
Maison >Tutoriel système >Linux >Comment fonctionne le pool de threads Java
Comment fonctionne le pool de threads Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-12 08:18:051112parcourir
| Présentation | Le concept de « pool » n'est pas rare dans notre développement. Il existe des pools de connexions à des bases de données, des pools de threads, des pools d'objets, des pools de constantes, etc. Ci-dessous, nous nous concentrons principalement sur le pool de threads pour découvrir étape par étape le voile du pool de threads. |
1. Réduire la consommation de ressources
Vous pouvez réutiliser les threads créés pour réduire la consommation causée par la création et la destruction des threads.
2. Améliorer la vitesse de réponse
Lorsqu'une tâche arrive, la tâche peut être exécutée immédiatement sans attendre la création du fil de discussion.
3. Améliorer la gestion des threads
Les threads sont des ressources rares. S'ils sont créés sans restrictions, ils consommeront non seulement des ressources système, mais réduiront également la stabilité du système. Utilisez le pool de threads pour une allocation, un réglage et une surveillance unifiés
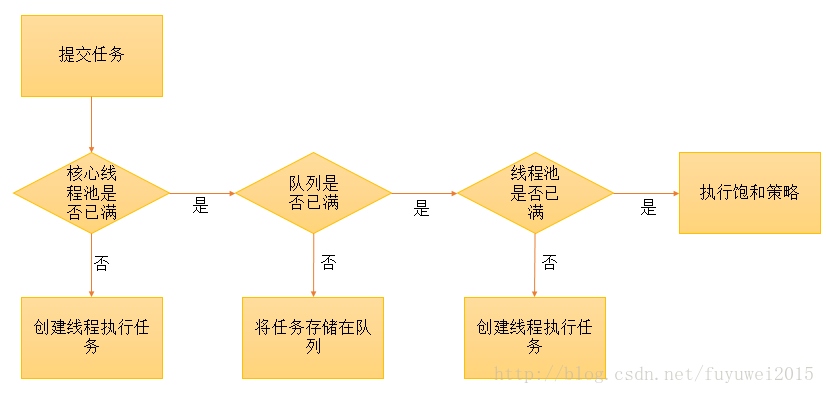
. Comment fonctionne le pool de threadsTout d’abord, examinons comment le pool de threads gère une nouvelle tâche après qu’elle ait été soumise au pool de threads
1. Le pool de threads détermine si tous les threads du pool de threads principal exécutent des tâches. Dans le cas contraire, un nouveau thread de travail est créé pour effectuer la tâche. Si tous les threads du pool de threads principal exécutent des tâches, effectuez la deuxième étape.
2. Le pool de threads détermine si la file d'attente de travail est pleine. Si la file d'attente de travail n'est pas pleine, les tâches nouvellement soumises sont stockées dans cette file d'attente de travail et attendues. Si la file d'attente est pleine, passez à l'étape 3
3. Le pool de threads détermine si tous les threads du pool de threads sont en état de fonctionnement. Dans le cas contraire, un nouveau thread de travail est créé pour effectuer la tâche. S'il est plein, confiez-le à la stratégie de saturation pour gérer cette tâche
Stratégie de saturation du pool de threadsLa stratégie de saturation du pool de threads est mentionnée ici, présentons donc brièvement les stratégies de saturation :
Politique d'abandon
C'est la stratégie de blocage par défaut du pool de threads Java. Il n'effectue pas cette tâche et lève directement une exception d'exécution. N'oubliez pas que ThreadPoolExecutor.execute nécessite un try catch, sinon le programme se fermera directement.
Politique de rejet
Abandonnez-le directement, la tâche n'est pas exécutée et la méthode est vide
Rejeter la politique la plus ancienne
Rejetez une tâche de tête de la file d'attente et exécutez à nouveau cette tâche.
