
Maison >Tutoriel système >Linux >Optimisez l'efficacité de l'accès aux données HDFS : utilisez la chaleur et le froid des données pour gérer
Optimisez l'efficacité de l'accès aux données HDFS : utilisez la chaleur et le froid des données pour gérer

- 王林avant
- 2024-01-15 09:18:151477parcourir
Introduction au thème :
- Explication de la fonction de stockage optimisée HDFS
- Conception de l'architecture du système SSM
- Analyse du scénario d'application du système SSM
Avec le développement et la vulgarisation des technologies liées à la technologie du Big Data, de plus en plus d'entreprises commencent à utiliser des systèmes de plateforme basés sur Hadoop open source. Dans le même temps, de plus en plus d'entreprises et d'applications migrent de l'architecture technique traditionnelle vers le Big Data. plates-formes supérieures. Dans une plate-forme Big Data Hadoop typique, les utilisateurs utilisent HDFS comme noyau des services de stockage.
Au début du développement du Big Data, le scénario d'application principal était encore le scénario de traitement par lots hors ligne, et la demande de stockage était la recherche du débit. HDFS a été conçu pour de tels scénarios, et avec le développement continu de la technologie, de plus en plus. De plus en plus de scénarios mettront en avant de nouvelles exigences en matière de stockage, et HDFS est également confronté à de nouveaux défis. Cela comprend principalement plusieurs aspects :
1. Problème de volume de donnéesD'une part, avec la croissance de l'activité et l'accès à de nouvelles applications, davantage de données seront introduites dans HDFS. D'autre part, avec le développement du deep learning, de l'intelligence artificielle et d'autres technologies, les utilisateurs espèrent généralement sauvegarder des données. pendant une période plus longue, pour améliorer l’effet de l’apprentissage en profondeur. L'augmentation rapide de la quantité de données obligera le cluster à être continuellement confronté à des besoins d'expansion, ce qui entraînera une augmentation des coûts de stockage.
2. Petit problème de fichierComme nous le savons tous, HDFS est conçu pour le traitement par lots hors ligne de fichiers volumineux. Le traitement de petits fichiers n'est pas un scénario dans lequel le HDFS traditionnel est bon. La cause première du problème des petits fichiers HDFS est que les informations de métadonnées du fichier sont conservées dans la mémoire d'un seul Namenode et que l'espace mémoire d'une seule machine est toujours limité. On estime que le nombre maximum de fichiers système qu'un seul cluster de nœuds de noms peut accueillir est d'environ 150 millions. En fait, la plate-forme HDFS sert généralement de plate-forme de stockage sous-jacente pour servir plusieurs cadres informatiques de couche supérieure et plusieurs scénarios commerciaux, de sorte que le problème des petits fichiers est inévitable d'un point de vue commercial. Il existe actuellement des solutions telles que HDFS-Federation pour résoudre le problème d'évolutivité à point unique de Namenode, mais en même temps, cela entraînera également d'énormes difficultés dans la gestion de l'exploitation et de la maintenance.
3. Problème de données chaudes et froidesÀ mesure que la quantité de données continue de croître et de s'accumuler, les données montreront également d'énormes différences en termes de popularité d'accès. Par exemple, une plate-forme écrira en permanence les données les plus récentes, mais les données récemment écrites seront généralement consultées beaucoup plus fréquemment que les données écrites il y a longtemps. Si la même stratégie de stockage est utilisée, que les données soient chaudes ou froides, cela constitue un gaspillage de ressources du cluster. Comment optimiser le système de stockage HDFS en fonction de la chaleur et du froid des données est un problème urgent qui doit être résolu.
2. Technologie d'optimisation HDFS existanteCela fait plus de 10 ans depuis la naissance de Hadoop. Au cours de cette période, la technologie HDFS elle-même a été continuellement optimisée et évoluée. HDFS dispose de certaines technologies existantes qui peuvent résoudre dans une certaine mesure certains des problèmes ci-dessus. Voici une brève introduction au stockage hétérogène HDFS et à la technologie de codage d’effacement HDFS.
Stockage hétérogène HDFS :Hadoop prend en charge les fonctions de stockage hétérogènes à partir de la version 2.6.0. Nous savons que la stratégie de stockage par défaut de HDFS utilise trois copies de chaque bloc de données et les stocke sur des disques sur différents nœuds. Le rôle du stockage hétérogène est d'utiliser différents types de supports de stockage sur le serveur (y compris le disque dur HDD, le SSD, la mémoire, etc.) pour fournir davantage de stratégies de stockage (par exemple, trois copies, une est stockée sur le support SSD, et les deux autres sont toujours stockés sur le disque dur HDD), rendant ainsi le stockage HDFS plus flexible et plus efficace pour répondre à divers scénarios d'application.
Divers stockages prédéfinis pris en charge dans HDFS incluent :
-
ARCHIVE : Les supports de stockage à haute densité de stockage mais à faible consommation d'énergie, tels que les bandes, sont généralement utilisés pour stocker des données froides
-
DISK : support de disque, il s'agit du premier support de stockage pris en charge par HDFS
-
SSD : le disque SSD est un nouveau type de support de stockage actuellement utilisé par de nombreuses sociétés Internet
-
RAM_DISK : les données sont écrites dans la mémoire et une autre copie sera écrite (de manière asynchrone) sur le support de stockage en même temps
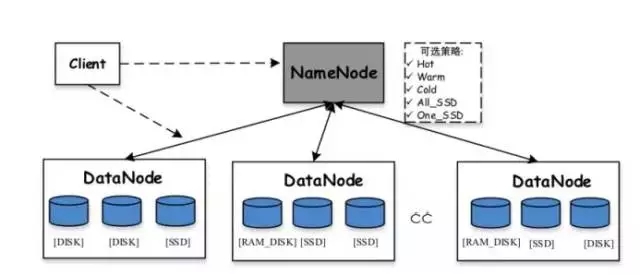
Les stratégies de stockage prises en charge dans HDFS incluent :
-
Lazy_persist : une copie est conservée dans la mémoire RAM_DISK et les copies restantes sont enregistrées sur le disque
-
ALL_SSD : toutes les copies sont enregistrées sur SSD
-
One_SSD : une copie est enregistrée sur SSD et les copies restantes sont enregistrées sur le disque
-
Chaud : toutes les copies sont enregistrées sur le disque, ce qui est également la politique de stockage par défaut
-
Chaud : une copie est enregistrée sur le disque, les copies restantes sont enregistrées sur le stockage d'archives
-
Froid : toutes les copies sont conservées dans des archives
En général, l'intérêt du stockage hétérogène HDFS réside dans l'adoption de différentes stratégies en fonction de la popularité des données pour améliorer l'efficacité globale de l'utilisation des ressources du cluster. Pour les données fréquemment consultées, enregistrez-les tout ou partie sur des supports de stockage (mémoire ou SSD) avec des performances d'accès plus élevées pour améliorer leurs performances en lecture et en écriture ; pour les données rarement consultées, enregistrez-les sur des supports de stockage d'archives pour réduire leurs performances en lecture et écriture ; performances. Cependant, la configuration du stockage hétérogène HDFS nécessite que les utilisateurs spécifient les politiques correspondantes pour les répertoires, c'est-à-dire que les utilisateurs doivent connaître à l'avance la popularité d'accès aux fichiers dans chaque répertoire. Dans les applications réelles de la plate-forme Big Data, cela est plus difficile.
Code d'effacement HDFS :Les données HDFS traditionnelles utilisent un mécanisme à trois copies pour garantir la fiabilité des données. Autrement dit, pour chaque 1 To de données stockées, les données réelles occupées sur chaque nœud du cluster atteignent 3 To, avec une surcharge supplémentaire de 200 %. Cela exerce une forte pression sur le stockage sur disque des nœuds et sur la transmission réseau.
