
Maison >Périphériques technologiques >IA >Le nouveau cadre d'intégration de connaissances spatio-temporelles de l'Université Sun Yat-sen est à l'origine des dernières avancées en matière de tâches de génération de graphes de scènes vidéo, publiées dans TIP '24
Le nouveau cadre d'intégration de connaissances spatio-temporelles de l'Université Sun Yat-sen est à l'origine des dernières avancées en matière de tâches de génération de graphes de scènes vidéo, publiées dans TIP '24

- 王林avant
- 2024-01-14 15:48:21898parcourir
Video Scene Graph Generation (VidSGG) vise à identifier les objets dans des scènes visuelles et à déduire des relations visuelles entre eux.
Cette tâche nécessite non seulement une compréhension globale de chaque objet dispersé dans la scène, mais également une étude approfondie de leur mouvement et de leur interaction au fil du temps.
Récemment, des chercheurs de l'Université Sun Yat-sen ont publié un article dans la revue de référence sur l'intelligence artificielle IEEE T-IP. Ils ont exploré des tâches connexes et ont découvert que : chaque paire de combinaisons d'objets et leurs relations se trouvent dans chacune. -corrélation d'occurrences au sein des images et corrélation de cohérence temporelle/traduction entre différentes images.

Lien papier : https://arxiv.org/abs/2309.13237
Sur la base de ces connaissances préalables, les chercheurs ont proposé un transformateur (STKET) basé sur l'intégration des connaissances spatio-temporelles pour intégrer les connaissances spatio-temporelles préalables. Les connaissances sont incorporées dans un mécanisme d'attention croisée multi-têtes pour apprendre des représentations de relations visuelles plus représentatives.
Plus précisément, les corrélations de cooccurrence spatiale et de transformation temporelle sont d'abord apprises statistiquement ; ensuite, une couche d'intégration de connaissances spatio-temporelles est conçue pour explorer pleinement l'interaction entre la représentation visuelle et la connaissance, et générer respectivement des intégrations de connaissances spatiales et temporelles. représentation ; enfin, les auteurs agrègent ces caractéristiques pour prédire les étiquettes sémantiques finales et leurs relations visuelles.
Un grand nombre d'expériences montrent que le framework proposé dans cet article est nettement meilleur que les algorithmes concurrents actuels. Actuellement, le document a été accepté.
Présentation de l'article
Avec le développement rapide du domaine de la compréhension des scènes, de nombreux chercheurs ont commencé à essayer d'utiliser divers cadres pour résoudre la tâche de génération de graphes de scène (SGG) et ont fait de bons progrès.
Cependant, ces méthodes ne considèrent souvent qu'une seule image et ignorent la grande quantité d'informations contextuelles existant dans la série temporelle, ce qui empêche la plupart des algorithmes de génération de graphiques de scène existants d'identifier avec précision le contenu contenu dans une dynamique donnée. relation visuelle.
Par conséquent, de nombreux chercheurs se sont engagés à développer des algorithmes de génération de graphiques de scènes vidéo (VidSGG) pour résoudre ce problème.
Les travaux actuels se concentrent principalement sur l'agrégation d'informations visuelles au niveau des objets à partir de perspectives spatiales et temporelles pour apprendre les représentations de relations visuelles correspondantes.
Cependant, en raison de la grande variation dans l'apparence visuelle de divers objets et actions interactives et de la distribution significative à longue traîne des relations visuelles provoquée par la collecte de vidéos, la simple utilisation d'informations visuelles seules peut facilement conduire le modèle à prédire des images visuelles incorrectes. des relations.
En réponse aux problèmes ci-dessus, les chercheurs ont réalisé les deux aspects de travail suivants :
Premièrement, il est proposé d'exploiter les connaissances spatio-temporelles préalables contenues dans des échantillons d'entraînement pour promouvoir le domaine de la génération de graphes de scènes vidéo. Parmi elles, les connaissances spatio-temporelles préalables comprennent :
1) Corrélation de cooccurrence spatiale : La relation entre certaines catégories d'objets tend vers des interactions spécifiques.
2) Cohérence temporelle/Corrélation de transition : une paire de relations donnée a tendance à être cohérente dans des clips vidéo consécutifs, ou a une forte probabilité de transition vers une autre relation spécifique.
Deuxièmement, un nouveau cadre Transformer (Spatial-Temporal Knowledge-Embedded Transformer, STKET) basé sur l'intégration de connaissances spatio-temporelles est proposé.
Ce cadre intègre des connaissances spatio-temporelles préalables dans le mécanisme d'attention croisée multi-têtes pour apprendre des représentations de relations visuelles plus représentatives. D'après les résultats de comparaison obtenus sur le benchmark de test, on peut constater que le cadre STKET proposé par les chercheurs surpasse les méthodes de pointe précédentes.