CallerRunsPolicy
L'exécution de cette commande dans le thread qui appelle exécuter bloquera l'entrée
Politique de rejet définie par l'utilisateur (la plus couramment utilisée)
Implémentez RejectedExecutionHandler et définissez vous-même le modèle de stratégie
Prenons ThreadPoolExecutor comme exemple pour montrer le diagramme de flux de travail du pool de threads
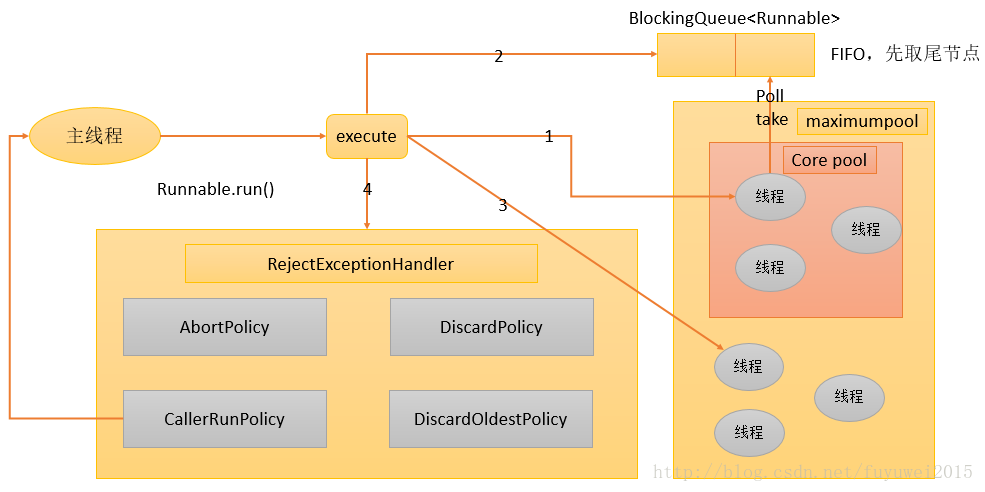
1. Si le nombre de threads en cours d'exécution est inférieur à corePoolSize, créez un nouveau thread pour effectuer la tâche (notez que vous devez obtenir un verrou global pour effectuer cette étape).
2. Si les threads en cours d'exécution sont égaux ou supérieurs à corePoolSize, ajoutez la tâche à BlockingQueue.
3. Si la tâche ne peut pas être ajoutée à BlockingQueue (la file d'attente est pleine), créez un nouveau thread dans un non-corePool pour traiter la tâche (notez que vous devez obtenir un verrou global pour effectuer cette étape).
4. Si la création d'un nouveau thread entraîne un dépassement du thread en cours d'exécution maximumPoolSize, la tâche sera rejetée et la méthode RejectedExecutionHandler.rejectedExecution() sera appelée.
L'idée générale de conception de ThreadPoolExecutor en suivant les étapes ci-dessus est d'éviter autant que possible d'acquérir des verrous globaux lors de l'exécution de la méthode execute() (ce qui constituera un sérieux goulot d'étranglement en matière d'évolutivité). Une fois l'échauffement terminé de ThreadPoolExecutor (le nombre de threads en cours d'exécution est supérieur ou égal à corePoolSize), presque tous les appels de méthode execute() exécutent l'étape 2, et l'étape 2 ne nécessite pas l'acquisition d'un verrou global.
Analyse du code source de la méthode cléJetons un coup d'œil au code source de la méthode principale ajoutée à la méthode du pool de threads exécutée comme suit :
//
//Executes the given task sometime in the future. The task
//may execute in a new thread or in an existing pooled thread.
//
// If the task cannot be submitted for execution, either because this
// executor has been shutdown or because its capacity has been reached,
// the task is handled by the current {@code RejectedExecutionHandler}.
//
// @param command the task to execute
// @throws RejectedExecutionException at discretion of
// {@code RejectedExecutionHandler}, if the task
// cannot be accepted for execution
// @throws NullPointerException if {@code command} is null
//
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//
// Proceed in 3 steps:
//
// 1. If fewer than corePoolSize threads are running, try to
// start a new thread with the given command as its first
// task. The call to addWorker atomically checks runState and
// workerCount, and so prevents false alarms that would add
// threads when it shouldn't, by returning false.
// 翻译如下:
// 判断当前的线程数是否小于corePoolSize如果是,使用入参任务通过addWord方法创建一个新的线程,
// 如果能完成新线程创建exexute方法结束,成功提交任务
// 2. If a task can be successfully queued, then we still need
// to double-check whether we should have added a thread
// (because existing ones died since last checking) or that
// the pool shut down since entry into this method. So we
// recheck state and if necessary roll back the enqueuing if
// stopped, or start a new thread if there are none.
// 翻译如下:
// 在第一步没有完成任务提交;状态为运行并且能否成功加入任务到工作队列后,再进行一次check,如果状态
// 在任务加入队列后变为了非运行(有可能是在执行到这里线程池shutdown了),非运行状态下当然是需要
// reject;然后再判断当前线程数是否为0(有可能这个时候线程数变为了0),如是,新增一个线程;
// 3. If we cannot queue task, then we try to add a new
// thread. If it fails, we know we are shut down or saturated
// and so reject the task.
// 翻译如下:
// 如果不能加入任务到工作队列,将尝试使用任务新增一个线程,如果失败,则是线程池已经shutdown或者线程池
// 已经达到饱和状态,所以reject这个他任务
//
int c = ctl.get();
// 工作线程数小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 直接启动新线程,true表示会再次检查workerCount是否小于corePoolSize
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果工作线程数大于等于核心线程数
// 线程的的状态未RUNNING并且队列notfull
if (isRunning(c) && workQueue.offer(command)) {
// 再次检查线程的运行状态,如果不是RUNNING直接从队列中移除
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
// 移除成功,拒绝该非运行的任务
reject(command);
else if (workerCountOf(recheck) == 0)
// 防止了SHUTDOWN状态下没有活动线程了,但是队列里还有任务没执行这种特殊情况。
// 添加一个null任务是因为SHUTDOWN状态下,线程池不再接受新任务
addWorker(null, false);
}
// 如果队列满了或者是非运行的任务都拒绝执行
else if (!addWorker(command, false))
reject(command);
}
Continuons à voir comment addWorker est implémenté :
private boolean addWorker(Runnable firstTask, boolean core) {
// java标签
retry:
// 死循环
for (;;) {
int c = ctl.get();
// 获取当前线程状态
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 这个逻辑判断有点绕可以改成
// rs >= shutdown && (rs != shutdown || firstTask != null || workQueue.isEmpty())
// 逻辑判断成立可以分为以下几种情况均不接受新任务
// 1、rs > shutdown:--不接受新任务
// 2、rs >= shutdown && firstTask != null:--不接受新任务
// 3、rs >= shutdown && workQueue.isEmppty:--不接受新任务
// 逻辑判断不成立
// 1、rs==shutdown&&firstTask != null:此时不接受新任务,但是仍会执行队列中的任务
// 2、rs==shotdown&&firstTask == null:会执行addWork(null,false)
// 防止了SHUTDOWN状态下没有活动线程了,但是队列里还有任务没执行这种特殊情况。
// 添加一个null任务是因为SHUTDOWN状态下,线程池不再接受新任务
if (rs >= SHUTDOWN &&! (rs == SHUTDOWN && firstTask == null &&! workQueue.isEmpty()))
return false;
// 死循环
// 如果线程池状态为RUNNING并且队列中还有需要执行的任务
for (;;) {
// 获取线程池中线程数量
int wc = workerCountOf(c);
// 如果超出容量或者最大线程池容量不在接受新任务
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 线程安全增加工作线程数
if (compareAndIncrementWorkerCount(c))
// 跳出retry
break retry;
c = ctl.get(); // Re-read ctl
// 如果线程池状态发生变化,重新循环
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 走到这里说明工作线程数增加成功
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock;
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
int rs = runStateOf(c);
// RUNNING状态 || SHUTDONW状态下清理队列中剩余的任务
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 检查线程状态
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 将新启动的线程添加到线程池中
workers.add(w);
// 更新线程池线程数且不超过最大值
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 启动新添加的线程,这个线程首先执行firstTask,然后不停的从队列中取任务执行
if (workerAdded) {
//执行ThreadPoolExecutor的runWoker方法
t.start();
workerStarted = true;
}
}
} finally {
// 线程启动失败,则从wokers中移除w并递减wokerCount
if (! workerStarted)
// 递减wokerCount会触发tryTerminate方法
addWorkerFailed(w);
}
return workerStarted;
}
AddWorker est suivi de runWorker. Lorsqu'il est démarré pour la première fois, il exécutera la tâche firstTask transmise lors de l'initialisation ; puis il prendra la tâche de workQueue et l'exécutera si la file d'attente est vide, elle attendra. tant que keepAliveTime
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 允许中断
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 如果getTask返回null那么getTask中会将workerCount递减,如果异常了这个递减操作会在processWorkerExit中处理
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
Voyons comment getTask est exécuté
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
// 死循环
retry: for (;;) {
// 获取线程池状态
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 1.rs > SHUTDOWN 所以rs至少等于STOP,这时不再处理队列中的任务
// 2.rs = SHUTDOWN 所以rs>=STOP肯定不成立,这时还需要处理队列中的任务除非队列为空
// 这两种情况都会返回null让runWoker退出while循环也就是当前线程结束了,所以必须要decrement
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
// 递减workerCount值
decrementWorkerCount();
return null;
}
// 标记从队列中取任务时是否设置超时时间
boolean timed; // Are workers subject to culling?
