
Maison >Périphériques technologiques >IA >Modèle de prédiction de réponse de bout en bout sans modèle basé sur des tâches doubles
Modèle de prédiction de réponse de bout en bout sans modèle basé sur des tâches doubles

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-12 17:24:06666parcourir

Reformaté|
Lien papier : https://doi.org/10.1007/s10489-023-05048-8Code associé : https://github.com/AILBC/BiG2S L'auteur utilise un diagramme de l'essor actuel dans le domaine de la rétrosynthèse sans modèle. Sur la base du cadre du modèle de séquence, nous essayons en outre de construire un modèle BiG2S (Bidirectionnel Graph to Sequence) qui résout simultanément les tâches de prédiction de rétrosynthèse et de prédiction de réaction directe en un seul modèle à la même échelle de paramètres Dans le même temps, l'auteur étudie également l'inverse principal. Une analyse préliminaire a été menée sur l'ensemble de données synthétiques USPTO-50k pour explorer la différence de difficulté de prédiction des différents segments SMILES au cours du processus de formation et de la fluctuation. du taux de correspondance Top-k du modèle sur l'ensemble de validation. Une perte de déséquilibre a été introduite pour résoudre ces problèmes de fonction et des stratégies améliorées de recherche d'ensemble de modèles et de faisceaux
L'auteur utilise un diagramme de l'essor actuel dans le domaine de la rétrosynthèse sans modèle. Sur la base du cadre du modèle de séquence, nous essayons en outre de construire un modèle BiG2S (Bidirectionnel Graph to Sequence) qui résout simultanément les tâches de prédiction de rétrosynthèse et de prédiction de réaction directe en un seul modèle à la même échelle de paramètres Dans le même temps, l'auteur étudie également l'inverse principal. Une analyse préliminaire a été menée sur l'ensemble de données synthétiques USPTO-50k pour explorer la différence de difficulté de prédiction des différents segments SMILES au cours du processus de formation et de la fluctuation. du taux de correspondance Top-k du modèle sur l'ensemble de validation. Une perte de déséquilibre a été introduite pour résoudre ces problèmes de fonction et des stratégies améliorées de recherche d'ensemble de modèles et de faisceaux
Les premiers systèmes de planification rétrosynthétiques reposaient directement sur des informations fournies par des experts du domaine Règles de réaction, ou calculs basés sur la physico-chimie, avec le développement rapide du deep learning. La méthode dominante actuelle dans le domaine consiste à créer un cadre de réseau neuronal spécifique à une tâche pour mener à bien la tâche de prédiction des réactions dans une perspective basée sur les données. Parmi elles, la méthode sans modèle, qui ne repose pas sur des connaissances chimiques préalables spécifiques, est progressivement devenue l'une des principales directions de développement dans le domaine grâce à sa simplicité et sa flexibilité similaires à celles de la traduction automatique de bout en bout.
Actuellement, l'entrée et la sortie de la plupart des modèles rétrosynthétiques sans modèle sont des chaînes de molécules SMILES, c'est-à-dire utilisant un processus séquence à séquence (Seq2Seq). Cette méthode peut faire bon usage du cadre de modèle existant dans le domaine du traitement du langage naturel, ainsi que du flux de traitement de données mature pour la méthode de représentation SMILES. Cependant, puisque SMILES en tant que séquence de chaînes unidimensionnelle ne peut pas bien représenter et utiliser le. les informations structurelles bidimensionnelles/tridimensionnelles contenues dans les graphiques moléculaires, les méthodes graphique à séquence (Graph2Seq) qui utilisent des graphiques moléculaires au lieu de SMILES comme entrée de modèle émergent progressivement dans ce domaine, ou les informations structurelles supplémentaires des graphiques moléculaires sont intégrées en séquences SMILES. Les deux méthodes peuvent faire bon usage des riches caractéristiques structurelles des graphes moléculaires
Sur cette base, cet article est basé sur la méthode émergente graphique-séquence et entraîne simultanément les tâches de rétrosynthèse et de prédiction de réaction directe sur le modèle original basé sur SMILES. Sur la base des références d'exploration pertinentes, nous explorons plus en détail la construction et les expériences de ce type de modèle à double tâche, et explorons et analysons également de manière préliminaire le déséquilibre de difficulté et les fluctuations du taux de correspondance Top-k affichés par le modèle au cours du processus de formation. ;Le modèle BiG2S construit sur cette base peut mieux gérer les tâches de rétrosynthèse et de prédiction de réaction directe dans les ensembles de données courants, et atteint des capacités de prédiction de réaction cohérentes avec d'autres modèles de rétrosynthèse sans modèle sans utiliser d'amélioration des données
Le cadre global doit être réécrit
La structure globale de BiG2S est un codeur-décodeur de bout en bout, comme le montre la figure 1. Le côté codeur utilise un réseau graphique local de transmission de messages dirigés et un transformateur graphique global qui intègre des informations de biais de structure graphique pour générer la représentation finale du nœud du graphique moléculaire. Le décodeur utilise un décodeur Transformer standard pour générer la séquence SMILES de la molécule cible de manière autorégressive. Il convient de noter que afin d'apprendre simultanément la rétrosynthèse et la prédiction de la réaction directe, l'entrée du décodeur contient en outre un double- séquences de chiffres sans ajouter d’informations de position. Dans le même temps, la couche de normalisation et la couche linéaire finale côté décodeur ont deux ensembles de paramètres, qui sont utilisés respectivement pour apprendre la tâche de rétrosynthèse et la tâche de prédiction de réaction directe
Figure 1 : Schéma du cadre global du BiG2SNécessite un cadre de formation à double tâche
La rétrosynthèse et la prédiction de la réaction directe sont deux tâches liées. La tâche de rétrosynthèse utilise des produits comme entrée et des réactifs comme sortie cible, tandis que la tâche de prédiction de la réaction directe fait le contraire. Il existe un lien étroit entre ces deux tâches, car elles peuvent être transformées en une tâche de prédiction de réaction directe en échangeant l'entrée et la sortie cible de la tâche de rétrosynthèse
Par conséquent, certains modèles sans modèle basés sur SMILES ont essayé de synthétiser et de transmettre la prédiction des réactions est utilisée comme objectif de formation pour améliorer la compréhension des réactions chimiques et obtenir certains résultats. Sur la base de cette idée, l'auteur a en outre tenté d'introduire une formation à double tâche dans le modèle graphe-séquence
Plus précisément, l'auteur s'est basé sur la stratégie de partage de paramètres précédemment utilisée sur d'autres méthodes, dans la couche de normalisation du décodeur et dans le couche linéaire finale Deux ensembles de paramètres spécifiques à la tâche sont construits. Dans d'autres modules, les deux types de tâches partagent un ensemble de paramètres. Dans le même temps, des étiquettes supplémentaires à double tâche sont ajoutées aux nœuds du graphique moléculaire d’entrée et à la séquence d’entrée initiale du décodeur. De cette façon, même en contrôlant la taille globale du modèle, le modèle est capable de distinguer les deux types de tâches et d'apprendre leurs différentes distributions de données. et analysé les deux types de problèmes du modèle reflétés dans le processus de formation
Tout d'abord, l'auteur a enregistré la fréquence d'apparition de différents caractères SMILES dans USPTO-50k et leur précision de prédiction correspondante pendant la formation, comme le montre la figure 2. Au cours du processus de formation, pour S et Br, qui représentaient respectivement 0,4 % et 0,3 % dans l'ensemble de formation, la différence absolue dans la précision globale de la prédiction a atteint 8 %. Cela montre initialement qu'il existe des différences évidentes dans la difficulté de prédiction entre les différentes structures/fragments moléculaires. Par conséquent, l'auteur atténue ces problèmes en introduisant une fonction de perte déséquilibrée (telle que la perte focale), afin que le modèle puisse accorder plus d'attention à la fonction de perte. précision pendant l'entraînement. Fragments moléculaires inférieurs
Figure 2 : Dans l'ensemble d'entraînement USPTO-50k, la fréquence d'apparition de différents caractères SMILES et leur précision globale de prédiction pendant l'entraînementDe plus, l'auteur a également enregistré la validation de le modèle pendant la formation La qualité des résultats de prédiction de l'ensemble change, comme le montre la figure 3. L'auteur a constaté qu'au milieu et à la fin des étapes de formation de l'ensemble de données USPTO-50k, la précision Top-1 du modèle sur l'ensemble de validation s'améliorait encore, mais il y avait une baisse de la qualité de prédiction du Top-3, Top-5. , et Top-10 Diminution significative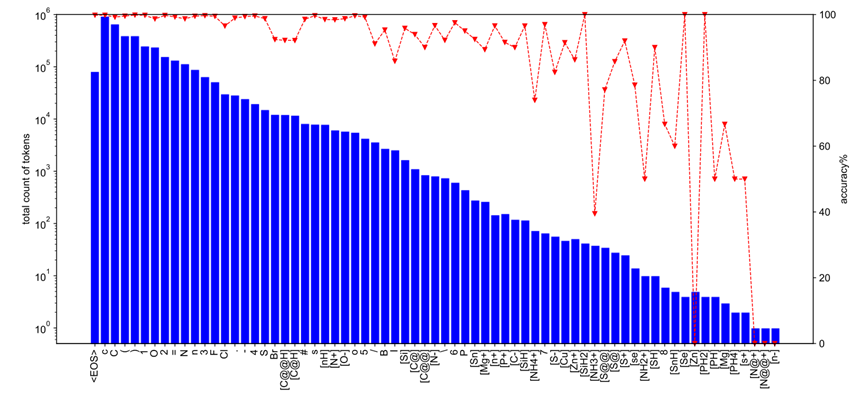 Afin d'améliorer la qualité de prédiction top 1 du modèle tout en maintenant la qualité globale des dix principaux résultats de génération de réactifs du modèle, nous avons en outre construit un type de stratégie d'intégration de modèle basée sur des indicateurs d'évaluation personnalisés . Plus précisément, nous construisons une file d'attente pour stocker les modèles et trions les modèles stockés selon des indicateurs d'évaluation prédéfinis (tels que la précision Top-1, la précision pondérée Top-k, etc.). Tout au long du processus de formation, nous stockons dynamiquement les modèles candidats et générons automatiquement des modèles d'ensemble basés sur les 3 à 5 premiers de la file d'attente, conservant ainsi les modèles Top-k avec la qualité de prédiction la plus élevée. Dans la phase d'inférence, nous avons également reconstruit la stratégie de recherche de faisceau basée sur le nouveau cadre et nous sommes davantage concentrés sur l'étendue de la recherche pour améliorer la qualité globale des résultats générés par le modèle Top-k
