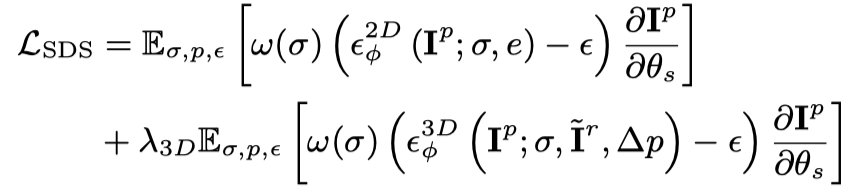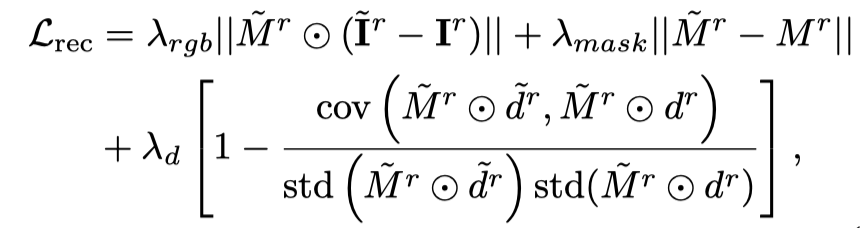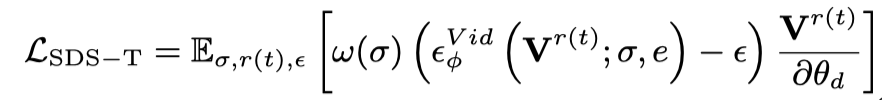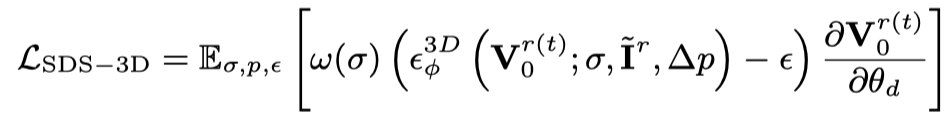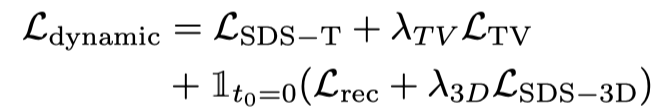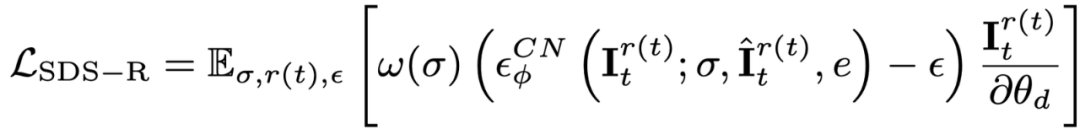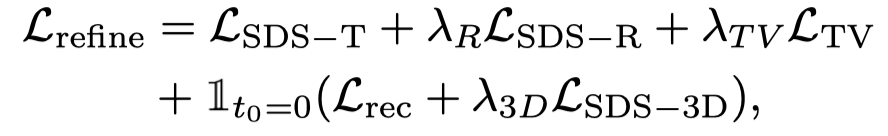Animate124, transformez facilement une seule image en vidéo 3D.
Au cours de la dernière année, DreamFusion a lancé une nouvelle tendance, à savoir la génération d'objets et de scènes statiques 3D, qui a attiré une large attention dans le domaine de la technologie de génération. En regardant l’année dernière, nous avons assisté à des progrès significatifs en matière de qualité et de contrôle de la technologie de génération statique 3D. Le développement technologique a commencé à partir de la génération basée sur du texte, progressivement intégré dans des images à vue unique, puis développé pour intégrer plusieurs signaux de contrôle. Par rapport à cela, la génération de scènes dynamiques 3D en est encore à ses balbutiements. Début 2023, Meta a lancé MAV3D, marquant la première tentative de génération de vidéos 3D basées sur du texte. Cependant, limités par le manque de modèles de génération vidéo open source, les progrès dans ce domaine ont été relativement lents. Cependant, désormais, une technologie de génération de vidéo 3D basée sur la combinaison de graphiques et de texte a été lancée ! Bien que la génération de vidéos 3D basée sur du texte soit capable de produire des contenus diversifiés, elle présente encore des limites dans le contrôle des détails et des poses des objets. Dans le domaine de la génération statique 3D, les objets 3D peuvent être reconstruits efficacement en utilisant une seule image comme entrée. Inspirée par cela, l'équipe de recherche de l'Université nationale de Singapour (NUS) et de Huawei a proposé le modèle Animate124. Ce modèle combine une seule image avec une description d'action correspondante pour permettre un contrôle précis de la génération vidéo 3D. 
