
Maison >Périphériques technologiques >IA >'Famous Scenes from Huaguo Mountain' a une version haute définition et NTU propose un cadre vidéo de super-résolution Upscale-A-Video
'Famous Scenes from Huaguo Mountain' a une version haute définition et NTU propose un cadre vidéo de super-résolution Upscale-A-Video

- 王林avant
- 2024-01-11 19:57:301180parcourir
Les modèles de diffusion ont obtenu un succès remarquable dans la génération d'images, mais leur application à la super-résolution vidéo reste encore difficile. La super-résolution vidéo nécessite une fidélité de sortie et une cohérence temporelle, ce qui est compliqué par la stochasticité inhérente aux modèles de diffusion. Par conséquent, appliquer efficacement des modèles de diffusion à la super-résolution vidéo reste une tâche difficile.
Une équipe de recherche du S-Lab de l'Université technologique de Nanyang a proposé un cadre de diffusion latente guidée par texte appelé Upscale-A-Video pour la super-résolution vidéo. Le cadre garantit la cohérence temporelle grâce à deux mécanismes clés. Premièrement, à l’échelle locale, il intègre des couches temporelles dans U-Net et VAE-Decoder pour maintenir la cohérence des séquences courtes. Deuxièmement, à l’échelle mondiale, le cadre introduit un module de propagation latente récurrente guidé par flux qui propage et fusionne les latents tout au long de la séquence sans formation, améliorant ainsi la stabilité globale de la vidéo. La proposition de ce framework fournit une nouvelle solution pour la super-résolution vidéo, avec une meilleure cohérence temporelle et stabilité globale.

Adresse papier : https://arxiv.org/abs/2312.06640
Upscale-A-Video gagne une grande flexibilité grâce au paradigme de diffusion. Il permet l'utilisation d'invites textuelles pour guider la création de textures, et les niveaux de bruit peuvent être ajustés pour équilibrer la fidélité et la qualité entre la récupération et la génération. Cette fonctionnalité permet à la technologie d'affiner les détails tout en conservant la signification du contenu original, ce qui donne des résultats plus précis.
Les résultats expérimentaux montrent qu'Upscale-A-Video surpasse les méthodes existantes sur les benchmarks synthétiques et réels, présentant un réalisme visuel et une cohérence temporelle impressionnants.
Jetons d'abord un coup d'œil à quelques exemples spécifiques. Par exemple, avec l'aide d'Upscale-A-Video, « Famous Scenes from Huaguo Mountain » a une version haute définition :

Par rapport à StableSR, Upscale. -A-Video fait la vidéo La texture des poils d'écureuil est clairement visible dans :

Introduction à la méthode
Certaines études optimisent les modèles de diffusion d'images pour s'adapter aux tâches vidéo en introduisant des stratégies de cohérence temporelle. Ces stratégies incluent les deux méthodes suivantes : premièrement, affiner les modèles vidéo via des couches temporelles, telles que la convolution 3D et l'attention temporelle, pour améliorer les performances de traitement vidéo. Deuxièmement, des mécanismes de tir zéro, tels que l'attention inter-images et l'attention guidée par le flux, sont utilisés pour ajuster le modèle pré-entraîné afin d'améliorer les performances des tâches vidéo. L'introduction de ces méthodes permet au modèle de diffusion d'images de mieux gérer les tâches vidéo, améliorant ainsi l'effet du traitement vidéo.
Bien que ces solutions améliorent considérablement la stabilité de la vidéo, deux problèmes majeurs subsistent :
Les méthodes actuelles fonctionnant dans les fonctionnalités U-Net ou les espaces latents ont du mal à maintenir une cohérence de bas niveau, et des problèmes tels que le scintillement des textures existent toujours.
Les couches temporelles et les mécanismes d'attention existants ne peuvent imposer des contraintes que sur de courtes séquences d'entrée locales, limitant leur capacité à assurer une cohérence temporelle globale dans des vidéos plus longues.
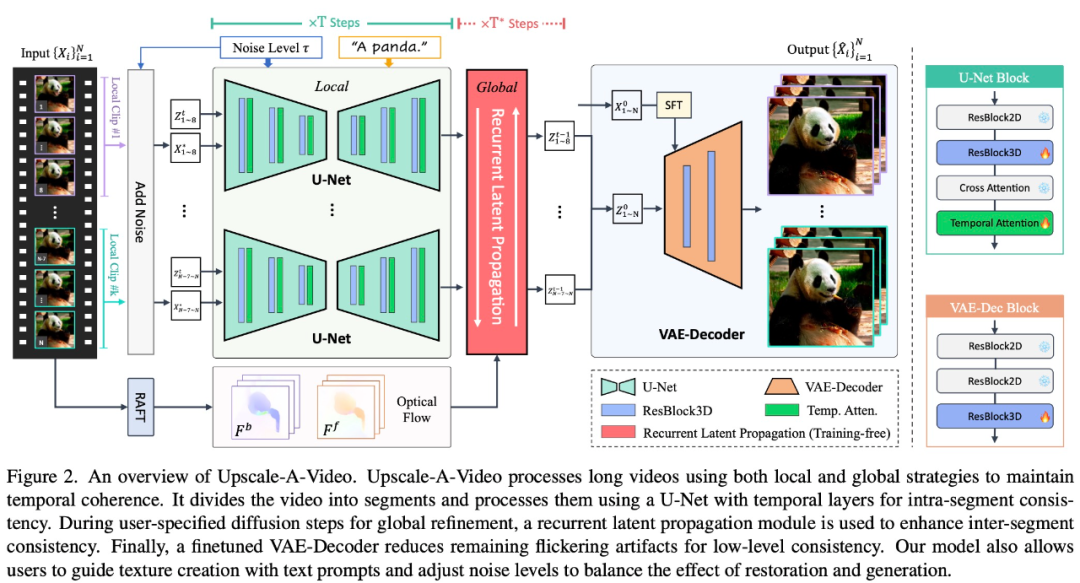
Pour résoudre ces problèmes, Upscale-A-Video adopte une stratégie locale-globale pour maintenir la cohérence temporelle dans la reconstruction vidéo, en se concentrant sur la texture fine et la cohérence globale. Sur des clips vidéo locaux, cette étude explore l'utilisation de couches temporelles supplémentaires sur les données vidéo pour affiner un modèle de super-résolution d'image ×4 pré-entraîné.
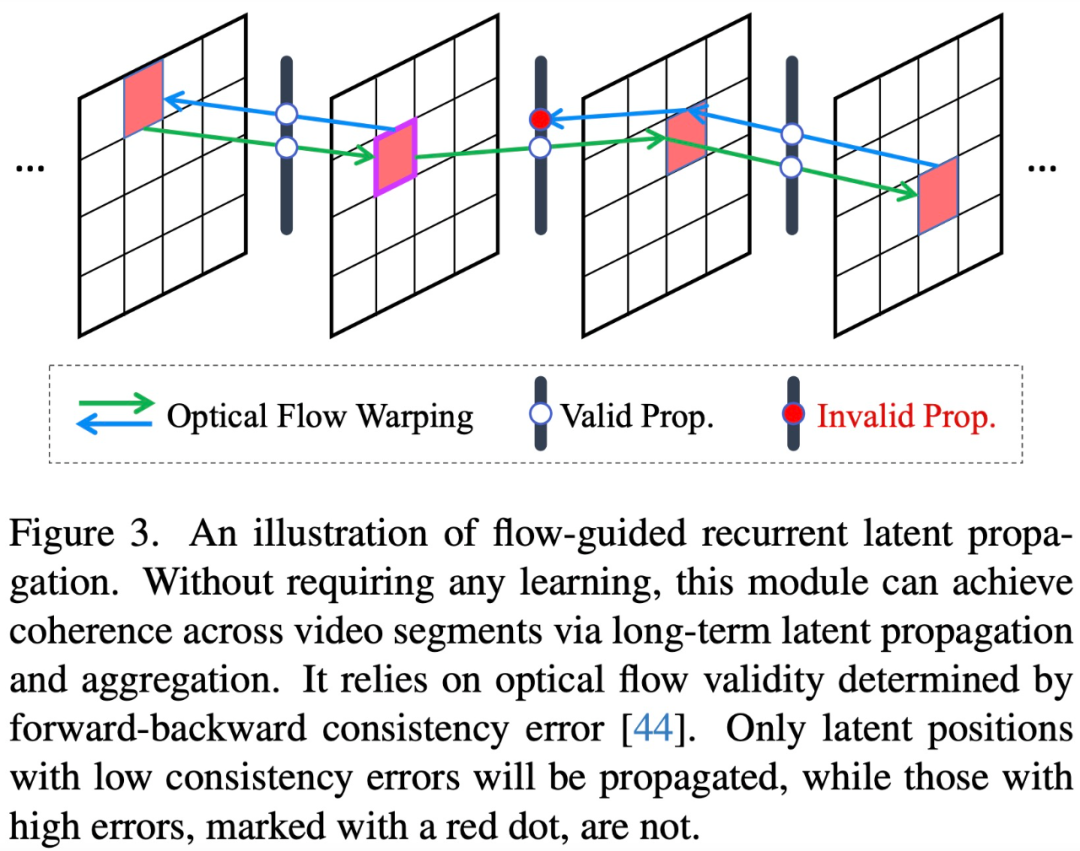
Plus précisément, dans le cadre de la diffusion latente, cette étude affine d'abord U-Net à l'aide de couches de convolution 3D et d'attention temporelle intégrées, puis utilise une entrée vidéo conditionnée et une convolution 3D pour régler le décodeur VAE. Le premier atteint de manière significative la stabilité structurelle des séquences locales, et le second améliore encore la cohérence de bas niveau et réduit le scintillement de la texture. À l'échelle mondiale, cette étude présente un nouveau module de propagation latente récurrente, guidé par flux, sans formation, qui effectue une propagation image par image et une fusion latente dans les deux sens pendant l'inférence, favorisant ainsi la stabilité globale des longues vidéos.
Le modèle Upscale-A-Video peut utiliser des invites textuelles comme conditions facultatives pour guider le modèle afin de produire des détails plus réalistes et de meilleure qualité, comme le montre la figure 1.

Upscale-A-Video divise la vidéo en segments et les traite à l'aide d'U-Net avec des couches temporelles pour obtenir une cohérence intra-segment. Un module de propagation latente récurrente est utilisé pour améliorer la cohérence inter-fragment lors de la diffusion de raffinement global spécifiée par l'utilisateur. Enfin, un décodeur VAE affiné réduit les artefacts de scintillement et atteint une cohérence de bas niveau.
Résultats expérimentaux
Upscale-A-Video atteint les performances SOTA sur les benchmarks existants, démontrant un excellent réalisme visuel et une cohérence temporelle.
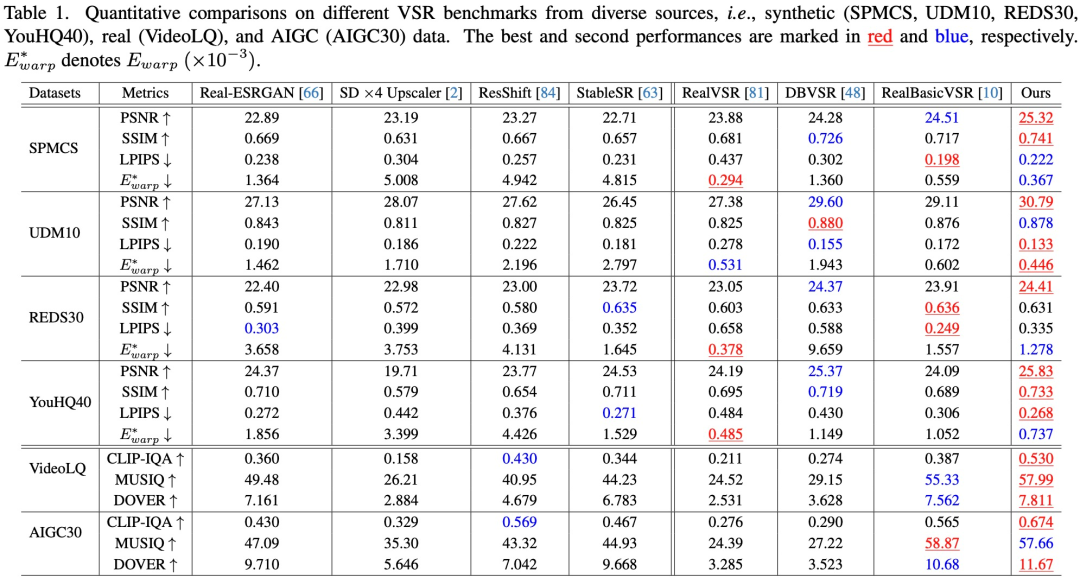
Évaluation quantitative. Comme le montre le tableau 1, Upscale-A-Video atteint le PSNR le plus élevé dans les quatre ensembles de données synthétiques, ce qui indique ses excellentes capacités de reconstruction.
Évaluation qualitative. L'étude montre les résultats visuels des vidéos synthétiques et réelles dans les figures 4 et 5 respectivement. Upscale-A-Video surpasse considérablement les méthodes CNN et de diffusion existantes en termes de suppression d'artefacts et de génération de détails.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Étapes détaillées pour créer un nouveau projet C++ complet dans VS2015
- Questions d'entretien d'ingénieur PHP senior Xiaomi 2022 (examen simulé)
- Quelles sont les exigences d'un bon ingénieur de développement front-end ?
- Que signifie ingénieur python full stack ?
- Que fait un ingénieur de développement Golang ?