Récemment, les algorithmes basés sur Transformer ont été largement utilisés dans diverses tâches de vision par ordinateur, mais ce type d'algorithme est sujet à des problèmes de surajustement lorsque la quantité de données d'entraînement est faible. Les transformateurs de vision existants introduisent généralement directement l'algorithme d'abandon couramment utilisé dans CNN comme régulateur, qui effectue des baisses aléatoires sur la carte de poids d'attention et définit une probabilité de baisse unifiée pour les couches d'attention de différentes profondeurs. Bien que Dropout soit très simple, cette méthode de drop présente trois problèmes principaux. Tout d'abord, une chute aléatoire après la normalisation softmax brisera la distribution de probabilité des poids d'attention et ne parviendra pas à pénaliser les pics de poids, ce qui entraînera un surajustement du modèle aux informations spécifiques locales (Figure 1). Deuxièmement, une probabilité de chute plus grande dans les couches plus profondes du réseau entraînera un manque d'informations sémantiques de haut niveau, tandis qu'une probabilité de chute plus faible dans les couches moins profondes conduira à un surajustement des caractéristiques détaillées sous-jacentes, donc une probabilité de chute constante conduire à une instabilité dans le processus de formation. Enfin, l’efficacité de la méthode de dépôt structuré couramment utilisée sur CNN sur Vision Transformer n’est pas claire. 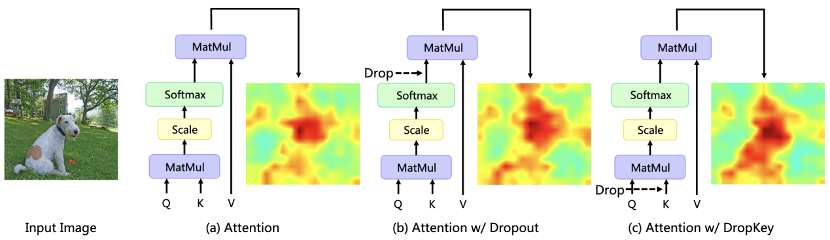
Figure 1 L'impact de différents régularisateurs sur la carte de distribution de l'attention Le Meitu Imaging Research Institute (MT Lab) et l'Université de l'Académie chinoise des sciences ont publié un article sur le CVPR 2023, un nouveau régulateur plug-and-play DropKey est proposé, qui peut atténuer efficacement le problème de surajustement dans Vision Transformer. 
Lien papier : https://arxiv.org/abs/2208.02646Les trois questions fondamentales suivantes sont étudiées dans l'article : Tout d'abord, que faut-il faire dans la couche d'attention ? effectuer une opération Drop ? Différente de la suppression directe du poids d'attention, cette méthode effectue l'opération Drop avant de calculer la matrice d'attention et utilise la clé comme unité de base Drop. Cette méthode vérifie théoriquement que le régulariseur DropKey peut pénaliser les zones nécessitant une attention élevée et attribuer des pondérations d'attention à d'autres zones d'intérêt, améliorant ainsi la capacité du modèle à capturer des informations globales. Deuxièmement, comment définir la probabilité de chute ? Comparé à toutes les couches partageant la même probabilité de chute, cet article propose une nouvelle méthode de définition de la probabilité de chute, qui atténue progressivement la valeur de probabilité de chute à mesure que la couche d'auto-attention s'approfondit. Troisièmement, est-il nécessaire d'effectuer des opérations Drop structurées comme CNN ? Cette méthode a essayé une approche de dépôt structuré basée sur des fenêtres de bloc et des fenêtres croisées, et a constaté que cette technique n'était pas importante pour le Vision Transformer. Vision Transformer (ViT) est un nouveau paradigme dans les modèles récents