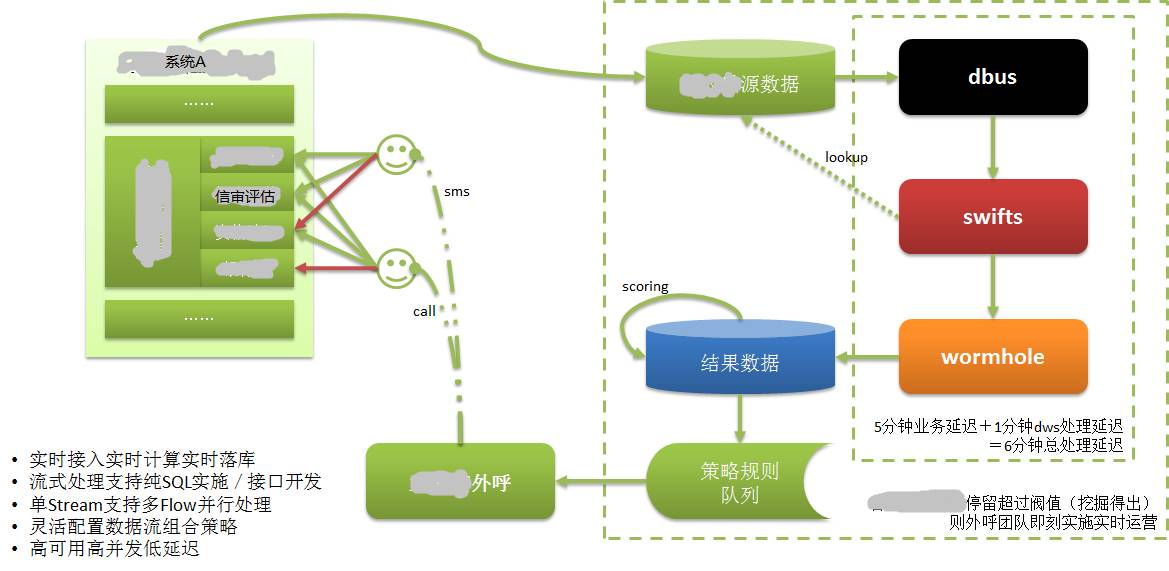
Comme le montre l'image ci-dessus :
Les données du système A sont enregistrées dans sa propre base de données. Nous savons que CreditEase fournit de nombreux services financiers, y compris l'emprunt, et qu'une chose très importante dans le processus d'emprunt est l'examen du crédit.
Les emprunteurs doivent fournir des informations prouvant leur solvabilité, telles que le rapport de crédit de la banque centrale, qui est la donnée contenant les données de crédit les plus solides. Les transactions bancaires et les transactions d'achat en ligne sont également des données présentant de forts attributs de crédit.
Lorsqu'un emprunteur remplit des informations de crédit dans le système A via le Web ou l'application mobile, il peut ne pas être en mesure de continuer pour une raison quelconque. Bien que cet emprunteur puisse être un client potentiel de haute qualité, dans le passé, ces informations n'étaient pas disponibles. ou ne pourraient être connus que depuis longtemps. De tels clients sont perdus.
Après l'application de DWS, les informations renseignées par l'emprunteur ont été enregistrées dans la base de données et sont extraites, calculées et implémentées dans la base de données cible en temps réel via DWS. Évaluez les clients de haute qualité en fonction des évaluations des clients. Ensuite, envoyez immédiatement les informations du client au système de service client.
Le personnel du service client a contacté l'emprunteur (client potentiel) en l'appelant dans un délai très court (en quelques minutes), a assuré le service client et a converti le client potentiel en un vrai client. Nous savons que l’emprunt est une question de temps et n’aura aucune valeur s’il prend trop de temps.
Sans la possibilité d'extraire/calculer/déposer en temps réel, rien de tout cela ne serait possible.