// 1.RUNING状态
// 2.SHUTDOWN状态,但队列中还有任务需要执行
for (;;) {
int wc = workerCountOf(c);
// 1.core thread允许被超时,那么超过corePoolSize的的线程必定有超时
// 2.allowCoreThreadTimeOut == false && wc >
// corePoolSize时,一般都是这种情况,core thread即使空闲也不会被回收,只要超过的线程才会
timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 从addWorker可以看到一般wc不会大于maximumPoolSize,所以更关心后面半句的情形:
// 1. timedOut == false 第一次执行循环, 从队列中取出任务不为null方法返回 或者
// poll出异常了重试
// 2.timeOut == true && timed ==
// false:看后面的代码workerQueue.poll超时时timeOut才为true,
// 并且timed要为false,这两个条件相悖不可能同时成立(既然有超时那么timed肯定为true)
// 所以超时不会继续执行而是return null结束线程。
if (wc <= maximumPoolSize && !(timedOut && timed))
break;
// workerCount递减,结束当前thread
if (compareAndDecrementWorkerCount(c))
return null;
c = ctl.get(); // Re-read ctl
// 需要重新检查线程池状态,因为上述操作过程中线程池可能被SHUTDOWN
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
try {
// 1.以指定的超时时间从队列中取任务
// 2.core thread没有超时
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
timedOut = true;// 超时
} catch (InterruptedException retry) {
timedOut = false;// 线程被中断重试
}
}
}
Voyons comment fonctionne processWorkerExit
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 正常的话再runWorker的getTask方法workerCount已经被减一了
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 累加线程的completedTasks
completedTaskCount += w.completedTasks;
// 从线程池中移除超时或者出现异常的线程
workers.remove(w);
} finally {
mainLock.unlock();
}
// 尝试停止线程池
tryTerminate();
int c = ctl.get();
// runState为RUNNING或SHUTDOWN
if (runStateLessThan(c, STOP)) {
// 线程不是异常结束
if (!completedAbruptly) {
// 线程池最小空闲数,允许core thread超时就是0,否则就是corePoolSize
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果min == 0但是队列不为空要保证有1个线程来执行队列中的任务
if (min == 0 && !workQueue.isEmpty())
min = 1;
// 线程池还不为空那就不用担心了
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 1.线程异常退出
// 2.线程池为空,但是队列中还有任务没执行,看addWoker方法对这种情况的处理
addWorker(null, false);
}
}
essayezTerminate
La méthode processWorkerExit tentera d'appeler tryTerminate pour mettre fin au pool de threads. Cette méthode est exécutée après toute action susceptible de provoquer l'arrêt du pool de threads : comme la réduction du wokerCount ou la suppression de tâches de la file d'attente dans l'état SHUTDOWN.
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 以下状态直接返回:
// 1.线程池还处于RUNNING状态
// 2.SHUTDOWN状态但是任务队列非空
// 3.runState >= TIDYING 线程池已经停止了或在停止了
if (isRunning(c) || runStateAtLeast(c, TIDYING) || (runStateOf(c) == SHUTDOWN && !workQueue.isEmpty()))
return;
// 只能是以下情形会继续下面的逻辑:结束线程池。
// 1.SHUTDOWN状态,这时不再接受新任务而且任务队列也空了
// 2.STOP状态,当调用了shutdownNow方法
// workerCount不为0则还不能停止线程池,而且这时线程都处于空闲等待的状态
// 需要中断让线程“醒”过来,醒过来的线程才能继续处理shutdown的信号。
if (workerCountOf(c) != 0) { // Eligible to terminate
// runWoker方法中w.unlock就是为了可以被中断,getTask方法也处理了中断。
// ONLY_ONE:这里只需要中断1个线程去处理shutdown信号就可以了。
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 进入TIDYING状态
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 子类重载:一些资源清理工作
terminated();
} finally {
// TERMINATED状态
ctl.set(ctlOf(TERMINATED, 0));
// 继续awaitTermination
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}
La méthode d'arrêt définira runState sur SHUTDOWN et mettra fin à tous les threads inactifs. La méthode shutdownNow définit runState sur STOP. La différence avec la méthode shutdown est que cette méthode mettra fin à tous les threads. La principale différence est que shutdown appelle la méthode interrompuIdleWorkers, tandis que shutdownNow appelle en fait la méthode interrompuIfStarted de la classe Worker :
Leur mise en œuvre est la suivante :
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 线程池状态设为SHUTDOWN,如果已经至少是这个状态那么则直接返回
advanceRunState(SHUTDOWN);
// 注意这里是中断所有空闲的线程:runWorker中等待的线程被中断 → 进入processWorkerExit →
// tryTerminate方法中会保证队列中剩余的任务得到执行。
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// STOP状态:不再接受新任务且不再执行队列中的任务。
advanceRunState(STOP);
// 中断所有线程
interruptWorkers();
// 返回队列中还没有被执行的任务。
tasks = drainQueue();
}
finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
// w.tryLock能获取到锁,说明该线程没有在运行,因为runWorker中执行任务会先lock,
// 因此保证了中断的肯定是空闲的线程。
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
}
finally {
mainLock.unlock();
}
}
void interruptIfStarted() {
Thread t;
// 初始化时state == -1
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
Utilisation du pool de threads
Création d'un pool de threads
Nous pouvons créer un pool de threads via ThreadPoolExecutor
/**
* @param corePoolSize 线程池基本大小,核心线程池大小,活动线程小于corePoolSize则直接创建,大于等于则先加到workQueue中,
* 队列满了才创建新的线程。当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,