Figure 1 : En raison de l'apparence visuelle variable et de la distribution à longue traîne des relations visuelles, la génération de graphiques de scène vidéo est pleine de défis
Transformateur basé sur l'intégration de connaissances spatio-temporelles
Spatial et temporel représentation des connaissances
Dans Lorsqu'ils déduisent des relations visuelles, les humains utilisent non seulement des indices visuels, mais également des connaissances antérieures accumulées [1, 2]. Inspirés par cela, les chercheurs proposent d'extraire les connaissances spatio-temporelles préalables directement de l'ensemble de formation pour faciliter la tâche de génération de graphiques de scène vidéo.
Parmi eux, la corrélation de cooccurrence spatiale se manifeste spécifiquement en ce que lorsqu'un objet donné est combiné, sa distribution de relation visuelle sera très asymétrique (par exemple, la distribution de la relation visuelle entre « personne » et « tasse » est évidemment différent de "chien" et "chien"). La distribution entre "jouets") et la corrélation de transfert temporel se manifestent spécifiquement en ce que la probabilité de transition de chaque relation visuelle changera de manière significative lorsque la relation visuelle du moment précédent est donnée (par exemple Par exemple, lorsque l'on sait que la relation visuelle de l'instant précédent est "manger", la probabilité que la relation visuelle soit transférée vers "écrire" à l'instant suivant est fortement réduite).
Comme le montre la figure 2, une fois que vous pouvez ressentir intuitivement la combinaison d'objets donnée ou la relation visuelle précédente, l'espace de prédiction peut être considérablement réduit.
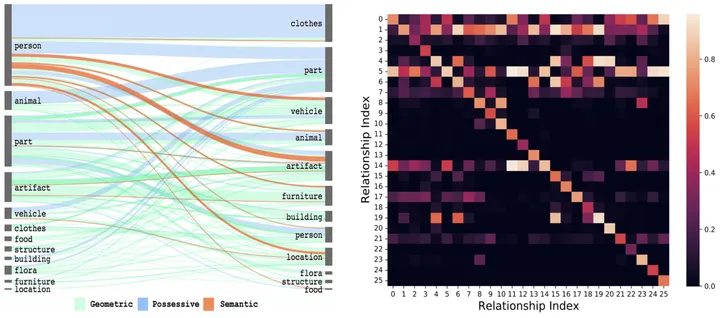
Figure 2 : Probabilité de cooccurrence spatiale [3] et probabilité de transition temporelle de la relation visuelle
Plus précisément, pour la combinaison de l'objet de type i et de l'objet de type j, et son moment précédent Pour le x-ème type de relation, obtenez d'abord sa matrice de probabilité de cooccurrence spatiale correspondante E^{i,j} et sa matrice de probabilité de transition temporelle Ex^{i,j} grâce aux statistiques.
Ensuite, saisissez-le dans la couche entièrement connectée pour obtenir la représentation des caractéristiques correspondante et utilisez la fonction objectif correspondante pour vous assurer que la représentation des connaissances apprise par le modèle contient les connaissances spatio-temporelles antérieures correspondantes.
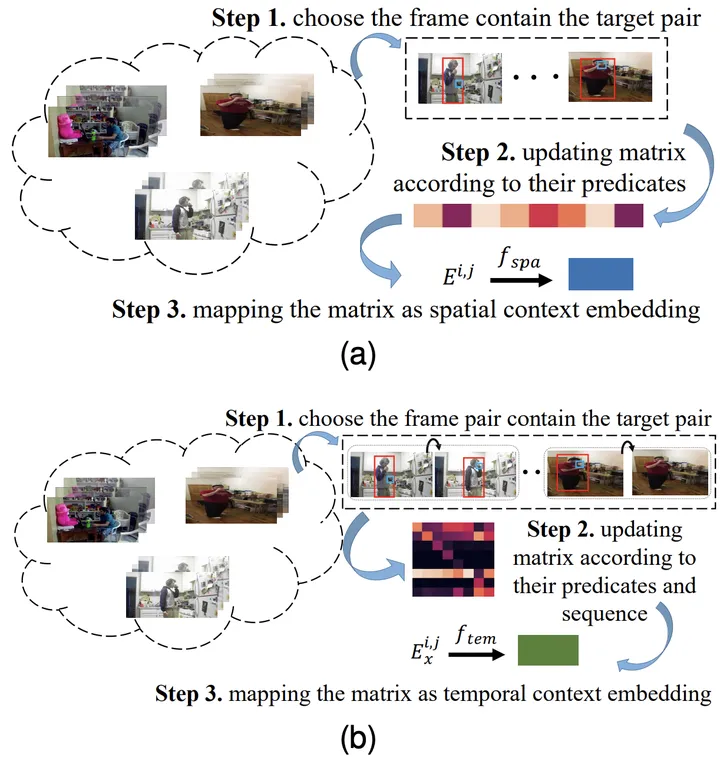
Figure 3 : Le processus d'apprentissage de la représentation des connaissances spatiales (a) et temporelles (b)
Couche d'attention intégrant les connaissances
Les connaissances spatiales contiennent généralement des informations sur l'emplacement, la distance et la relation entre les entités. . La connaissance temporelle, quant à elle, implique la séquence, la durée et les intervalles entre les actions.