Hadoop 3.0 a commencé à introduire la prise en charge du codage d'effacement au niveau des blocs de fichiers HDFS, et la couche sous-jacente utilise l'algorithme Reed-Solomon (k, m). RS est un algorithme de codage d'effacement couramment utilisé. Grâce à des opérations matricielles, des chiffres de contrôle de m bits peuvent être générés pour les données de k bits, différents degrés de tolérance aux pannes peuvent être obtenus. méthode relativement flexible.
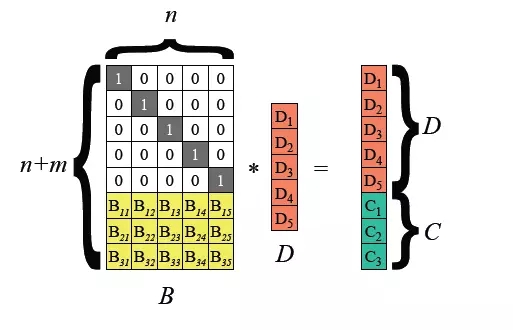
Les algorithmes courants sont RS(3,2), RS(6,3), RS(10,4), k blocs de fichiers et m blocs de contrôle forment un groupe, et n'importe quel m blocs de données peut être toléré dans ce groupe de perte.
La technologie de codage d'effacement HDFS peut réduire la redondance du stockage des données. En prenant RS(3,2) comme exemple, sa redondance des données est de 67 %, ce qui est considérablement réduit par rapport aux 200 % par défaut de Hadoop. Cependant, la technologie de codage d'effacement nécessite la consommation de CPU pour le stockage et la récupération des données. Il s'agit en fait d'un choix d'échange de temps contre de l'espace. Par conséquent, le scénario le plus applicable est le stockage de données froides. Les données stockées dans les données froides ne sont souvent pas accessibles pendant une longue période après avoir été écrites une fois. Dans ce cas, la technologie de codage d'effacement peut être utilisée pour réduire le nombre de copies. 3. Optimisation du stockage Big Data : SSM
Qu'il s'agisse de stockage hétérogène HDFS ou de technologie de codage d'effacement introduite plus tôt, le principe est que les utilisateurs doivent spécifier un comportement de stockage pour des données spécifiques, ce qui signifie que les utilisateurs doivent savoir quelles données sont des données chaudes et lesquelles sont des données froides. Alors, existe-t-il un moyen d’optimiser automatiquement le stockage ?La réponse est oui. Le système SSM (Smart Storage Management) présenté ici obtient des informations de métadonnées du stockage sous-jacent (généralement HDFS) et obtient l'état de chaleur des données grâce à l'analyse des informations d'accès en lecture et en écriture, en ciblant les données avec différents niveaux de chaleur. selon une série de règles préétablies, adopter des stratégies d'optimisation du stockage correspondantes pour améliorer l'efficacité de l'ensemble du système de stockage. SSM est un projet open source dirigé par Intel, et China Mobile participe également à sa recherche et développement. Le projet peut être obtenu sur Github : https://github.com/Intel-bigdata/SSM.
Le positionnement SSM est un système d'optimisation des périphériques de stockage qui adopte une architecture Serveur-Agent-Client dans son ensemble. Le Serveur est responsable de la mise en œuvre de la logique globale de SSM, l'Agent est utilisé pour effectuer diverses opérations sur le cluster de stockage, et le Client est l'accès aux données fourni aux utilisateurs, comprenant généralement l'interface HDFS native.
