
Maison >Périphériques technologiques >IA >Meta lance un framework d'IA audio-image pour générer le doublage de scènes de dialogue de personnages
Meta lance un framework d'IA audio-image pour générer le doublage de scènes de dialogue de personnages

- PHPzavant
- 2024-01-13 11:39:061013parcourir
IT House News le 9 janvier, Meta a récemment annoncé un framework d'IA appelé audio2photoreal, qui peut générer une série de modèles de personnages PNJ réalistes et automatiquement « synchroniser les modèles de personnages à l'aide des fichiers de doublage existants ».


▲ Source de l'image Rapport de recherche Meta (le même ci-dessous)
IT House a appris du rapport de recherche officiel qu'après avoir reçu le fichier de doublage, le framework Audio2photoreal génère d'abord une série de modèles NPC, puis utilise la technologie de quantification et l'algorithme de diffusion pour générer des actions de modèle. Des algorithmes de diffusion sont utilisés pour améliorer les effets de mouvement des personnages générés par l'image.
Les chercheurs ont mentionné que le framework peut générer des « échantillons d'actions de haute qualité » à 30 FPS, et peut également simuler des « actions habituelles » involontaires d'humains telles que « pointer du doigt », « tourner les poignets » ou « hausser les épaules » pendant les conversations.


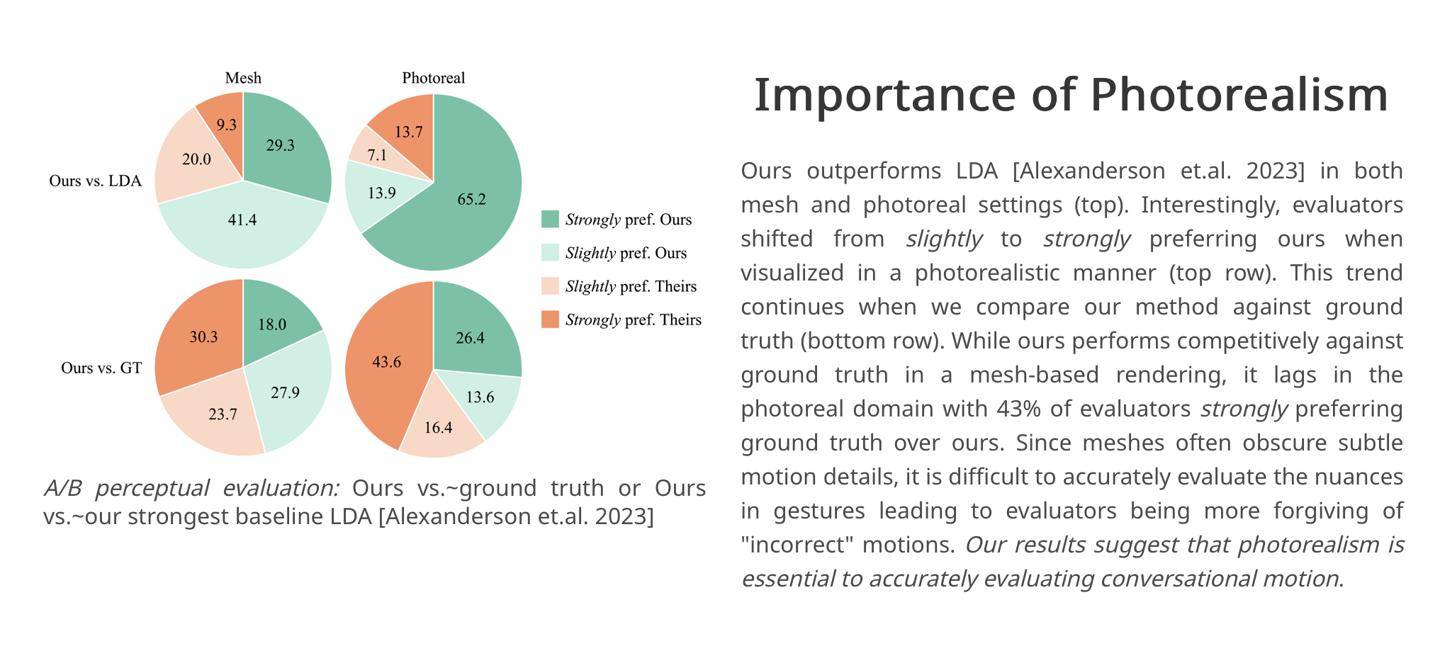
Les chercheurs ont cité leurs propres résultats expérimentaux. Dans l'expérience contrôlée, 43 % des évaluateurs étaient « fortement satisfaits » des scènes de dialogue des personnages générées par le cadre. Par conséquent, les chercheurs estiment que le cadre Audio2photoreal peut générer « plus de dynamisme et d'expression ». "par rapport aux produits concurrents de l'industrie. force".
Il est rapporté que l'équipe de recherche a maintenant divulgué le code et les ensembles de données pertinents sur GitHub. Les partenaires intéressés peuvent cliquer ici pour y accéder.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI