
Maison >Périphériques technologiques >IA >Grand modèle + robot, un rapport d'examen détaillé est ici, avec la participation de nombreux chercheurs chinois
Grand modèle + robot, un rapport d'examen détaillé est ici, avec la participation de nombreux chercheurs chinois

- PHPzavant
- 2024-01-12 08:33:04730parcourir
Les capacités exceptionnelles des grands modèles sont évidentes pour tous, et s'ils sont intégrés dans des robots, on s'attend à ce que les robots aient un cerveau plus intelligent, apportant de nouvelles possibilités au domaine de la robotique, comme la conduite autonome, les robots domestiques, les robots industriels. robots, robots auxiliaires, robots médicaux, robots de terrain et systèmes multi-robots.
Le grand modèle de langage (LLM), le grand modèle de langage de vision (VLM), le grand modèle de langage audio (ALM) et le grand modèle de navigation visuelle (VNM) pré-entraînés peuvent être utilisés pour mieux gérer divers problèmes dans le domaine de la robotique. Tâche. L'intégration de modèles de base en robotique est un domaine en pleine croissance, et la communauté robotique a récemment commencé à explorer l'utilisation de ces grands modèles dans des domaines robotiques qui doivent être réécrits : la perception, la prédiction, la planification et le contrôle.
Récemment, une équipe de recherche conjointe composée de l'Université de Stanford, de l'Université de Princeton, de NVIDIA, de Google DeepMind et d'autres sociétés a publié un rapport d'analyse résumant le développement et les défis futurs des modèles de base dans le domaine de la recherche en robotique

Papier adresse : https://arxiv.org/pdf/2312.07843.pdf
Le contenu réécrit est : Bibliothèque papier : https://github.com/robotics-survey/Awesome-Robotics-Foundation -Models
Parmi les membres de l’équipe, nous connaissons de nombreux universitaires chinois, notamment Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu, etc.
Les modèles de base qui sont pré-entraînés de manière approfondie à l'aide de données à grande échelle peuvent être appliqués à diverses tâches en aval après un réglage fin. Ces modèles de base ont réalisé des avancées majeures dans les domaines de la vision et du traitement du langage, y compris des modèles associés tels que BERT, GPT-3, GPT-4, CLIP, DALL-E et PaLM-E
Avant l'émergence des modèles de base, pour les robots Les modèles traditionnels d'apprentissage en profondeur sont formés à l'aide d'ensembles de données limités collectés pour différentes tâches. En revanche, les modèles de base sont pré-entraînés à l'aide d'un large éventail de données diverses et ont démontré leur adaptabilité, leur généralisation et leurs performances globales dans d'autres domaines tels que le traitement du langage naturel, la vision par ordinateur et les soins de santé. A terme, le modèle de base devrait également montrer son potentiel dans le domaine de la robotique. La figure 1 montre un aperçu du modèle de base dans le domaine de la robotique.