- Page d'accueil du projet : https://animate124.github.io/
- Adresse papier : https://arxiv.org/abs/2311.14603
- Code : https://github. com/HeliosZhao/Animate124
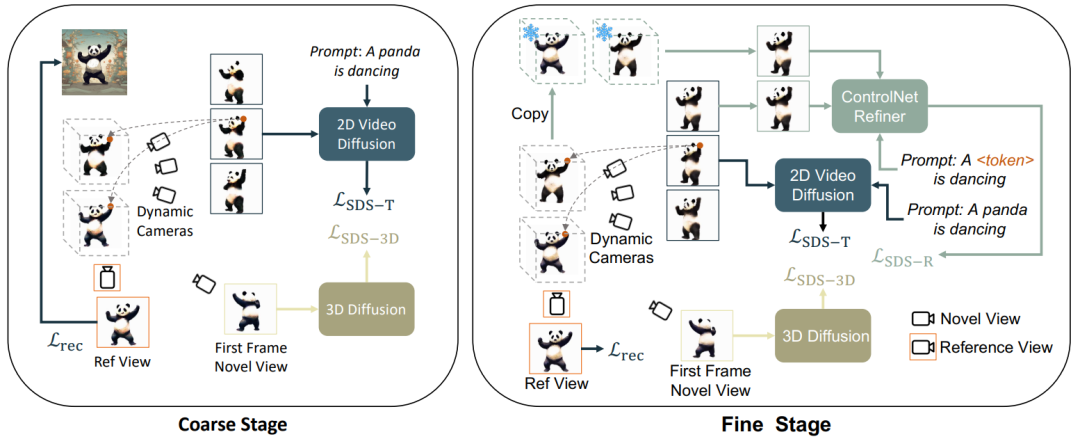
Selon l'optimisation statique et dynamique, grossière et fine, cet article divise Génération de vidéo 3D en 3 étapes : 1) Phase de génération statique : Utiliser le modèle de diffusion de graphes vincentiens et de graphes 3D pour générer des objets 3D à partir d'une seule image ; 2) Phase de génération brute dynamique : Utiliser le modèle vidéo vincentien pour optimiser les actions en fonction de la description du langage ; 3) Phase d'optimisation sémantique : De plus, le réglage personnalisé ControlNet est utilisé pour optimiser et améliorer l'écart provoqué par la description linguistique de deuxième étape sur l'apparence.
Pour la perspective correspondant à l'image conditionnelle, utilisez en plus la fonction de perte pour l'optimisation :
Grâce aux deux objectifs d'optimisation ci-dessus, plusieurs perspectives sont obtenues en 3D statique cohérente objets (cette étape est omise dans le diagramme de cadre).
Génération brute dynamiqueCette étape utilise principalement le
En utilisant uniquement Vincent vidéo La perte de distillation fera oublier au modèle 3D le contenu de l'image, et un échantillonnage aléatoire entraînera une formation insuffisante dans les étapes initiales et finales de la vidéo. Par conséquent, les chercheurs de cet article ont suréchantillonné les horodatages de début et de fin. Et, lors de l'échantillonnage de la trame initiale, des fonctions statiques supplémentaires sont utilisées pour l'optimisation (perte de distillation SDS des graphiques 3D) :
Par conséquent, la fonction de perte à ce stade est :
Même avec un suréchantillonnage de la trame initiale et une supervision supplémentaire sur celle-ci, pendant le processus d'optimisation utilisant le modèle de diffusion vidéo Vincent, l'objet l'apparence est toujours affectée par le texte, qui compense l'image de référence. Par conséquent, cet article propose une étape d’optimisation sémantique pour améliorer le décalage sémantique grâce à un modèle personnalisé. Comme il n'y a qu'une seule image, le modèle vidéo Vincent ne peut pas être personnalisé. Cet article présente un modèle de diffusion basé sur des images et du texte, et effectue un réglage personnalisé sur ce modèle de diffusion. Ce modèle de diffusion ne doit pas modifier le contenu et les actions de la vidéo originale, mais seulement en ajuster l'apparence. Par conséquent, cet article adopte le modèle graphique ControlNet-Tile, utilise les images vidéo générées à l'étape précédente comme conditions et optimise en fonction du langage. ControlNet est basé sur le modèle Stable Diffusion. Il lui suffit d'effectuer un réglage personnalisé (Textual Inversion) sur Stable Diffusion pour extraire les informations sémantiques dans l'image de référence. Après un réglage personnalisé, traitez la vidéo comme une image multi-images et utilisez ControlNet pour superviser une seule image :
De plus, comme ControlNet utilise des images brutes comme conditions, le guidage sans classificateur (CFG) peut utiliser le plage normale (10 à gauche et à droite) au lieu d'utiliser une valeur très grande (généralement 100) comme le graphique vincentien et les modèles vidéo vincentiens. Un CFG excessivement grand entraînera une sursaturation de l'image. Par conséquent, l'utilisation du modèle de diffusion ControlNet peut atténuer le phénomène de sursaturation et obtenir de meilleurs résultats de génération. La supervision de cette étape est combinée par la perte de scène dynamique et la supervision ControlNet :
En tant que premier modèle de génération vidéo 3D basé sur image-texte, cet article est comparé à deux références Les modèles et MAV3D ont été comparés. Animate124 a de meilleurs résultats par rapport aux autres méthodes. Comparaison des résultats visuels
Figure 2. Animate124 comparé à deux lignes de base
Figure 3.1 Comparer avec MAV. Vidéo 3D Vincent 3D
Figure 3.1. Comparaison des graphiques 3D Animate124 et MAV3D Comparaison des résultats quantitatifsCet article utilise CLIP et l'évaluation manuelle pour générer de la qualité. précision, similarité avec les images et cohérence temporelle. Les indicateurs d'évaluation manuelle incluent la similarité avec le texte, la similarité avec les images, la qualité de la vidéo, le réalisme des mouvements et l'amplitude des mouvements. L'évaluation manuelle est représentée par le rapport d'un seul modèle à la sélection d'Animate124 sur la métrique correspondante. Par rapport aux deux modèles de base, Animate124 obtient de meilleurs résultats en CLIP et en évaluation manuelle.
Tableau 1. Comparaison quantitative entre Animate124 et deux lignes de baseAnimate124 est le premier à transformer n'importe quelle image en 3 D basé sur la description textuelle Méthode vidéo. Il utilise plusieurs modèles de diffusion pour la supervision et le guidage, optimisant le réseau de représentation dynamique 4D pour générer des vidéos 3D de haute qualité. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!