Le cadre principal de SSM-Server est illustré dans la figure ci-dessus. De haut en bas, StatesManager interagit avec le cluster HDFS pour obtenir les informations de métadonnées HDFS et conserver les informations de chaleur d'accès de chaque fichier. Les informations dans StatesManager seront conservées dans la base de données relationnelle. TiDB est utilisé comme base de données de stockage sous-jacente dans SSM. RuleManager conserve et gère les informations relatives aux règles. Les utilisateurs définissent une série de règles de stockage pour SSM via l'interface frontale, et RuleManger est responsable de l'analyse et de l'exécution des règles. CacheManager/StorageManager génère des tâches d'action spécifiques en fonction de la popularité et des règles. ActionExecutor est responsable de tâches d'action spécifiques, attribue des tâches aux agents et les exécute sur les nœuds d'agent. 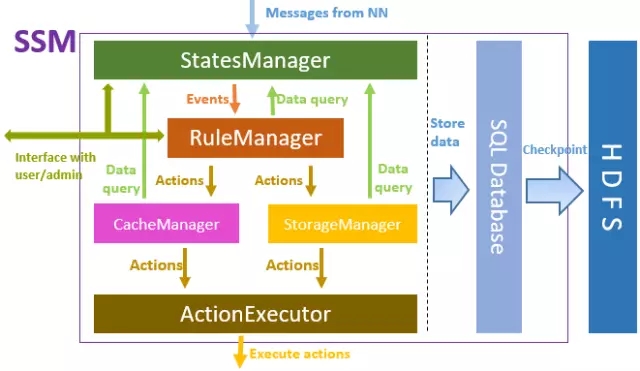
La mise en œuvre de la logique interne de SSM-Server repose sur la définition de règles, ce qui oblige l'administrateur à formuler une série de règles pour le système SSM via la page Web frontale. Une règle se compose de plusieurs parties : 
- Les objets d'opération font généralement référence à des fichiers qui répondent à des conditions spécifiques.
- Le déclencheur fait référence au moment où la règle est déclenchée, comme un déclencheur programmé chaque jour.
- Conditions d'exécution, définissent une série de conditions basées sur la popularité, telles que les exigences en matière de nombre d'accès aux fichiers sur une période donnée.
- Exécuter des opérations, effectuer des opérations associées sur des données qui répondent aux conditions d'exécution, en spécifiant généralement sa stratégie de stockage, etc.
Un exemple de règle réelle :
file.path correspond à «/foo/*» : accessCount(10min) >= 3 | one-ssd
Cette règle signifie que pour les fichiers du répertoire /foo, s'ils sont consultés au moins trois fois en 10 minutes, la stratégie de stockage One-SSD sera adoptée, c'est-à-dire qu'une copie des données sera stockée sur le SSD. , et les 2 copies restantes seront utilisées.
4. Scénarios d'application SSMSSM peut utiliser différentes stratégies de stockage pour optimiser la chaleur et la froideur des données. Voici quelques scénarios d'application typiques :
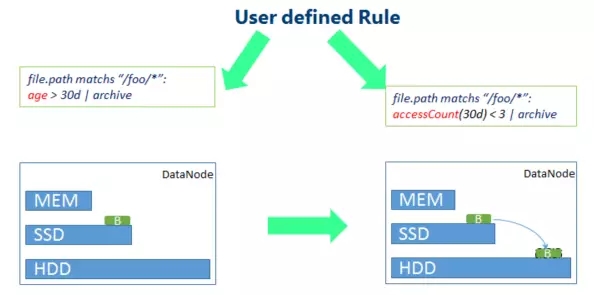
Le scénario le plus typique concerne les données froides, comme le montre la figure ci-dessus, définissez des règles pertinentes et utilisez un stockage à moindre coût pour les données qui n'ont pas été consultées depuis longtemps. Par exemple, les blocs de données d'origine sont dégradés du stockage SSD vers le stockage HDD.