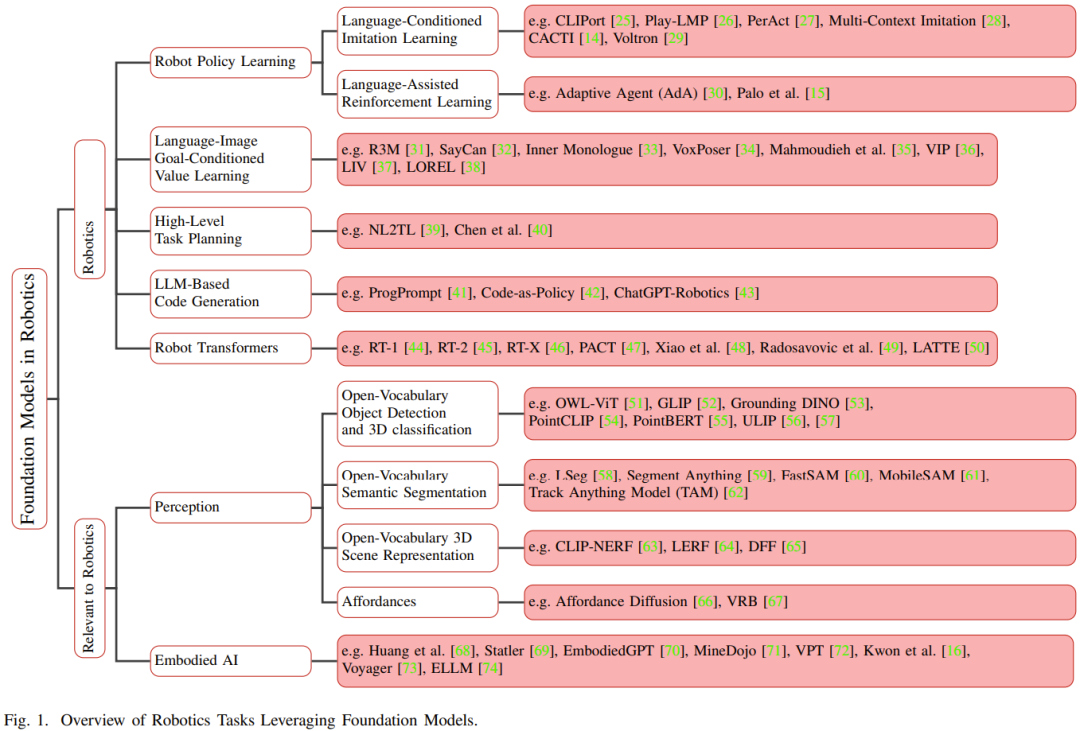
Par rapport aux modèles spécifiques à des tâches, le transfert de connaissances à partir de modèles de base a le potentiel de réduire le temps de formation et les ressources informatiques. En particulier dans les domaines liés à la robotique, les modèles de base multimodaux peuvent fusionner et aligner des données hétérogènes multimodales collectées à partir de différents capteurs en représentations homogènes compactes, nécessaires à la compréhension et au raisonnement des robots. Les représentations apprises peuvent être utilisées dans n’importe quelle partie de la pile technologique d’automatisation, y compris celles qui doivent être réécrites : perception, prise de décision et contrôle.
De plus, le modèle de base peut également fournir des capacités d'apprentissage sans tir, ce qui permet au système d'IA d'effectuer des tâches sans aucun exemple ni formation ciblée. Cela permet au robot de généraliser les connaissances acquises à de nouveaux cas d'utilisation, améliorant ainsi son adaptabilité et sa flexibilité dans des environnements non structurés.
L'intégration du modèle de base dans le système robotique peut améliorer la capacité du robot à percevoir l'environnement et à interagir avec l'environnement. Il est possible de réaliser le contexte qui doit être réécrit : le système robotique perceptuel.
Par exemple, ce qui doit être réécrit est : dans le domaine de la perception, les modèles de langage visuel (VLM) à grande échelle peuvent apprendre l'association entre les données visuelles et textuelles, afin d'avoir des capacités de compréhension multimodale, aidant ainsi classification d'images sans prise de vue, tâches telles que la détection d'objets sans échantillon et la classification 3D. Comme autre exemple, l'ancrage du langage (c'est-à-dire l'alignement de la compréhension contextuelle du VLM avec le monde réel 3D) dans le monde 3D peut améliorer les besoins spatiaux du robot en associant des énoncés à des objets, des emplacements ou des actions spécifiques dans l'environnement 3D. Réécrit : capacité de perception. .
Dans le domaine de la prise de décision ou de la planification, des recherches ont montré que LLM et VLM peuvent aider les robots à spécifier des tâches impliquant une planification de haut niveau.
En tirant parti des indices linguistiques liés au fonctionnement, à la navigation et à l'interaction, les robots peuvent effectuer des tâches plus complexes. Par exemple, pour les technologies robotiques d’apprentissage des politiques telles que l’apprentissage par imitation et l’apprentissage par renforcement, le modèle de base semble avoir la capacité d’améliorer l’efficacité des données et la compréhension du contexte. En particulier, les récompenses basées sur le langage peuvent guider les agents d’apprentissage par renforcement en leur fournissant des récompenses structurées.