Afin d'améliorer la qualité de prédiction top 1 du modèle tout en maintenant la qualité globale des dix principaux résultats de génération de réactifs du modèle, nous avons en outre construit un type de stratégie d'intégration de modèle basée sur des indicateurs d'évaluation personnalisés . Plus précisément, nous construisons une file d'attente pour stocker les modèles et trions les modèles stockés selon des indicateurs d'évaluation prédéfinis (tels que la précision Top-1, la précision pondérée Top-k, etc.). Tout au long du processus de formation, nous stockons dynamiquement les modèles candidats et générons automatiquement des modèles d'ensemble basés sur les 3 à 5 premiers de la file d'attente, conservant ainsi les modèles Top-k avec la qualité de prédiction la plus élevée. Dans la phase d'inférence, nous avons également reconstruit la stratégie de recherche de faisceau basée sur le nouveau cadre et nous sommes davantage concentrés sur l'étendue de la recherche pour améliorer la qualité globale des résultats générés par le modèle Top-k
Nécessite un ensemble de données de référence dans une expérience à double tâche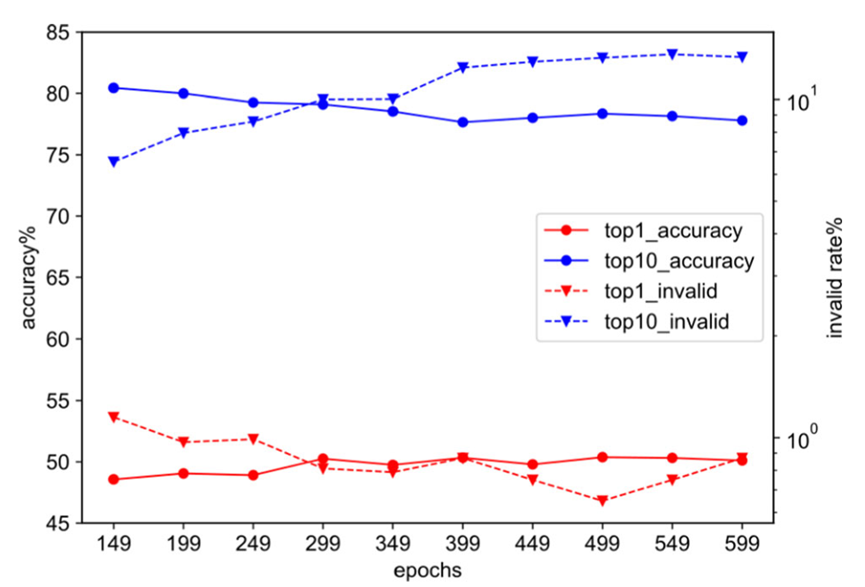
Dans l'ensemble de données à petite échelle, BiG2S a atteint une précision de prédiction de premier plan dans la tâche de rétrosynthèse basée sur un entraînement à deux tâches, tout en conservant une précision de prédiction de réaction directe élevée, mais elle était biaisée ; vers la réaction positive. Dans l'ensemble de données USPTO-MIT pour la prédiction de la réaction et l'ensemble de données à grande échelle USPTO-full, en raison de la limitation de la quantité globale de paramètres du modèle, les performances du modèle après un entraînement à double tâche ont diminué. Néanmoins, la capacité de traiter simultanément la tâche de rétrosynthèse et la tâche de prédiction de réaction directe a été obtenue à partir du modèle à double tâche avec presque le même nombre de paramètres et une légère réduction de la capacité de prédiction de réponse (la différence absolue de précision Top-k est d'environ 0,5 %). Du point de vue des capacités, le modèle BiG2S a atteint les objectifs attendus
Figure 4 : Résultats expérimentaux du modèle double tâche et du modèle monotâche de BiG2S sur trois ensembles de données de référence, où l'exposant b indique l'utilisation d'une tâche unique Le modèle effectue respectivement deux types de tâchesRéanalyser l'expérience d'ablation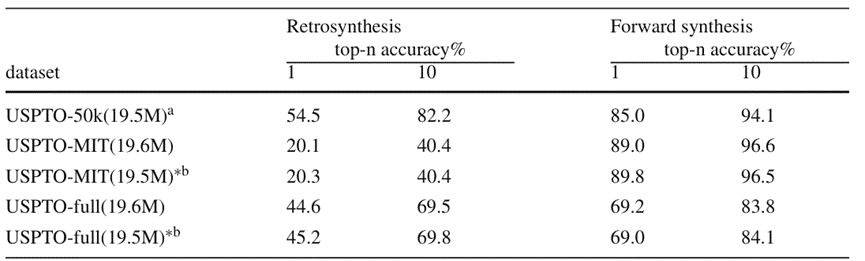
L'auteur a en outre vérifié le nouvel algorithme de recherche de faisceau et les hyperparamètres de température optimaux du BiG2S lors de la prévision dans différents ensembles de données après avoir utilisé la perte de déséquilibre grâce à des expériences d'ablation. L'hyperparamètre de température fait ici référence au paramètre de température T utilisé dans Softmax pour contrôler la distribution de probabilité de sortie. Les résultats expérimentaux sont présentés dans les figures 5 et 6.
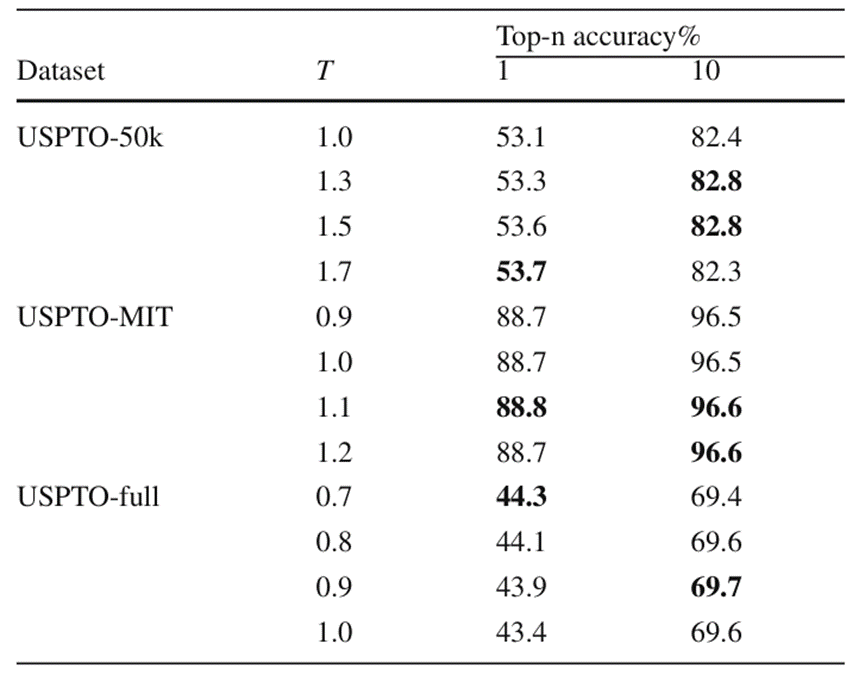
Dans l'expérience sur l'algorithme de recherche de faisceau, on peut observer qu'OpenNMT a étendu la largeur de recherche à 3 fois tandis que le temps de recherche n'a augmenté qu'à 1,74 fois, tandis que la nouvelle recherche de faisceau algorithme Lorsque la précision Top-1 est cohérente avec OpenNMT, le temps de recherche global augmente de 1 à 2 fois, mais en termes de qualité des résultats de prédiction Top-10, le nouvel algorithme de recherche de faisceau présente un avantage absolu en termes de précision d'au moins ; 3 % par rapport à OpenNMT En plus d'un avantage de rapport moléculaire effectif de 2 %, on peut dire que le nouvel algorithme de recherche de faisceaux a considérablement amélioré la qualité des résultats globaux de recherche Top-k du modèle au détriment du temps de recherche.
Lors de leurs expériences sur les hyperparamètres de température, les chercheurs ont découvert que l'utilisation de paramètres de température plus grands sur des ensembles de données à petite échelle pouvait améliorer considérablement la précision globale de la prédiction Top-k. Dans des ensembles de données plus grands, étant donné que la taille du modèle BiG2S ne peut pas s'adapter complètement à toutes les données de réaction, le choix de paramètres de température plus petits à ce moment-là aide souvent la recherche du modèle

La conclusion de l'étude montre...
Dans cet article, les auteurs proposent un modèle de prédiction de réaction sans modèle appelé BiG2S, qui peut gérer simultanément la tâche de rétrosynthèse et la tâche de prédiction de réponse directe . En adoptant une stratégie de partage de paramètres appropriée et des étiquettes supplémentaires à double tâche, BiG2S est capable d'effectuer des tâches de rétrosynthèse et des tâches de prédiction de réactions sur des ensembles de données de différentes tailles avec un plus petit nombre de paramètres, et sa capacité de prédiction globale est comparable aux modèles traditionnels
Pour résoudre les problèmes de difficulté de prédiction inégale de différents caractères SMILES et de fluctuations de la précision de prédiction Top-k pendant la formation du modèle, l'auteur a introduit la perte de déséquilibre, une stratégie d'intégration automatique du modèle basée sur des indicateurs d'évaluation personnalisés et un algorithme de recherche de faisceau basé sur un nouveau cadre pour atténuer ces problèmes.
BiG2S a montré de bonnes capacités de prédiction à double tâche sur trois ensembles de données grand public de différentes tailles, et d'autres expériences d'ablation ont également prouvé l'efficacité des stratégies de formation et d'inférence supplémentaires introduites
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!