de vision par ordinateur. Il est largement utilisé dans des tâches telles que la reconnaissance d'images, la segmentation d'images, la détection de points clés humains et la détection mutuelle de. les gens. Plus précisément, ViT divise l'image en un nombre fixe de blocs d'image, traite chaque bloc d'image comme une unité de base et introduit un mécanisme d'auto-attention multi-têtes pour extraire des informations sur les caractéristiques contenant des relations mutuelles. Cependant, les méthodes de type ViT existantes souffrent souvent de problèmes de surajustement sur de petits ensembles de données, c'est-à-dire qu'elles n'utilisent que les fonctionnalités locales de la cible pour accomplir des tâches spécifiées. Afin de surmonter les problèmes ci-dessus, cet article propose un régulariseur plug-and-play DropKey qui peut être implémenté en seulement deux lignes de code pour atténuer le problème de surajustement de la méthode de classe ViT. Différent du Dropout existant, DropKey définit la clé sur l'objet déposé et a vérifié théoriquement et expérimentalement que ce changement peut punir les parties avec des valeurs d'attention élevées tout en encourageant le modèle à accorder plus d'attention aux autres patchs d'image liés à la cible, ce qui est utile pour capturer des fonctionnalités globales robustes. En outre, l'article propose également de définir des probabilités de suppression décroissantes pour des couches d'attention de plus en plus approfondies, ce qui peut éviter que le modèle ne surajuste les fonctionnalités de bas niveau tout en garantissant suffisamment de fonctionnalités de haut niveau pour un entraînement stable. De plus, l’article prouve expérimentalement que la méthode des gouttes structurées n’est pas nécessaire pour ViT. Afin d'explorer les raisons essentielles à l'origine du problème de surapprentissage, cette recherche a d'abord formalisé le mécanisme d'attention en un objectif d'optimisation simple et analysé sa forme d'expansion lagrangienne. Il a été constaté que lorsque le modèle est continuellement optimisé, les zones d'image avec une plus grande proportion d'attention dans l'itération actuelle auront tendance à se voir attribuer un poids d'attention plus important lors de l'itération suivante. Pour atténuer ce problème, DropKey attribue implicitement un opérateur adaptatif à chaque bloc d'attention en supprimant aléatoirement une partie de la clé pour contraindre la distribution de l'attention et la rendre plus fluide. Il convient de noter que par rapport à d'autres régulariseurs conçus pour des tâches spécifiques, DropKey ne nécessite aucune conception manuelle. Étant donné que des suppressions aléatoires sont effectuées sur Key pendant la phase de formation, ce qui entraînera des attentes de sortie incohérentes dans les phases de formation et de test, cette méthode propose également d'utiliser des méthodes de Monte Carlo ou des techniques de réglage fin pour aligner les attentes de sortie. De plus, la mise en œuvre de cette méthode ne nécessite que deux lignes de code, comme le montre la figure 2. 
Figure 2 Méthode d'implémentation de DropKeyDe manière générale, ViT superpose plusieurs couches d'attention pour apprendre progressivement des fonctionnalités de grande dimension. En règle générale, les couches moins profondes extraient des caractéristiques visuelles de faible dimension, tandis que les couches profondes visent à extraire des informations grossières mais complexes sur l'espace de modélisation. Par conséquent, cette étude tente de définir une probabilité de chute plus faible pour les couches profondes afin d'éviter de perdre des informations importantes sur l'objet cible. Plus précisément, DropKey n'effectue pas de suppressions aléatoires avec une probabilité fixe sur chaque couche, mais réduit progressivement la probabilité de suppression à mesure que le nombre de couches augmente. De plus, l'étude a révélé que cette approche fonctionne non seulement avec DropKey, mais améliore également considérablement les performances de Dropout. Bien que la méthode de dépôt structuré ait été étudiée en détail dans CNN, l'impact sur les performances de cette méthode de dépôt sur ViT n'a pas été étudié. Pour déterminer si cette stratégie améliorera encore les performances, l'article implémente deux formes structurées de DropKey, à savoir DropKey-Block et DropKey-Cross. Parmi eux, DropKey-Block supprime la zone continue dans la fenêtre carrée centrée sur le point de départ, et DropKey-Cross supprime la zone continue en forme de croix centrée sur le point de départ, comme le montre la figure 3. Cependant, l’étude a révélé que l’approche de suppression structurée n’entraînait pas d’amélioration des performances. 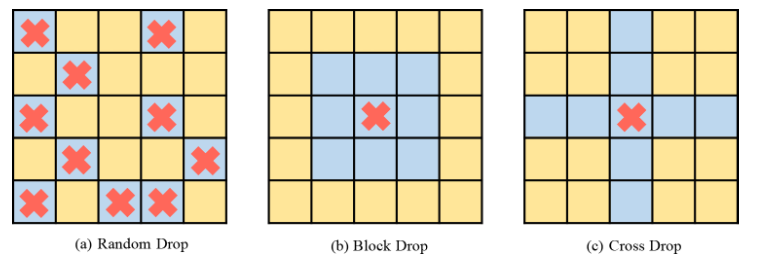
Figure 3 Méthode de mise en œuvre structurée de DropKey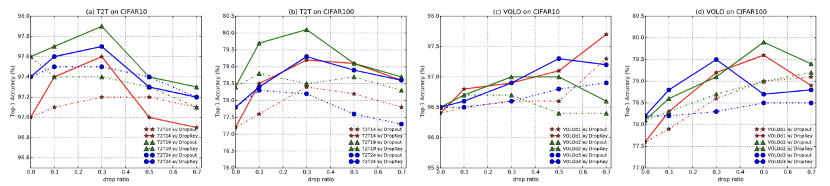
Figure 4 Comparaison des performances de DropKey et Drop out sur CIFAR10/100 
Figure 5 Comparaison des effets de visualisation de la carte d'attention de DropKey et Dropout sur CIFAR100
Figure 6 Comparaison des performances de différentes stratégies de définition de probabilité de chute Figure 7 Comparaison des performances de différentes stratégies d'alignement des attentes de sortie
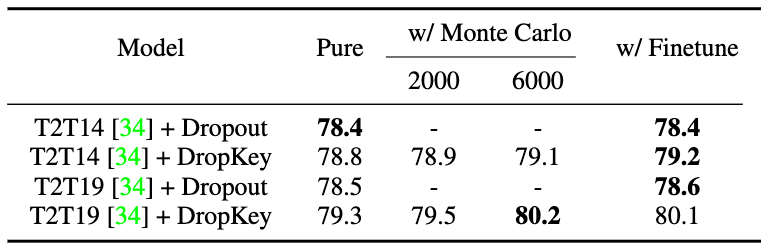
Image 9 Comparaison des performances de DropKey et Dropout sur ImageNet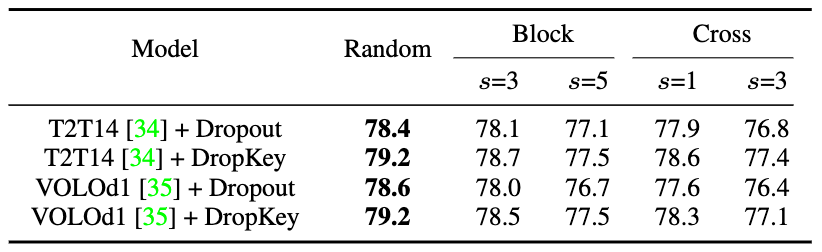
Figure 10 Comparaison des performances de DropKey et Dropout sur COCO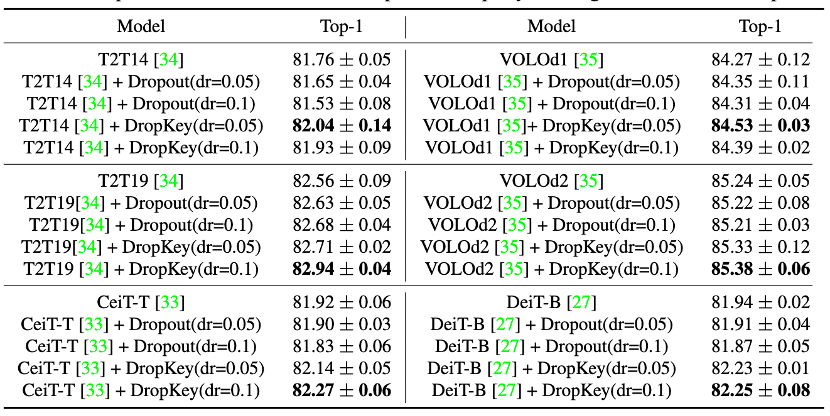
Image 11 Comparaison des performances de DropKey et Dropout sur HICO-DET
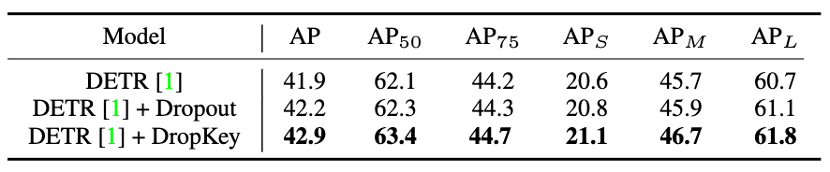
Figure 12 Comparaison des performances de DropKey et Dropout sur HICO-DET 
Figure 13 Comparaison visuelle des cartes d'attention entre DropKey et Dropout sur HICO-DETCet article propose de manière innovante un régulariseur pour ViT, utilisé pour atténuer le surajustement problème de ViT. Par rapport aux régulariseurs existants, cette méthode peut fournir une répartition fluide de l'attention pour la couche d'attention en définissant simplement Key comme objet de dépôt. En outre, l'article propose également une nouvelle stratégie de définition de probabilité de chute, qui stabilise avec succès le processus de formation tout en atténuant efficacement le surapprentissage. Enfin, l'article explore également l'impact des méthodes de dépôt structuré sur les performances du modèle. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