* 等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,
* 线程池会提前创建并启动所有基本线程。
* @param maximumPoolSize 最大线程数,超过就reject;线程池允许创建的最大线程数。如果队列满了,
* 并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务
* @param keepAliveTime
* 线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率
* @param unit 线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、
* 毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)
* @param workQueue 工作队列,线程池中的工作线程都是从这个工作队列源源不断的获取任务进行执行
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
// threadFactory用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
向线程池提交任务
可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例。
threadsPool.execute(new Runnable() {
@Override
public void run() {
}
});
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
Future<Object> future = executor.submit(harReturnValuetask);
try
{
Object s = future.get();
}catch(
InterruptedException e)
{
// 处理中断异常
}catch(
ExecutionException e)
{
// 处理无法执行任务异常
}finally
{
// 关闭线程池
executor.shutdown();
}
关闭线程池
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
合理的配置线程池要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
1、任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
2、任务的优先级:高、中和低。
3、任务的执行时间:长、中和短。
4、任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行
如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
Il est recommandé d'utiliser une file d'attente limitée. Les files d'attente limitées peuvent augmenter la stabilité et les capacités d'alerte précoce du système, et peuvent être plus grandes selon les besoins, par exemple plusieurs milliers. Parfois, la file d'attente et le pool de threads du pool de threads des tâches en arrière-plan de notre système sont pleins et des exceptions de tâches abandonnées sont constamment levées. Grâce à une enquête, il s'avère qu'il y a un problème avec la base de données, ce qui rend l'exécution de SQL très difficile. lent, car le pool de threads de la tâche en arrière-plan a Toutes les tâches nécessitent l'interrogation et l'insertion de données dans la base de données, de sorte que tous les threads de travail du pool de threads sont bloqués et les tâches sont en retard dans le pool de threads. Si nous le définissons sur une file d'attente illimitée à ce moment-là, il y aurait de plus en plus de files d'attente dans le pool de threads, ce qui pourrait remplir la mémoire, rendant l'ensemble du système indisponible, pas seulement les tâches en arrière-plan. Bien entendu, toutes les tâches de notre système sont déployées sur des serveurs distincts et nous utilisons des pools de threads de différentes tailles pour effectuer différents types de tâches, mais lorsque de tels problèmes surviennent, d'autres tâches seront également affectées.
Surveillance du pool de threadsSi le pool de threads est largement utilisé dans le système, il est nécessaire de surveiller le pool de threads afin que lorsqu'un problème survient, le problème puisse être rapidement localisé en fonction de l'utilisation du pool de threads. Il peut être surveillé via les paramètres fournis par le pool de threads. Lors de la surveillance du pool de threads, vous pouvez utiliser les attributs suivants
.- taskCount : le nombre de tâches que le pool de threads doit exécuter.
- completedTaskCount : nombre de tâches que le pool de threads a terminées pendant le fonctionnement, inférieur ou égal à taskCount.
- largestPoolSize : le plus grand nombre de threads jamais créés dans le pool de threads. Grâce à ces données, vous pouvez savoir si le pool de threads a déjà été plein. Si cette valeur est égale à la taille maximale du pool de threads, cela signifie que le pool de threads est plein.
- getPoolSize : le nombre de threads dans le pool de threads. Si le pool de threads n'est pas détruit, les threads du pool de threads ne seront pas automatiquement détruits, donc la taille ne fera qu'augmenter mais pas diminuer.
- getActiveCount : obtenez le nombre de threads actifs.
Surveillance en étendant le pool de threads. Vous pouvez personnaliser le pool de threads en héritant du pool de threads, en réécrivant les méthodes beforeExecute, afterExecute et terminated du pool de threads, ou vous pouvez exécuter du code pour la surveillance avant, après et avant la fermeture du pool de threads. Par exemple, surveillez le temps d'exécution moyen, le temps d'exécution maximum et le temps d'exécution minimum des tâches.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!