Compte tenu de leurs propriétés uniques, les traiter individuellement peut permettre à une modélisation spécialisée de capturer plus précisément les motifs inhérents.
Par conséquent, les chercheurs ont conçu une couche d'intégration de connaissances spatio-temporelles pour explorer en profondeur l'interaction entre la représentation visuelle et les connaissances spatio-temporelles.
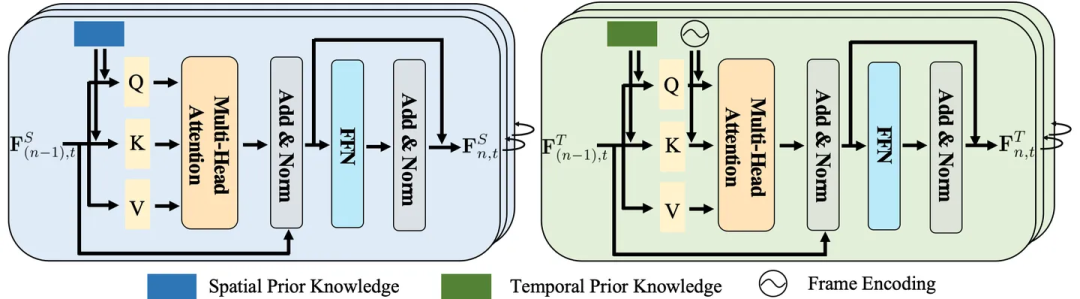
Figure 4 : Couche d'intégration de connaissances spatiales (à gauche) et temporelles (à droite)
Module d'agrégation spatio-temporelle
Comme mentionné précédemment, la couche d'intégration de connaissances spatiales explore la cohérence spatiale au sein de chaque image. La couche d'intégration des connaissances temporelles explore la corrélation de transfert temporel entre différentes images, explorant ainsi pleinement l'interaction entre la représentation visuelle et les connaissances spatio-temporelles.
Néanmoins, ces deux couches ignorent les informations contextuelles à long terme, ce qui est utile pour identifier les relations visuelles les plus dynamiques.
À cette fin, les chercheurs ont en outre conçu un module d'agrégation spatio-temporelle (STA) pour agréger ces représentations de chaque paire d'objets afin de prédire les étiquettes sémantiques finales et leurs relations. Il prend en entrée des représentations de relations spatiales et temporelles intégrées des mêmes paires sujet-objet dans différents cadres.
Plus précisément, les chercheurs concatènent ces représentations des mêmes paires d'objets pour générer des représentations contextuelles.
Ensuite, afin de trouver les mêmes paires sujet-objet dans différentes images, les étiquettes d'objet prédites et IoU (c'est-à-dire Intersection sur Union) sont adoptées pour correspondre aux mêmes paires sujet-objet détectées dans les images.
Enfin, étant donné que les relations dans les cadres ont des représentations différentes dans différents lots, la première représentation dans la fenêtre glissante est sélectionnée.
Résultats expérimentaux
Afin d'évaluer de manière globale les performances du cadre proposé, en plus de comparer les méthodes existantes de génération de graphes de scènes vidéo (STTran, TPI, APT), les chercheurs ont également sélectionné des méthodes avancées de génération de graphes de scènes d'images. (KERN, VCTREE, ReIDN, GPS-Net) à titre de comparaison.
Parmi eux, afin d'assurer une comparaison équitable, la méthode de génération de graphique de scène d'image atteint l'objectif de générer un graphique de scène correspondant pour une vidéo donnée en identifiant chaque image d'image.
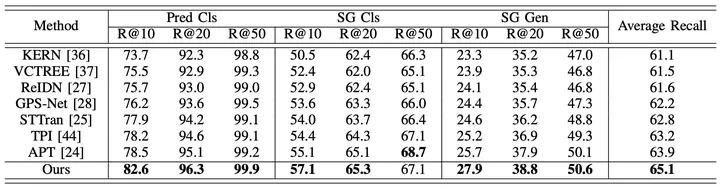
Figure 5 : Résultats expérimentaux utilisant Recall comme indice d'évaluation sur l'ensemble de données Action Genome

Figure 6 : Résultats expérimentaux utilisant le rappel moyen comme indice d'évaluation sur l'ensemble de données Action Genome
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Raisons pour lesquelles l'IA ne peut pas colorier en temps réel
- Comment utiliser vlookup d'Excel pour faire correspondre plusieurs colonnes de données à la fois
- Que dois-je faire si le texte WPS ne parvient pas à ouvrir la source de données ?
- Quelle est l'instruction SQL pour créer une base de données ?
- Quels sont les huit types de données de base ?