Système de reporting en temps réelUne autre application de rapport en temps réel est la suivante :
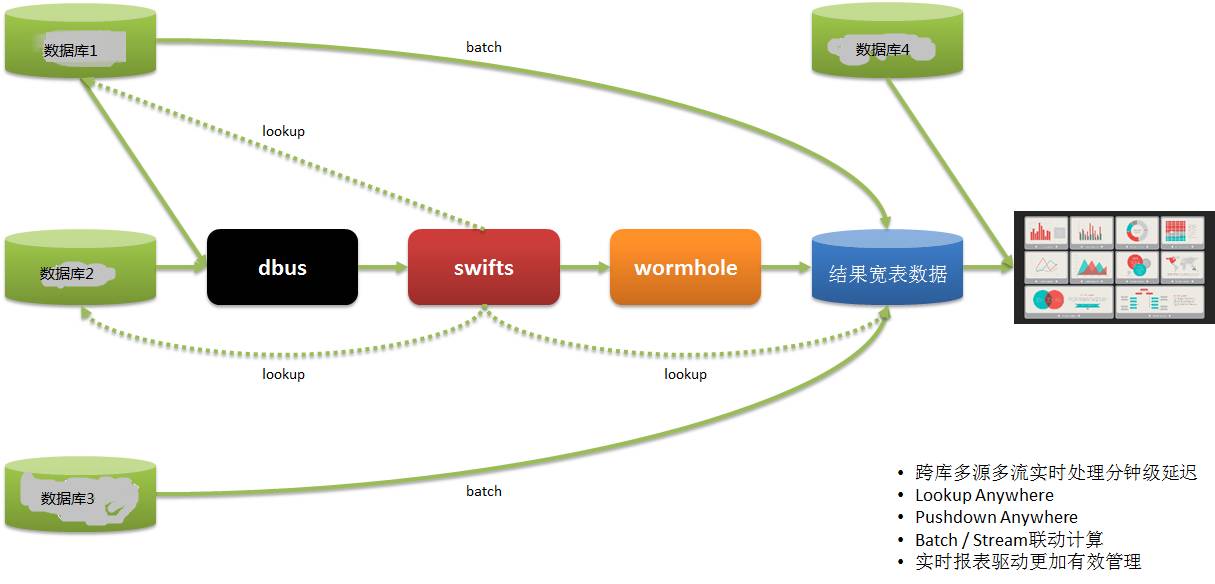
Les données de nos utilisateurs proviennent de plusieurs systèmes. Dans le passé, nous utilisions T+1 pour obtenir des informations de rapport, puis guider les opérations du lendemain, ce qui entraînait un manque de rapidité.
Grâce à DWS, les données sont extraites de plusieurs systèmes en temps réel, calculées et mises en œuvre, et des rapports sont fournis, afin que les opérations puissent effectuer un déploiement et des ajustements en temps opportun et réagir rapidement.
Cela dit, permettez-moi de le résumer grossièrement :
- La technologie DWS est basée sur le cadre technologique traditionnel du Big Data de streaming en temps réel, avec une haute disponibilité, un débit important, une forte expansion horizontale, une faible latence et une tolérance aux pannes élevée, et est finalement cohérente.
- Les capacités DWS prennent en charge des systèmes multi-sources et multi-cibles hétérogènes, plusieurs formats de données (données structurées, semi-structurées et non structurées) et des capacités techniques en temps réel.
- DWS combine trois sous-projets et les lance comme une seule plateforme, nous offrant des capacités en temps réel pour piloter diverses applications de scénarios en temps réel.
Les scénarios appropriés incluent : Synchronisation en temps réel/calcul en temps réel/surveillance en temps réel/rapports en temps réel/analyse en temps réel/informations en temps réel/gestion en temps réel/opération en temps réel/temps réel prise de décision
Merci à tous pour votre écoute, ce partage se termine ici.
Q1 : Existe-t-il une solution open source pour le lecteur de journaux Oracle ?
A1 : Il existe également de nombreuses solutions commerciales pour l'industrie Oracle, telles que : Oracle GoldenGate (Goldengate d'origine), Oracle Xstream, IBM InfoSphere Change Data Capture (DataMirror d'origine), Dell SharePlex (Quest d'origine), DSG superSync Wait domestique , il existe très peu de solutions open source faciles à utiliser.
Q2 : Combien de ressources humaines et matérielles ont été investies dans ce projet ? Cela semble un peu compliqué.
Q2 : DWS est composé de trois sous-projets, avec une moyenne de 5 à 7 personnes par projet. C'est un peu compliqué, mais il s'agit en fait d'une tentative d'utiliser la technologie du Big Data pour résoudre les difficultés que notre entreprise rencontre actuellement.
Parce que nous sommes engagés dans les technologies liées au Big Data, tous les frères et sœurs de l'équipe sont très heureux :)
En fait, Dbus et Wormhole sont des modèles relativement fixes et faciles à réutiliser. L'informatique en temps réel de Swift est liée à chaque entreprise, a une forte personnalisation et est relativement gênante.
Q3 : Le système DWS de CreditEase sera-t-il open source ?
A3 : Nous avons également envisagé de contribuer à la communauté. Tout comme d'autres projets open source de Yixin, le projet vient de prendre forme et doit être développé davantage. Je pense que nous l'ouvrirons à un moment donné dans le futur.
Q4 : Comment comprenez-vous un architecte ? Est-il un ingénieur système ?
A4 : Pas un ingénieur système. Nous avons plusieurs architectes chez CreditEase. Ils doivent être considérés comme des responsables techniques qui dirigent les affaires avec la technologie. Y compris la conception du produit, la gestion technique, etc.
Q5 : Le schéma de réplication est-il OGG ?
A5 : OGG et les autres solutions commerciales mentionnées ci-dessus sont des options.
Source de l'article : communauté DBAplus (dbaplus)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!