De plus, les chercheurs utilisent déjà des modèles linguistiques pour fournir des commentaires sur la technologie d'apprentissage des politiques. Certaines études ont montré que les capacités de réponse visuelle aux questions (VQA) des modèles VLM peuvent être utilisées pour des cas d'utilisation de la robotique. Par exemple, les chercheurs ont utilisé VLM pour répondre à des questions liées au contenu visuel afin d'aider les robots à accomplir des tâches. De plus, certains chercheurs utilisent VLM pour faciliter l'annotation des données et générer des étiquettes de description pour le contenu visuel.
Bien que le modèle de base ait des capacités de transformation en termes de vision et de traitement du langage, la généralisation et l'ajustement du modèle de base pour les tâches robotiques du monde réel restent assez difficiles.
Ces défis incluent :
1) Manque de données : comment obtenir des données à l'échelle d'Internet pour prendre en charge des tâches telles que le fonctionnement, le positionnement et la navigation du robot, et comment utiliser ces données pour une formation auto-supervisée
2) D'énormes différences : comment gérer la grande diversité d'environnements physiques, de plates-formes physiques de robots et de tâches robotiques potentielles, tout en conservant la généralité requise du modèle sous-jacent
3) Le problème de la quantification de l'incertitude : comment résoudre l'incertitude au niveau de l'instance ; (comme l'ambiguïté du langage ou l'illusion LLM), l'incertitude au niveau de la distribution et les problèmes de changement de distribution, en particulier le problème de changement de distribution causé par le déploiement de robots en boucle fermée.
4) Évaluation de la sécurité : Comment tester rigoureusement le système robot basé sur le modèle de base avant le déploiement, pendant le processus de mise à jour et pendant le processus de travail.
5) Performances en temps réel : Comment gérer le long temps d'inférence de certains modèles de base - qui entravera le déploiement de modèles de base sur les robots, et comment accélérer l'inférence de modèles de base - nécessaire à la décision en ligne - fabrication.
Cet article de synthèse résume l'utilisation actuelle des modèles de base dans le domaine de la robotique. Les chercheurs examinent les méthodes, applications et défis actuels et proposent de futures orientations de recherche pour relever ces défis. Ils ont également souligné les risques potentiels liés à l'utilisation du modèle de base pour atteindre l'autonomie du robot
Connaissance de base du modèle
Le modèle de base comporte des milliards de paramètres et est pré-entraîné à l'aide de données à grande échelle au niveau Internet. La formation d’un modèle aussi vaste et complexe coûte très cher. Les coûts d’acquisition, de traitement et de gestion des données peuvent également être élevés. Son processus de formation nécessite une grande quantité de ressources informatiques, nécessite l'utilisation de matériel dédié tel que GPU ou TPU, ainsi que des logiciels et une infrastructure pour la formation des modèles, qui nécessitent tous un investissement financier. De plus, le temps de formation du modèle de base est également très long, ce qui entraîne également des coûts élevés. Par conséquent, ces modèles sont souvent utilisés comme modules enfichables, c'est-à-dire intégrant le modèle de base dans diverses applications sans travail de personnalisation approfondi
Le Tableau 1 donne les détails des modèles de base couramment utilisés.
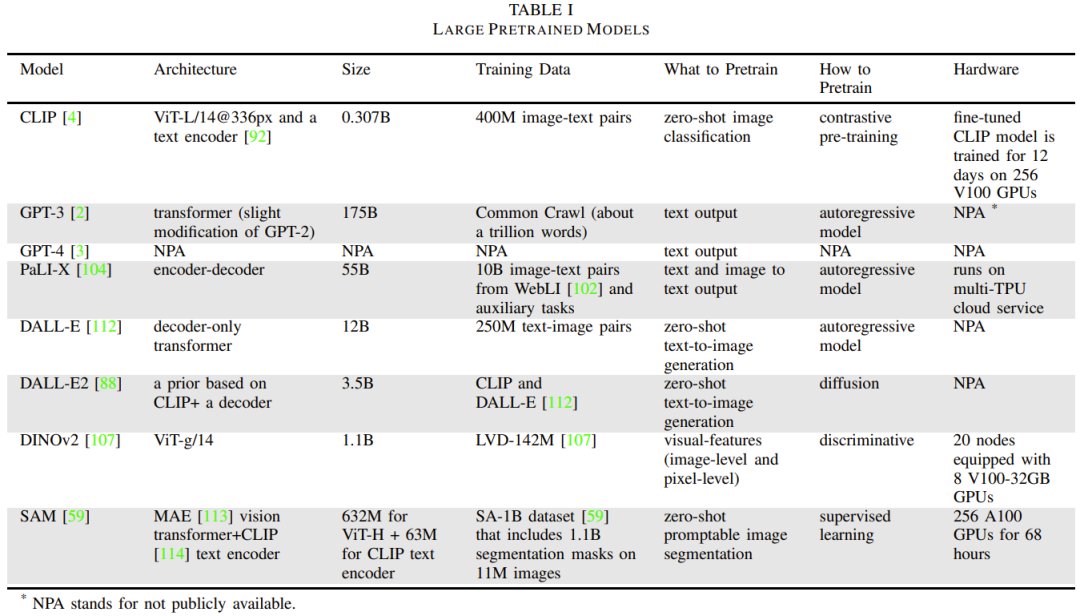
Cette section se concentrera sur le LLM, le transformateur visuel, le VLM, le modèle de langage multimodal incarné et le modèle génératif visuel. De plus, différentes méthodes de formation utilisées pour former le modèle de base seront également présentées
Ils introduisent d'abord une terminologie et des connaissances mathématiques connexes, qui impliquent la tokenisation, les modèles génératifs, les modèles discriminatifs, l'architecture du transformateur, les modèles autorégressifs, l'encodage automatique masqué, l'apprentissage contrastif. , et les modèles de diffusion.
Ensuite, ils présentent des exemples et le contexte historique des grands modèles linguistiques (LLM). Ensuite, le transformateur visuel, le modèle de langage de vision multimodal (VLM), le modèle de langage multimodal incarné et le modèle de génération visuelle ont été mis en évidence.
Robot Research
Cette section se concentre sur la prise de décision, la planification et le contrôle des robots. Dans ce domaine, les grands modèles de langage (LLM) et les modèles de langage visuel (VLM) peuvent potentiellement être utilisés pour améliorer les capacités des robots. Par exemple, LLM peut faciliter le processus de spécification des tâches afin que les robots puissent recevoir et interpréter des instructions de haut niveau provenant des humains.
VLM devrait également contribuer à ce domaine. VLM excelle dans l'analyse des données visuelles. Pour que les robots puissent prendre des décisions éclairées et effectuer des tâches complexes, la compréhension visuelle est cruciale. Désormais, les robots peuvent utiliser des indices du langage naturel pour améliorer leur capacité à effectuer des tâches liées à la manipulation, à la navigation et à l’interaction.
L'apprentissage des politiques visuo-linguistiques basé sur des objectifs (que ce soit par l'apprentissage par imitation ou par renforcement) devrait être amélioré par le modèle de base. Les modèles linguistiques peuvent également fournir des informations sur les techniques d’apprentissage des politiques. Cette boucle de rétroaction permet d'améliorer continuellement les capacités de prise de décision du robot, car celui-ci peut optimiser ses actions en fonction des commentaires qu'il reçoit du LLM.
Cette section se concentre sur l'application du LLM et du VLM dans le domaine de la prise de décision robotique.
Cette section est divisée en six parties. La première partie présente l'apprentissage politique pour la prise de décision, le contrôle et les robots, y compris l'apprentissage par imitation basé sur le langage et l'apprentissage par renforcement assisté par le langage.
La deuxième partie est l'apprentissage de la valeur de l'image et du langage basé sur des objectifs.
La troisième partie présente l'utilisation de grands modèles de langage pour planifier les tâches des robots, ce qui inclut l'explication des tâches à l'aide d'instructions linguistiques et l'utilisation de modèles de langage pour générer du code pour la planification des tâches.
La quatrième partie est l'apprentissage contextuel (ICL) pour la prise de décision.
Le prochain à présenter est Robot Transformers
La sixième partie est la navigation du robot et le fonctionnement de la bibliothèque de vocabulaire ouverte.
Le tableau 2 donne quelques modèles de base spécifiques aux robots, signalant la taille et l'architecture du modèle, les tâches de pré-formation, le temps d'inférence et la configuration matérielle.
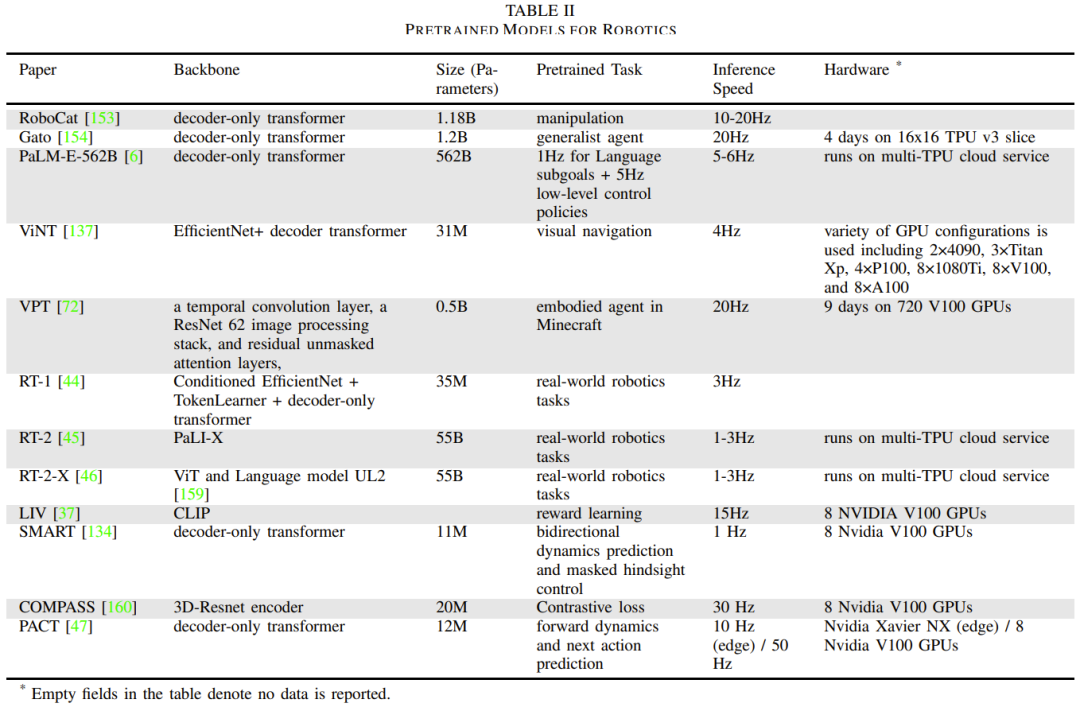
Ce qu'il faut réécrire c'est : la perception
Les robots qui interagissent avec l'environnement reçoivent des informations sensorielles sous différentes modalités, telles que des images, des vidéos, de l'audio et du langage. Ces données de grande dimension sont essentielles pour que les robots comprennent, raisonnent et interagissent dans leur environnement. Les modèles de base peuvent transformer ces entrées de grande dimension en représentations structurées abstraites faciles à interpréter et à manipuler. En particulier, les modèles de base multimodaux permettent aux robots d'intégrer les entrées de différents sens dans une représentation unifiée contenant des informations sémantiques, spatiales, temporelles et d'accessibilité. Ces modèles multimodaux nécessitent des interactions multimodales, nécessitant souvent l'alignement d'éléments de différentes modalités pour garantir la cohérence et la correspondance mutuelle. Par exemple, les tâches de description d'image nécessitent l'alignement des données de texte et d'image.
Cette section se concentrera sur ce que les robots doivent réécrire : une série de tâches liées à la perception, qui peuvent être améliorées en utilisant des modèles de base pour aligner les modalités. L'accent est mis sur la vision et le langage.
Cette section est divisée en cinq parties, la première est la détection de cible et la classification 3D du vocabulaire ouvert, puis la segmentation sémantique du vocabulaire ouvert, puis la scène 3D et la représentation cible du vocabulaire ouvert, et enfin la les moyens appris et enfin les modèles prédictifs.
IA incarnée
Récemment, certaines études ont montré que le LLM peut être utilisé avec succès dans le domaine de l'IA incarnée, où « incarné » fait généralement référence à l'incarnation virtuelle dans le simulateur mondial, plutôt qu'au corps physique du robot.
Des cadres, ensembles de données et modèles intéressants ont émergé dans ce domaine. Il convient de noter en particulier l'utilisation du jeu Minecraft comme plate-forme de formation d'agents incarnés. Par exemple, Voyager utilise GPT-4 pour guider les agents explorant les environnements Minecraft. Il peut interagir avec GPT-4 via une conception d'invite contextuelle sans qu'il soit nécessaire d'affiner les paramètres du modèle de GPT-4.
L'apprentissage par renforcement est une direction de recherche importante dans le domaine de l'apprentissage des robots. Les chercheurs tentent d'utiliser des modèles de base pour concevoir des fonctions de récompense afin d'optimiser l'apprentissage par renforcement
Pour que les robots effectuent une planification de haut niveau, les chercheurs ont exploré l'utilisation de bases. modèles pour vous aider. De plus, certains chercheurs tentent d'appliquer des méthodes de raisonnement et de génération d'actions basées sur une chaîne de pensée à l'intelligence incarnée
Défis et orientations futures
Cette section présentera les défis liés à l'utilisation du modèle de base pour les robots. L’équipe explorera également les futures orientations de recherche susceptibles de relever ces défis.
Le premier défi consiste à surmonter le problème de rareté des données lors de la formation de modèles de base pour les robots, ce qui comprend :
1. Étendre l'apprentissage des robots à l'aide de données de jeu non structurées et de vidéos humaines non étiquetées
2. Utiliser l'inpainting d'images (Inpainting) pour améliorer les données.
3. Surmontez le problème du manque de données 3D lors de la formation de modèles de base 3D
4. Générez des données synthétiques grâce à une simulation haute fidélité
5. Utiliser VLM pour l'augmentation des données est une méthode efficace
6. Les compétences physiques du robot sont limitées par la répartition des compétences
Le deuxième défi est lié aux performances en temps réel, où la clé est le temps d'inférence du modèle de base. .
Le troisième défi concerne les limites de la représentation multimodale.
Le quatrième défi est de savoir comment quantifier l'incertitude à différents niveaux, tels que le niveau de l'instance et le niveau de distribution. Cela implique également le problème de savoir comment calibrer et gérer les changements de distribution.
Le cinquième défi concerne l'évaluation de la sécurité, y compris les tests de sécurité avant le déploiement, la surveillance de l'exécution et la détection des situations de non-distribution.
Le sixième défi consiste à savoir comment choisir : utiliser un modèle de base existant ou construire un nouveau modèle de base pour le robot ?
Le septième défi implique une grande variabilité dans la configuration du robot.
Le huitième défi est de savoir comment évaluer et garantir la reproductibilité dans un environnement robot.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Dans quels aspects un robot est-il une application des ordinateurs ?
- En se concentrant sur l'écosystème commercial numérique et l'industrie des métaverses, Lujiazui Digital Intelligence World s'efforce de créer un cluster industriel d'éléments de données.
- Les fonctions du grand modèle d'IA auto-développé par Vivo ont été exposées, donnant à Huawei une longueur d'avance sur le lancement du grand modèle Pangu ?
- Le premier Forum du Sommet sur le développement collaboratif de la chaîne industrielle des robots du delta du fleuve Yangtze 2023 s'est tenu avec succès à Wuhu, Anhui.
- Le Forum général de développement de l'industrie des grands modèles d'intelligence artificielle et la cérémonie de dévoilement de la zone du cluster industriel des grands modèles d'intelligence artificielle générale dans le district de Shijingshan se sont déroulés avec succès.