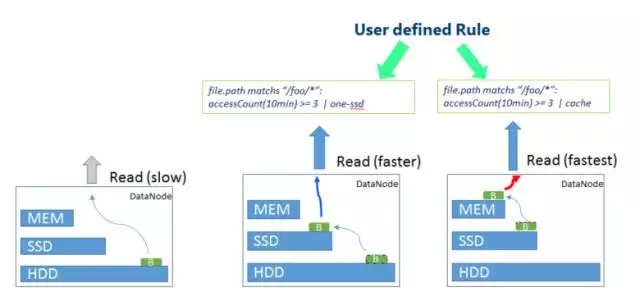
De même, pour les données de point d'accès, une stratégie de stockage plus rapide peut également être adoptée selon différentes règles. Comme le montre la figure ci-dessus, accéder à davantage de données de point d'accès ici dans un court laps de temps augmentera davantage le stockage du disque dur au stockage SSD. les données chaudes utiliseront la stratégie de stockage en mémoire.
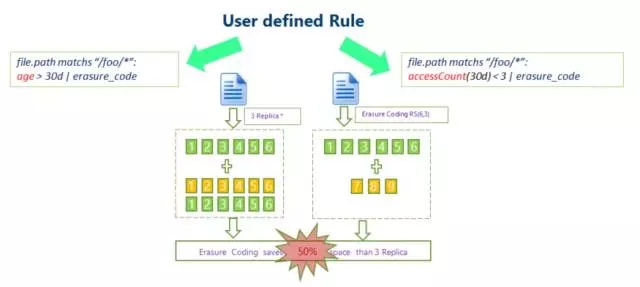
Pour les scénarios de données froides, SSM peut également utiliser l'optimisation du codage d'effacement. En définissant des règles correspondantes, les opérations de code d'effacement sont effectuées sur des données froides avec peu d'accès pour réduire la redondance de la copie des données.

Il convient également de mentionner que SSM dispose également de méthodes d'optimisation correspondantes pour les petits fichiers. Cette fonctionnalité est encore en cours de développement. La logique générale est que SSM fusionnera une série de petits fichiers sur HDFS en gros fichiers. En même temps, la relation de mappage entre les petits fichiers d'origine et les gros fichiers fusionnés et l'emplacement de chaque petit fichier dans le gros fichier seront. enregistré dans les métadonnées du décalage SSM. Lorsque l'utilisateur a besoin d'accéder à un petit fichier, le petit fichier d'origine est obtenu à partir du fichier fusionné via le client spécifique à SSM (SmartClient) sur la base des informations de mappage de petit fichier dans les métadonnées SSM.
Enfin, SSM est un projet open source et est toujours en processus d'évolution itérative très rapide. Tous les amis intéressés sont invités à contribuer au développement du projet.
Questions et réponsesQ1 : À quelle échelle devrions-nous commencer lorsque nous construisons nous-mêmes HDFS ?
A1 : HDFS prend en charge le mode pseudo-distribution Même s'il n'y a qu'un seul nœud, vous pouvez créer un système HDFS. Si vous souhaitez mieux découvrir et comprendre l'architecture distribuée de HDFS, il est recommandé de créer un environnement avec 3 à 5 nœuds.
Q2 : Su Yan a-t-elle utilisé le SSM dans la plate-forme Big Data actuelle de chaque province ?
A2 : Pas encore. Ce projet se développe encore rapidement. Il sera progressivement utilisé en production une fois les tests stables.
Q3 : Quelle est la différence entre HDFS et Spark ? Quels sont les avantages et inconvénients?
A3 : HDFS et Spark ne sont pas des technologies au même niveau. HDFS est un système de stockage, tandis que Spark est un moteur de calcul. Ce que nous comparons souvent avec Spark est le framework informatique Mapreduce dans Hadoop plutôt que le système de stockage HDFS. Dans la construction réelle d'un projet, HDFS et Spark entretiennent généralement une relation de collaboration. HDFS est utilisé pour le stockage sous-jacent et Spark est utilisé pour le calcul de niveau supérieur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!